Содержание
Как закрыть сайт от индексации в robots.txt
Время прочтения: 4 минуты
О чем статья?
- Каким страницам и сайтам не нужно индексирование
- Когда нужно скрыть весь сайт, а когда — только часть его
- Как выбирать теги, закрывающие индексацию
Кому полезна эта статья?
- Контент-редакторам
- Администраторам сайтов
- Владельцам сайтов
Итак, в то время как все ресурсы мира гонятся за вниманием поисковых роботов ради вхождения в ТОП, вы решили скрыться от индексирования. На самом деле для этого может быть масса объективных причин. Например, сайт в разработке или проводится редизайн интерфейса.
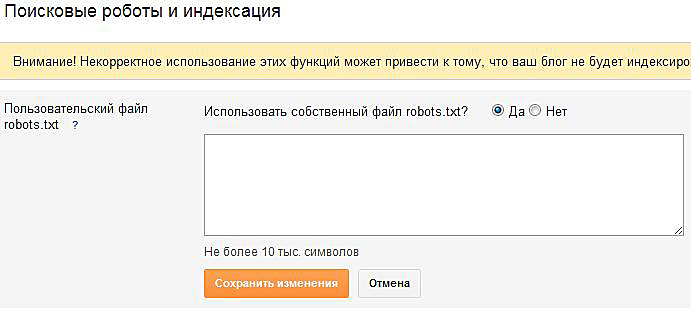
Обратите внимание: можно запретить индексирование сайта целиком или отдельных его блоков или страниц.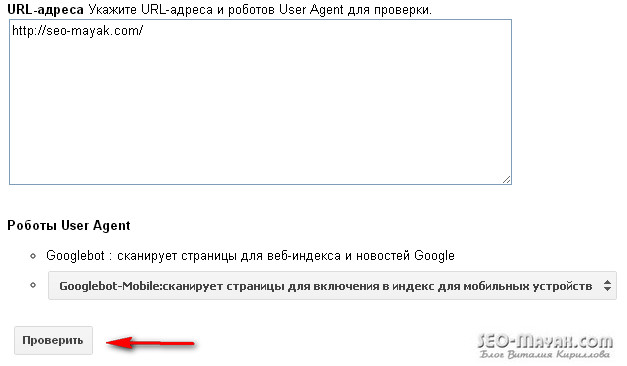 Для этого на помощь приходит служебный файл robots.txt.
Для этого на помощь приходит служебный файл robots.txt.
Когда закрывать сайт целиком, а когда — его отдельные части?
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Если ресурс имеет большое количество служебной информации, делайте закрытый портал или закрывайте страницы и целые разделы.
Желательно запрещать индексацию так называемых мусорных страниц. Это старые новости, события и мероприятия в календаре. Если у вас интернет-магазин, проверьте, чтобы в поиске не оказались устаревшие акции, скидки и информация о товарах, снятых с продажи. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Лучше скрыть также всплывающие окна и баннеры, скрипты, размещенные на сайте файлы, особенно если последние много весят. Это уменьшит время индексации в целом, что положительно воспринимается поиском, и снизит нагрузку на сервер.
Это уменьшит время индексации в целом, что положительно воспринимается поиском, и снизит нагрузку на сервер.
Как узнать, закрыт ресурс или нет?
Чтобы точно знать, идет ли индексация robots txt, сначала проверьте: возможно, закрытие сайта или отдельных страниц уже осуществлено? В этом помогут сервисы поисковиков Яндекс.Вебмастер и Google Search Console. Они покажут, какие url вашего сайта индексируются. Если сайт не добавлен в сервисы поисковиков, можно использовать бесплатный инструмент «Определение возраста документа в Яндексе» от Пиксел Тулс.
Закрываем сайт и его части: пошаговая инструкция.
- Для начала найдите в корневой папке сайта файл robots.txt. Для этого используйте поиск.
- Если ничего не нашли — создайте в Блокноте или другом текстовом редакторе документ с названием robots расширением .
 txt. Позже его надо будет загрузить в корневую папку сайта.
txt. Позже его надо будет загрузить в корневую папку сайта. - Теперь в этом файле HTML-тегами детально распишите, куда заходить роботу, а куда не стоит.
 txt. Позже его надо будет загрузить в корневую папку сайта.
txt. Позже его надо будет загрузить в корневую папку сайта.
Как полностью закрыть сайт в роботс?
Приведем пример закрытия сайта для основных роботов. Все вместе они обозначаются значком *.
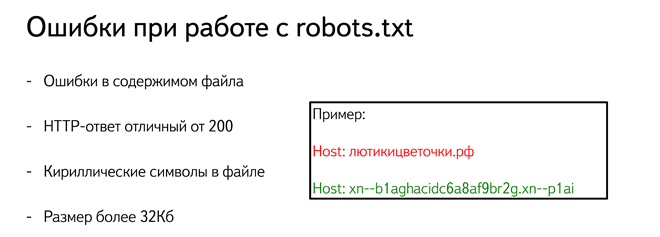
Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. При этом также указывайте запрет для индексации всем роботам или тем из них, кто ищет картинки, видео и т.п. Например, указание Яндексу не засылать к вам поиск картинок будет выглядеть как
Здесь YandexImages — название робота Яндекса, который ищет изображения. Полные списки роботов можно посмотреть в справке поисковых систем.
Как закрыть отдельные разделы/страницы или типы контента?
Выше мы показали, как запрещать основным или вспомогательным роботам заходить на сайт. Можно сделать немного по-другому: не искать имена роботов, отвечающих за поиск картинок, а запретить всем роботам искать на сайте определенный тип контента. В этом случае в директиве Disallow: / указываете либо тип файлов по модели *.расширениефайлов, либо относительный адрес страницы или раздела.
Можно сделать немного по-другому: не искать имена роботов, отвечающих за поиск картинок, а запретить всем роботам искать на сайте определенный тип контента. В этом случае в директиве Disallow: / указываете либо тип файлов по модели *.расширениефайлов, либо относительный адрес страницы или раздела.
Прячем ненужные ссылки
Иногда скрыть от индексирования нужно ссылку на странице. Для этого у вас есть два варианта.
- В HTML-коде самой этой страницы укажите метатег robots с директивой nofollow. Тогда поисковые роботы не будут переходить по ссылкам на странице, но на них может вести другой материал вашего или сторонних сайтов.
- В саму ссылку добавьте атрибут rel=»nofollow».
Данный атрибут рекомендует роботу не принимать ссылку во внимание. В этом случае запрет индексации работает и тогда, когда поисковая система находит ссылку не через страницу, где переход закрыт в HTML-коде.
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt являются теги, закрывающие индексации сайта или видов контента. Это мета-тег robots. Прописывайте его в исходный код сайта в файле index.html и размещайте в контейнере <head>.
Существуют два варианта записи мета-тега.
Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название: Googlebot, Яндекс.
Поле “content” из 1 варианта может иметь следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.

Таким образом, можно запретить индексацию содержимого сайта независимо от файла robots.txt при помощи content=”noindex, follow”. Или разрешить ее частично: например, вы хотите не индексировать текст, а ссылки — пожалуйста. Используйте для разных случаев сочетания значений.
Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические ошибки означают, что правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в панелях инструментах Яндекс.Вебмастер и Google, прежде чем загрузить его на сайт..
Синтаксические — неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.
Выводы
- Запрет на индексирование — весьма полезная возможность. Убирая служебные, повторяющиеся и устаревшие блоки на страницах, вы повысите уникальность контента и экспертность сайта.
- Для проверки того, какие страницы индексируются, проще всего использовать службы поисковиков, но можно воспользоваться сторонними сервисами.
- Вы можете использовать 2 варианта: закрытие страницы через файл robots.txt или же мета-тег robots в файле index.html. Оба файла находятся в корневом каталоге.
- Закрывая служебную информацию, устаревающие данные, скрипты, сессии и utm-метки, для каждого запрета создавайте отдельное правило в файле robots.txt или отдельный мета-тег.
- Разнообразие настроек позволяет точно отобрать и закрыть те части контента, которые, будучи в поиске, не ведут к конверсии, и при этом не могут быть удалены с сайта.
Материал подготовила Светлана Сирвида-Льорентэ.
Как закрыть сайт или его страницы от индексации: подробная инструкция
Что нужно закрывать от индексации
Важно, чтобы в поисковой выдаче были исключительно целевые страницы, соответствующие запросам пользователей. Поэтому от индексации в обязательном порядке нужно закрывать:
1. Бесполезные для посетителей страницы или контент, который не нужно индексировать. В зависимости от CMS, это могут быть:
- страницы административной части сайта;
- страницы с личной информацией пользователей, например, аккаунты в блогах и на форумах;
- дубли страниц;
- формы регистрации, заказа, страница корзины;
- страницы с неактуальной информацией;
- версии страниц для печати;
- RSS-лента;
- медиа-контент;
- страницы поиска и т. д.
 д.
д.
2. Страницы с нерелевантным контентом на сайте, который находится в процессе разработки.
3. Страницы с информацией, предназначенной для определенного круга лиц, например, корпоративные ресурсы для взаимодействий между сотрудниками одной компании.
4. Сайты-аффилиаты.
Если вы закроете эти страницы, процесс индексации других, наиболее важных для продвижения страниц сайта ускорится.
Способы закрытия сайта от индексации
Закрыть сайт или страницы сайта от поисковых краулеров можно следующими способами:
- С помощью файла robots.txt и специальных директив.
- Добавив метатеги в HTML-код отдельной страницы.
- С помощью специального кода, который нужно добавить в файл .htaccess.
- Воспользовавшись специальными плагинами (если сайт сделан на популярной CMS).
Далее рассмотрим каждый из этих способов.
С помощью robots.txt
Robots.txt — текстовый файл, который поисковые краулеры посещают в первую очередь. Здесь для них прописываются указания — так называемые директивы.
Этот файл должен соответствовать следующим требованиям:
- название файла прописано в нижнем регистре;
- он имеет формат .txt;
- его размер не превышает 500 КБ;
- находится в корне сайте;
- файл доступен по адресу URL сайта/robots.txt, а при его запросе сервер отправляет в ответ код 200 ОК.
В robots.txt прописываются такие директивы:
- User-agent. Показывает, для каких именно роботов предназначены директивы.
- Disallow. Указывает роботу на то, что некоторое действие (например, индексация) запрещено.
- Allow. Напротив, разрешает совершать действие.
- Sitemap. Указывает на прямой URL-адрес карты сайта.
- Clean-param. Помогает роботу Яндекса правильно определять страницу для индексации.

Имейте в виду: поскольку информация в файле robots.txt — это скорее указания или рекомендации, нежели строгие правила, некоторые системы могут их игнорировать. В таком случае в индекс попадут все страницы вашего сайта.
Полный запрет сайта на индексацию в robots.txt
Вы можете запретить индексировать сайт как всем роботам поисковой системы, так и отдельно взятым. Например, чтобы закрыть весь сайт от робота Яндекса, который сканирует изображения, нужно прописать в файле следующее:
User-agent: YandexImages Disallow: /
Чтобы закрыть для всех роботов:
User-agent: * Disallow: /
Чтобы закрыть для всех, кроме указанного:
User-agent: * Disallow: / User-agent: Yandex Allow: /
В данном случае, как видите, индексация доступна для роботов Яндекса.
Запрет на индексацию отдельных страниц и разделов сайта
Для запрета на индексацию одной страницы достаточно прописать ее URL-адрес (домен не указывается) в директиве файла:
User-agent: * Disallow: /registration.
 html
htmlЧтобы закрыть раздел или категорию:
User-agent: * Disallow: /category/
Чтобы закрыть все, кроме указанной категории:
User-agent: * Disallow: / Allow: /category
Чтобы закрыть все категории, кроме указанной подкатегории:
User-agent: * Disallow: /uslugi Allow: /uslugi/main
В качестве подкатегории здесь выступает «main».
Запрет на индексацию прочих данных
Чтобы скрыть директории, в файле нужно указать:
User-agent: * Disallow: /portfolio/
Чтобы скрыть всю директорию, за исключением указанного файла:
User-agent: * Disallow: /portfolio/ Allow: avatar.png
Чтобы скрыть UTM-метки:
User-agent: * Disallow: *utm=
Чтобы скрыть скриптовые файлы, нужно указать следующее:
User-agent: * Disallow: /scripts/*.ajax
По такому же принципу скрываются файлы определенного формата:
User-agent: * Disallow: /*.
Вместо .png подставьте любой другой формат.
Через HTML-код
Запретить индексировать страницу можно также с помощью метатегов в блоке <head> в HTML-коде.
Атрибут «content» здесь может содержать следующие значения:
- index. Разрешено индексировать все содержимое страницы;
- noindex. Весь контент страницы, кроме ссылок, закрыт от индексации;
- follow. Разрешено индексировать ссылки;
- nofollow. Разрешено сканировать контент, но ссылки при этом закрыты от индексации;
- all. Все содержимое страницы подлежит индексации.
Открывать и закрывать страницу и ее контент можно для краулеров определенной ПС. Для этого в атрибуте «name» нужно указать название робота:
- yandex — обозначает роботов Яндекса:
- googlebot — аналогично для Google.
Помимо прочего, существует метатег Meta Refresh. Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.
Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.
Так выглядит фрагмент кода, запрещающий индексировать страницу:
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>...</body>
</html>Чтобы запретить индексировать страницу краулерам Google, нужно ввести:
<meta name="googlebot" content="noindex, nofollow"/>
Чтобы сделать то же самое в Яндексе:
<meta name="yandex" content="none"/>
На уровне сервера
В некоторых случаях поисковики игнорируют запреты и продолжают индексировать все данные. Чтобы этого не происходило, рекомендуем попробовать ограничить возможность посещения страницы для отдельных краулеров на уровне сервера. Для этого в файл .htaccess в корневой папке сайта нужно добавить специальный код. Yandex» search_bot
Yandex» search_bot
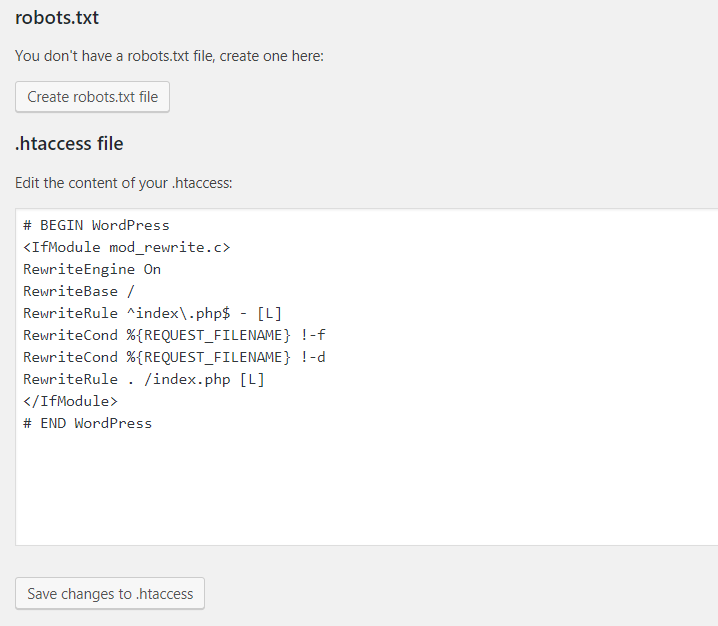
На WordPress
В процессе создания сайта на готовой CMS нужно закрывать его от индексации. Здесь мы разберем, как сделать это в популярной CMS WordPress.
Закрываем весь сайт
Закрыть весь сайт от краулеров можно в панели администратора: «Настройки» => «Чтение». Выберите пункт «Попросить поисковые системы не индексировать сайт». Далее система сама отредактирует файл robots.txt нужным образом.
Закрытие сайта от индексации через панель администратора в WordPress
Закрываем отдельные страницы с помощью плагина Yoast SEO
Чтобы закрыть от индексации как весь сайт, так и его отдельные страницы или файлы, установите плагин Yoast SEO.
Для запрета на индексацию вам нужно:
- Открыть страницу для редактирования и пролистать ее вниз до окна плагина.
- Настроить режим индексации на вкладке «Дополнительно».
Закрытие от индексации с помощью плагина Yoast SEO
Настройка режима индексации
Запретить индексацию сайта на WordPress можно также через файл robots.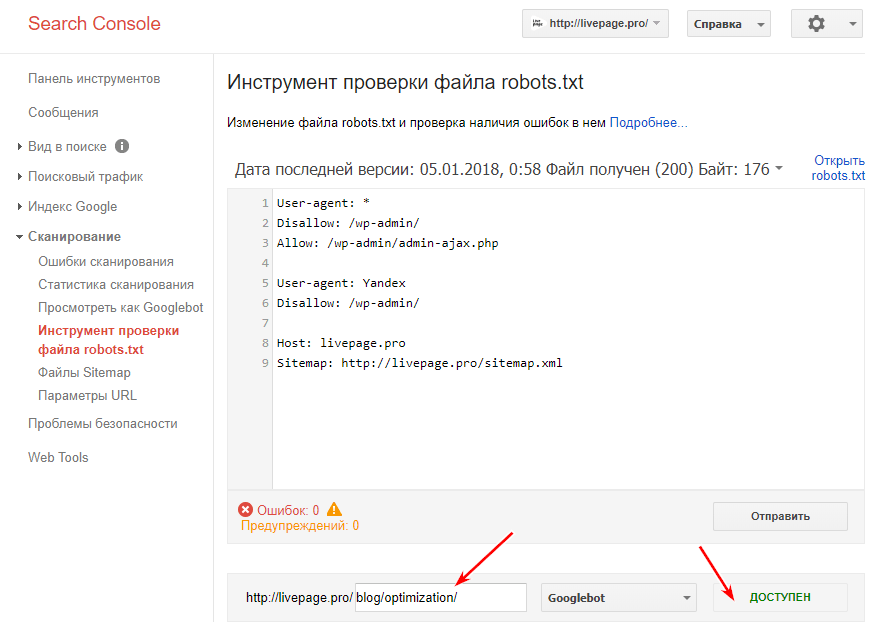 txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
Как узнать, закрыт ли сайт от индексации
Есть несколько способов, которыми вы можете воспользоваться, чтобы проверить, закрыт ли ваш сайт или его отдельная страница от индексации или нет. Ниже рассмотрим самые простые и удобные из них.
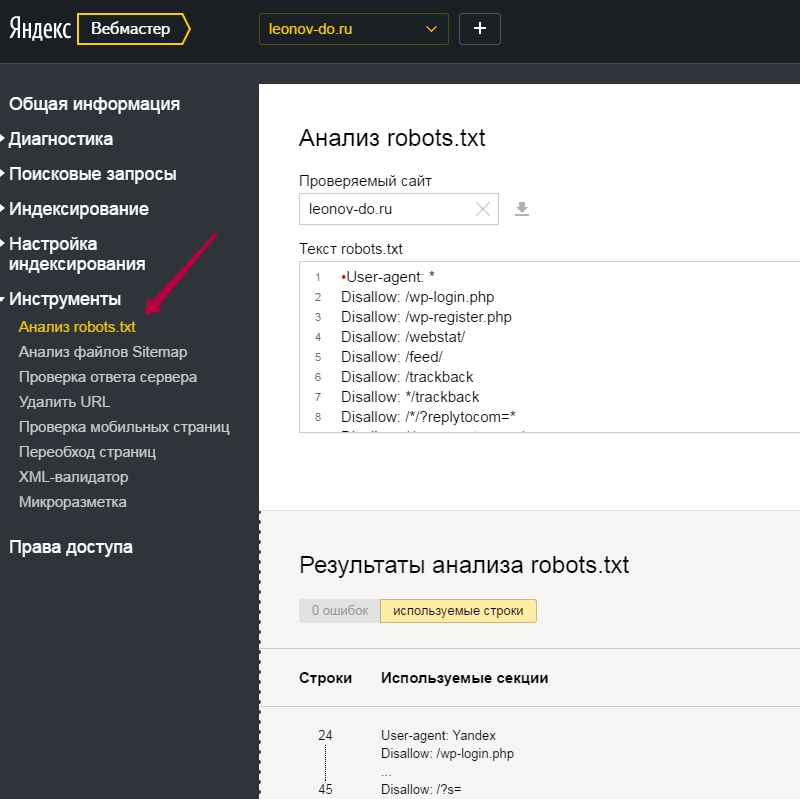
В Яндекс.Вебмастере
Для проверки вам нужно пройти верификацию в Яндексе, зайти в Вебмастер, в правом верхнем углу найти кнопку «Инструменты», нажать и выбрать «Проверка ответа сервера».
Проверка возможности индексации страницы в Яндекс.Вебмастере
В специальное поле на открывшейся странице вставляем URL интересующей страницы. Если страница закрыта от индексации, то появится соответствующее уведомление.
Так выглядит уведомление о запрете на индексацию страницы
Таким образом можно проверить корректность работы файла robots.txt или плагина для CMS.
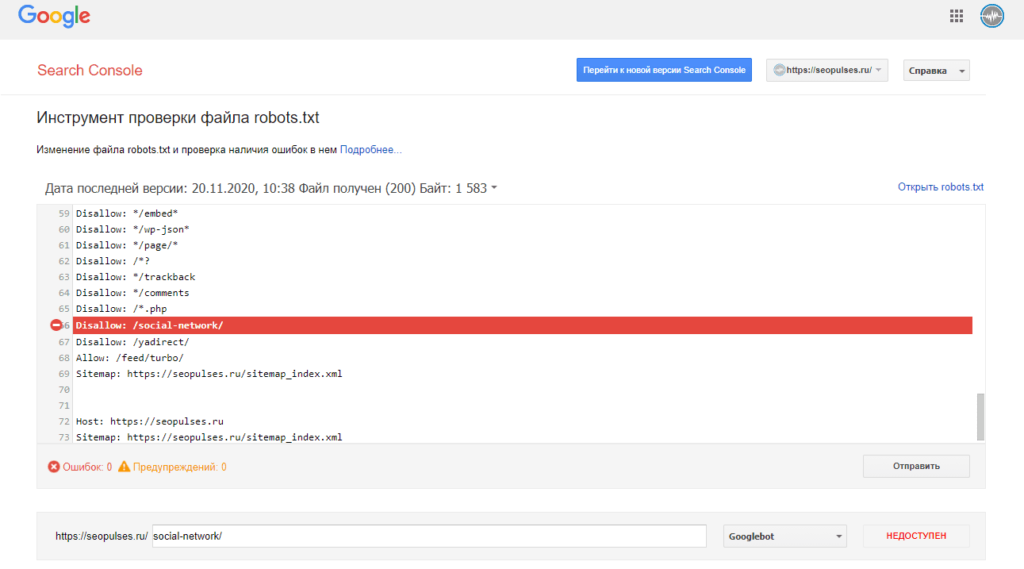
В Google Search Console
Зайдите в Google Search Console, выберите «Проверка URL» и вставьте адрес вашего сайта или отдельной страницы.
Проверка возможности индексации в Google Search Console
С помощью поискового оператора
Введите в поисковую строку следующее: site:https:// + URL интересующего сайта/страницы. В результатах вы увидите количество проиндексированных страниц и так поймете, индексируется ли сайт поисковой системой или нет.
Проверка индексации сайта в Яндексе с помощью специального оператора
Проверка индексации отдельной страницы
С помощью такого же оператора проверить индексацию можно и в Google.
С помощью плагинов для браузера
Мы рекомендуем использовать RDS Bar. Он позволяет увидеть множество SEO-показателей сайта, в том числе статус индексации страницы в основных поисковых системах.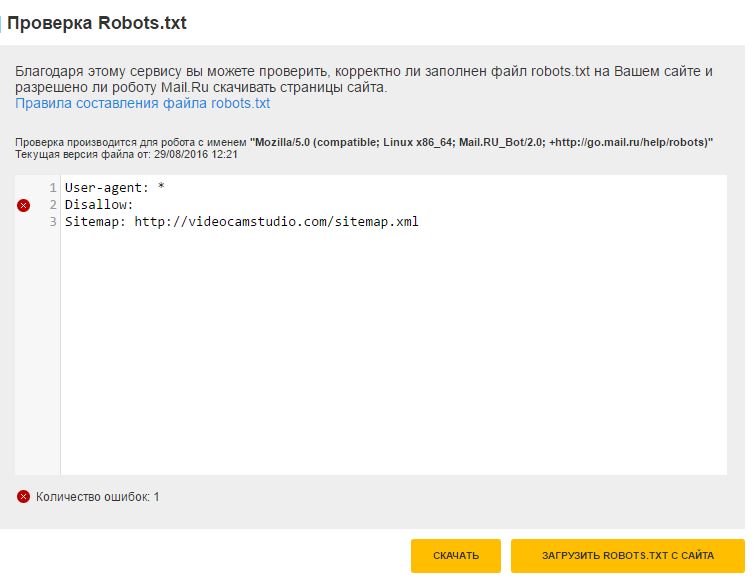
Плагин RDS Bar
Итак, теперь вы знаете, когда сайт или его отдельные страницы/элементы нужно закрывать от индексации, как именно это можно сделать и как проводить проверку, и можете смело применять новые знания на практике.
Как полностью скрыть сайт от индексации?
Про то, как закрыть от индексации отдельную страницу и для чего это нужно мы уже писали. Но могут возникнуть случаи, когда от индексации надо закрыть весь сайт или зеркало, что проблематичнее. Существует несколько способов. О них мы сегодня и расскажем.
Существует несколько способов закрыть сайт от индексации.
Запрет в файле robots.txt
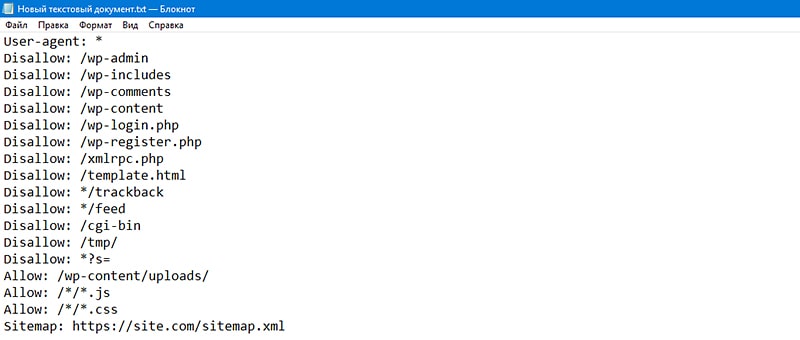
Файл robots.txt отвечает за индексацию сайта поисковыми роботами. Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
User-agent: *
Disallow: /
Остальные правила должны быть удалены.
Этот метод самый простой для скрытия сайта от индексации.
С помощью мета-тега robots
Прописав в шаблоне страниц сайта следующее правило <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/> в теге <head>, вы запретите его индексацию.
Как закрыть зеркало сайта от индексации
Зеркало — точная копия сайта, доступная по другому домену. Т.е. два разных домена настроены на одну и ту же папку с сайтом. Цели создания зеркал могут быть разные, но в любом случае мы получаем полную копию сайта, которую рекомендуется закрыть от индексации.
Сделать это стандартными способами невозможно, т.к. по адресам domen1.ru/robots.txt и domen2.ru/robots.txt открывается один и тот же файл robots.txt с одинаковым содержанием. В таком случае необходимо провести специальные настройки на сервере, которые позволят одному из доменов отдавать запрещающий robots.txt.
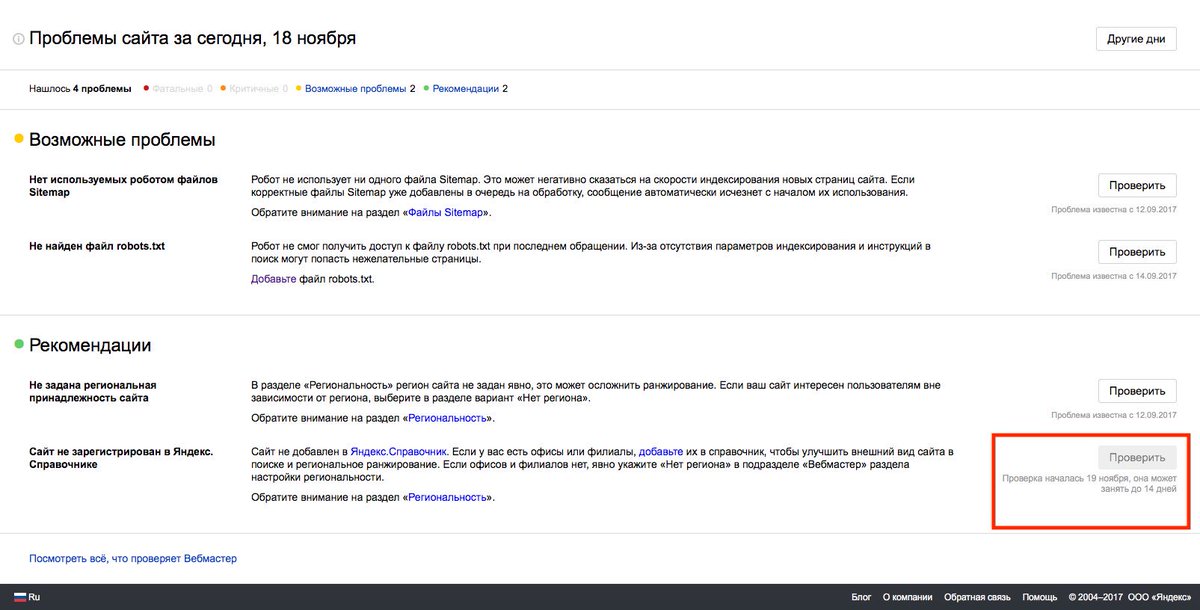
#104
Февраль’19
1170
21
#94
Декабрь’18
2943
28
#60
Февраль’18
3639
19
Запрет индексации в robots.
 txt | REG.RU
txt | REG.RU
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд можно выполнить в файле robots.txt запрет индексации.
Зачем нужен запрет индексации сайта через robots.txt
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Чтобы добавить новые сайты в базы, поисковые системы сканируют интернет с помощью специальных программ (поисковых роботов), которые анализируют содержимое веб-страниц. Этот процесс называется индексацией.
После того как впервые пройдет индексация, страницы сайта начнут отображаться в поисковой выдаче. Пользователи увидят их в процессе поиска информации в Яндекс и Google — самых популярных поисковых системах в рунете. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Если полезная информация в выдаче соседствует с технической информацией или неактуальным контентом — это затрудняет поиск нужных страниц и негативно сказывается на позиции сайта. Чтобы «лишние» страницы не отображались в поисковых системах, их нужно закрывать от индексации.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если не скрыть на время все страницы из поисковых систем, они могут проиндексироваться с ошибками, что отрицательно повлияет на позиции сайта в выдаче.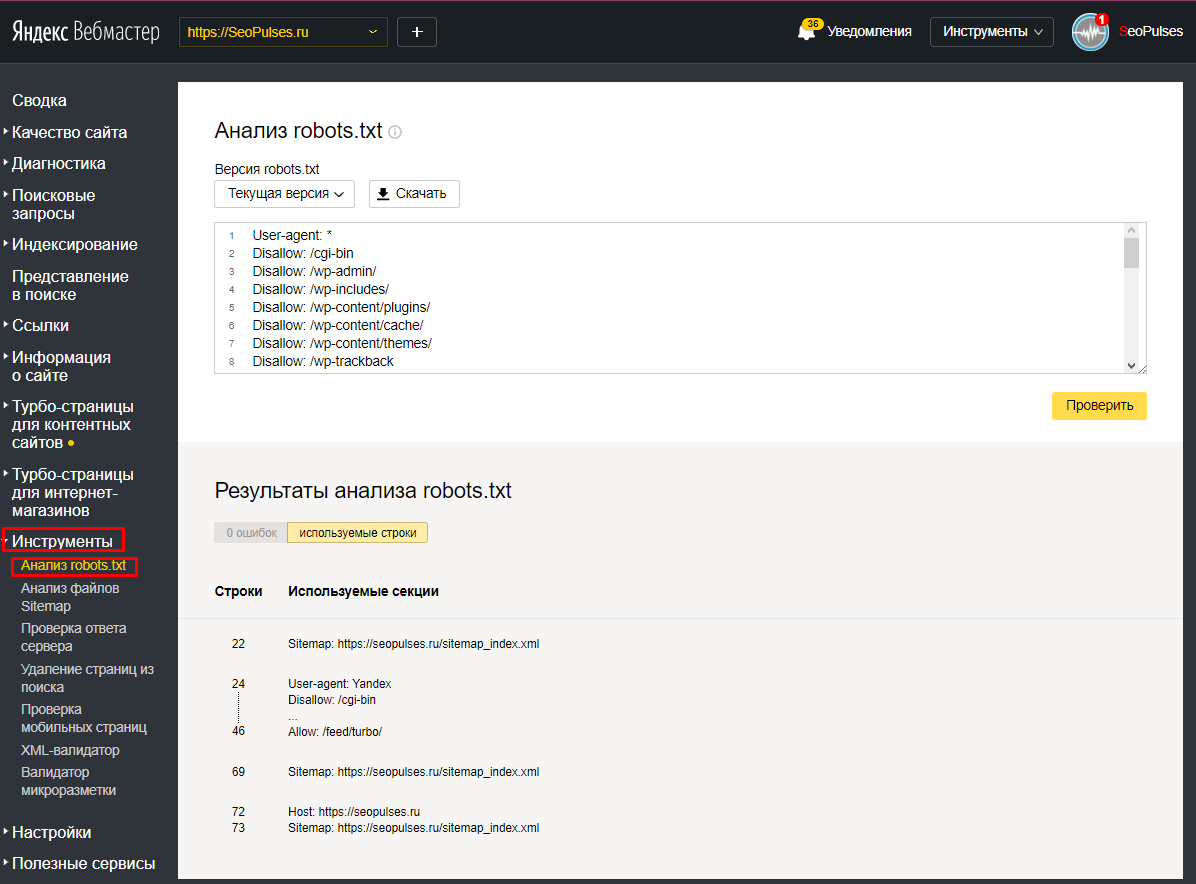
Для того чтобы частично или полностью убрать контент из поиска, достаточно сообщить поисковым роботам, что страницы не нужно индексировать. Для этого необходимо отключить индексацию в служебном файле robots.txt. Файл robots.txt — это текстовый документ, который создан для «общения» с поисковыми роботами. В нем прописываются инструкции о том, какие страницы сайта нельзя посещать и анализировать, а какие — можно.
Прежде чем начать индексацию, роботы обращаются к robots.txt на сайте. Если он есть — следуют указаниям из него, а если файл отсутствует — индексируют все страницы без исключений. Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда) Disallow.
Как запретить индексацию сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots. txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить индексацию всего сайта:
-
1.Откройте файл robots.txt.
-
2.Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /- Чтобы запретить индексацию в конкретной поисковой системе (например, в Яндекс):
User-agent: Yandex Disallow: /- Чтобы закрыть от индексации для всех поисковиков, кроме одного (например, Google)
User-agent: * Disallow: / User agent: Googlebot Allow: /
 org/HowToStep»>
org/HowToStep»>
3.
Сохраните изменения в robots.txt.
Готово. Ресурс пропадет из поисковой выдачи выбранных ПС.
Запрет индексации папки
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, веб-разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
-
1.Откройте robots.txt.
-
2.Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
— Запрет только для Яндекса:
-
3.Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Где вместо catalog — укажите нужную папку.
-
4.Сохраните изменения.

Готово. Вы закрыли от индексации нужный каталог. Если требуется запретить несколько папок, последовательно пропишите для каждой директиву Disallow.
Как закрыть служебную папку wp-admin в плагине Yoast SEO
Как закрыть страницу от индексации в robots.txt
Если нужно закрыть от индексации конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
-
1.Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
-
2.Укажите, для каких поисковых роботов действует правило.
-
3.Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть. Например:
User-agent: * Disallow: /catalog/page.htmlГде вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
-
4.Сохраните изменения.

Готово. Теперь указанный файл не будет индексироваться и отображаться в результатах поиска.
Помогла ли вам статья?
4
раза уже помогла
Какие страницы сайта следует закрывать от индексации поисковых систем
Индексирование сайта – это процесс, с помощью которого поисковые системы, подобные Google и Yandex, анализируют страницы веб-ресурса и вносят их в свою базу данных. Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
В сегодняшней статье я рассмотрю, как правильно настроить индексацию, какие страницы нужно открывать для роботов, а какие нет.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу.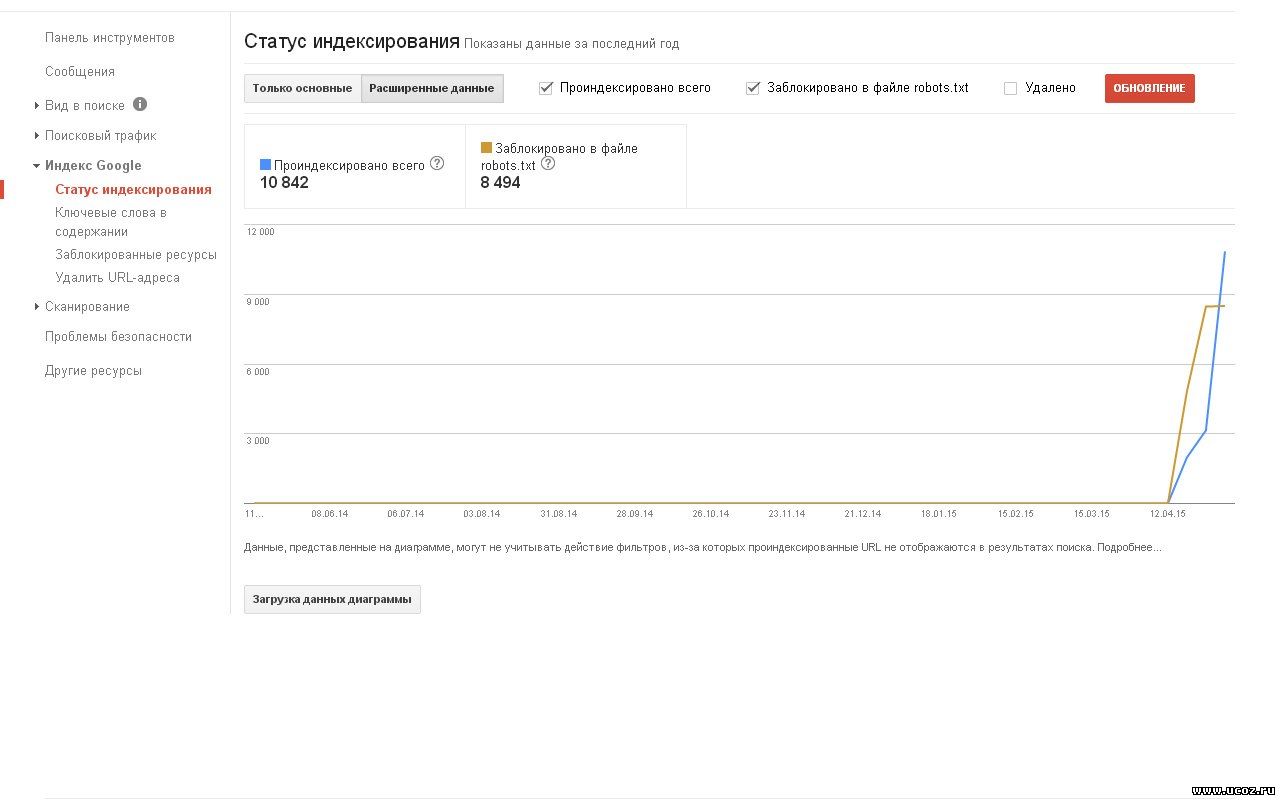 Вот некоторые из них:
Вот некоторые из них:
- Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти. В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
- Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Что нужно скрывать от поисковиков
В первую очередь стоит ограничить индексирование всего сайта, который еще находится на стадии разработки. Именно так можно уберечь базу данных поисковых систем от некорректной информации. Если ваш веб-ресурс давно функционирует, но вы не знаете, какой контент стоит исключить из поисковой выдачи, то рекомендуем ознакомиться с нижеуказанными инструкциями.
PDF и прочие документы
Часто на сайтах выкладываются различные документы, относящиеся к контенту определенной страницы (такие файлы могут содержать и важную информацию, например, политику конфиденциальности).
Рекомендуется отслеживать поисковую выдачу: если заголовки PDF-файлов отображаются выше в рейтинге, чем страницы со схожим запросом, то их лучше скрыть, чтобы открыть доступ к наиболее релевантной информации. Отключить индексацию PDF и других документов вы можете в файле robots.txt.
Разрабатываемые страницы
Стоит всегда избегать индексации разрабатываемых страниц, чтобы рейтинг сайта не снизился. Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Копии сайта
Если вам потребовалось создать копию веб-ресурса, то в этом случае также необходимо все правильно настроить. В первую очередь укажите корректное зеркало с помощью 301 редиректа.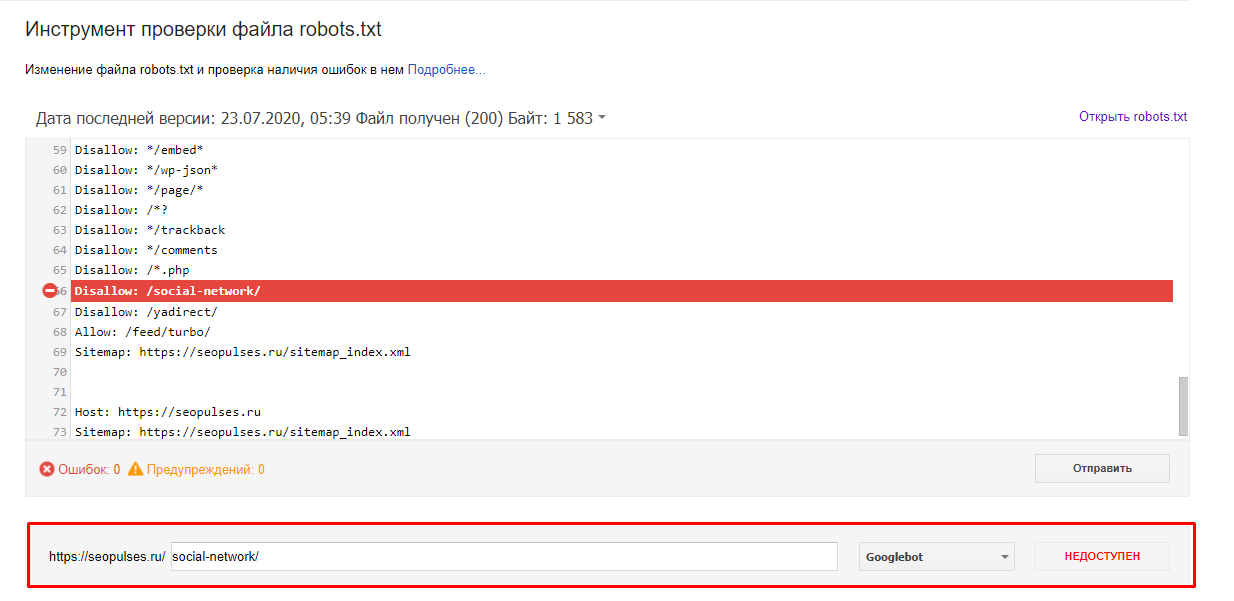 Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Веб-страницы для печати
Иногда контент сайта требует уникальных функций, которые могут быть полезны для клиентов. Одной из таких является «Печать», позволяющая распечатать необходимые страницы на принтере. Создание такой версии страницы выполняется через дублирование, поэтому поисковые роботы могут с легкостью установить копию как приоритетную. Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name=»robots» content=»noindex, follow»/> либо в файле robots.txt.
Формы и прочие элементы сайта
Большинство сайтов сейчас невозможно представить без таких элементов, как личный кабинет, корзина пользователя, форма обратной связи или регистрации.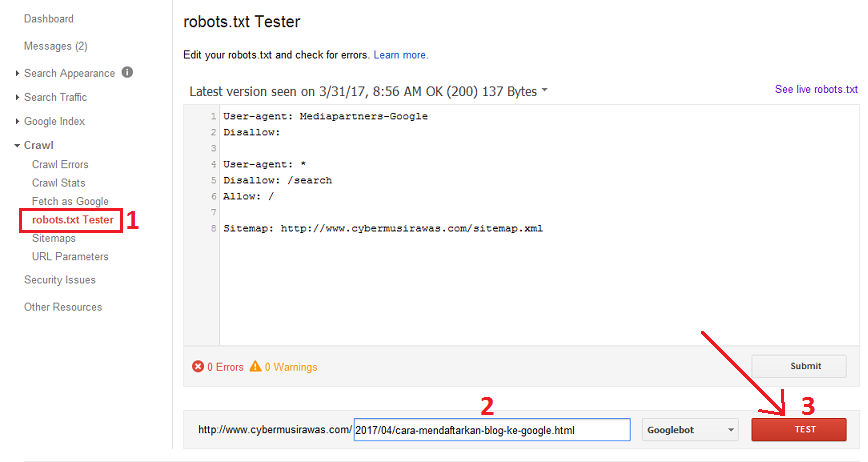 Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Страницы служебного пользования
Формы авторизации в панель управления и другие страницы, используемые администратором сайта, не несут никакой важной информации для обычного пользователя. Поэтому все служебные страницы следует исключить из индексации.
Личные данные пользователя
Вся персональная информация должна быть надежно защищена – позаботиться о ее исключении из поисковой выдачи нужно незамедлительно. Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Страницы с результатами поиска по сайту
Как и в случае со страницами, содержащими личные данные пользователей, индексация такого контента не нужна: веб-страницы результатов полезны для клиента, но не для поисковых систем, так как содержат неуникальное содержание.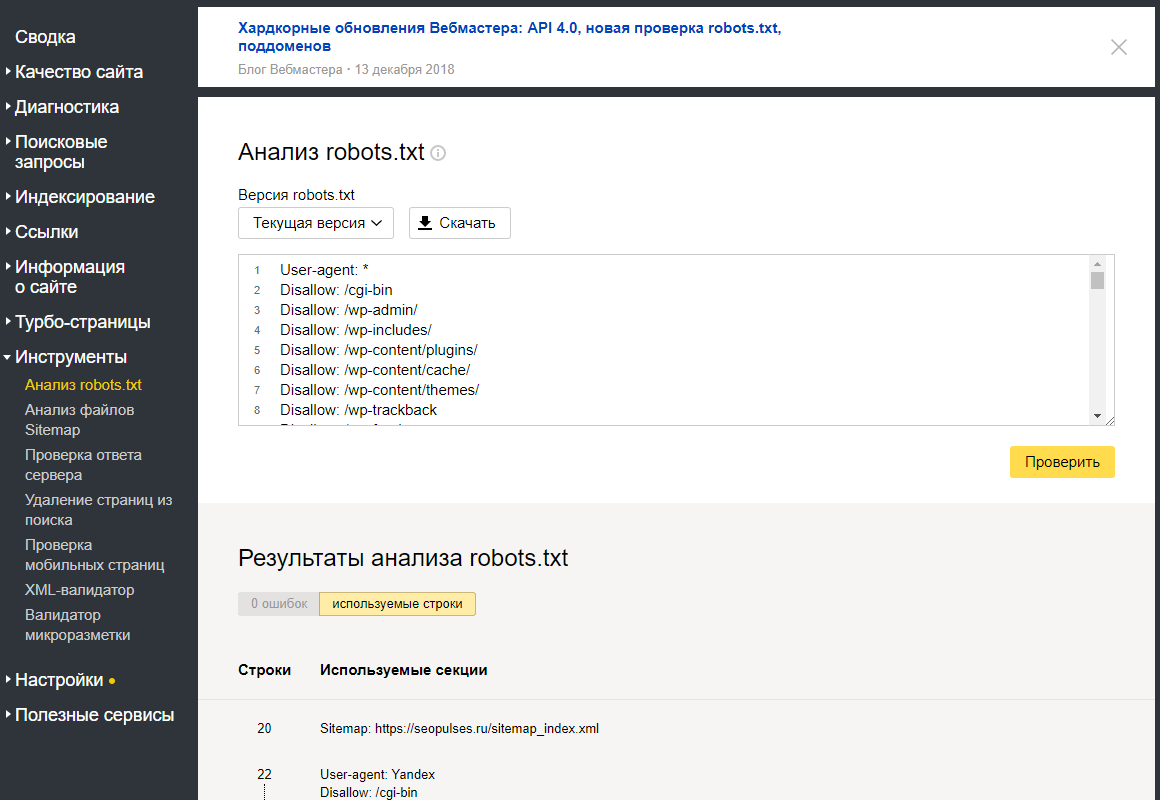
Сортировочные страницы
Контент на таких веб-страницах обычно дублируется, хоть и частично. Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Пагинация на сайте
Пагинация – без нее сложно представить существование любого крупного веб-сайта. Чтобы понять ее назначение, приведу небольшой пример: до появления типичных книг использовались свитки, на которых прописывался текст. Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Пагинация позволяет разделить большой массив данных на отдельные страницы для удобства использования. Отключать индексирование для такого типа контента нежелательно, требуется только настроить атрибуты rel=»canonical», rel=»prev» и rel=»next».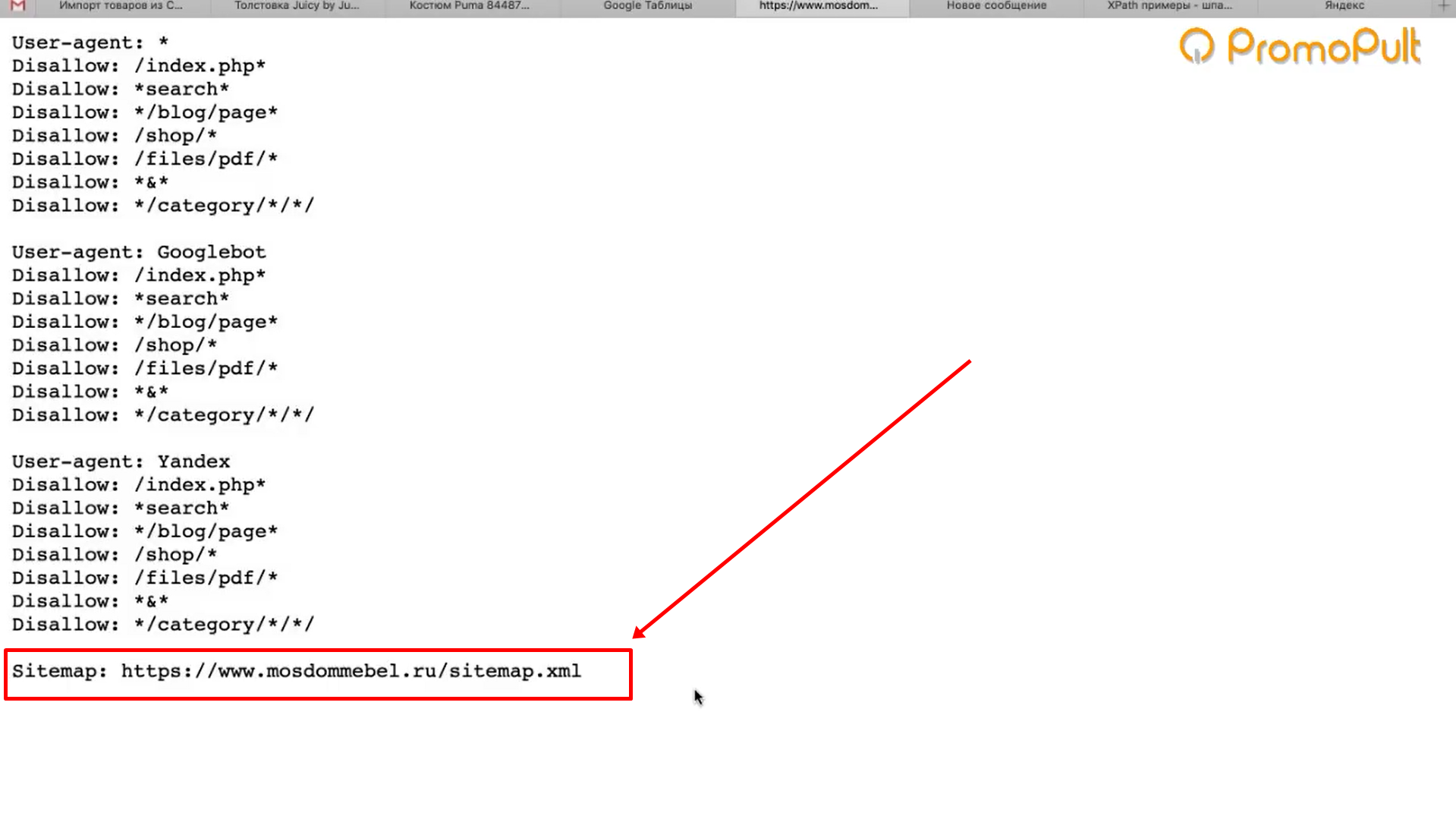 Для Google нужно указать, какие параметры разбивают страницы – сделать это можно в Google Search Console в разделе «Параметры URL».
Для Google нужно указать, какие параметры разбивают страницы – сделать это можно в Google Search Console в разделе «Параметры URL».
Помимо всего вышесказанного, рекомендуется закрывать такие типы страниц, как лендинги для контекстной рекламы, страницы с результатами поиска по сайту и поиск по сайту в целом, страницы с UTM-метками.
Какие страницы нужно индексировать
Ограничение страниц для поисковых систем зачастую становится проблемой – владельцы сайтов начинают с этим затягивать или случайно перекрывают важный контент. Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
- В некоторых случаях могут появляться страницы-дубликаты. Часто это связано со случайным созданием дублирующих категорий, привязкой товаров к нескольким категориям и их доступность по различным ссылкам. Для такого контента не нужно сразу же бежать и отключать индексацию: сначала проанализируйте каждую страницу и посмотрите, какой объем трафика был получен. И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
- Страницы смарт-фильтра – благодаря им можно увеличить трафик за счет низкочастотных запросов. Важно, чтобы были правильно настроены мета-теги, 404 ошибки для пустых веб-страниц и карта сайта.
 И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
Соблюдение индексации таких страниц может значительно улучшить поисковую выдачу, если ранее оптимизация не проводилась.
Как закрыть страницы от индексации
Мы детально рассмотрели список всех страниц, которые следует закрывать от поисковых роботов, но о том, как это сделать, прошлись лишь вскользь – давайте это исправлять. Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Способ 1: Файл robots.txt
Данный текстовый документ – это файл, который первым делом посещают поисковики. Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет. Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет. Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
- наименование прописано в нижнем регистре;
- формат указан как .txt;
- размер не должен превышать 500 Кб;
- местоположение – корень сайта;
- находится по адресу URL/robots.txt, при запросе сервер отправляет в ответ код 200.
Прежде чем переходить к редактированию файла, рекомендую обратить внимание на ограничивающие факторы.
- Директивы robots.txt поддерживаются не всеми поисковыми системами. Большинство поисковых роботов следуют тому, что написано в данном файле, но не всегда придерживаются правил. Чтобы полностью скрыть информацию от поисковиков, рекомендуется воспользоваться другими способами.
- Синтаксис может интерпретироваться по-разному в зависимости от поисковой системы. Потребуется узнать о синтаксисе в правилах конкретного поисковика.
- Запрещенные страницы в файле могут быть проиндексированы при наличии ссылок из прочих источников. По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.
 Потребуется узнать о синтаксисе в правилах конкретного поисковика.
Потребуется узнать о синтаксисе в правилах конкретного поисковика.
Файл robots.txt включает в себя такие параметры, как:
- User-agent – создает указание конкретному роботу.
- Disallow – дает рекомендацию, какую именно информацию не стоит сканировать.
- Allow – аналогичен предыдущему параметру, но в обратную сторону.
- Sitemap – позволяет указать расположение карты сайта sitemap.xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
- Clean-param – позволяет убрать из индекса страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
- Crawl-delay – снижает нагрузку на сервер в том случае, если посещаемость поисковых ботов слишком велика. Обычно используется на сайтах с большим количеством страниц.
 Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
Теперь давайте рассмотрим, как можно отключить индексацию определенных страниц или всего сайта. Все пути в примерах – условные.
Пропишите, чтобы исключить индексацию сайта для всех роботов:
User-agent: * Disallow: /
Закрывает все поисковики, кроме одного:
User-agent: * Disallow: / User-agent: Google Allow: /
Запрет на индексацию одной страницы:
User-agent: * Disallow: /page.html
Закрыть раздел:
User-agent: * Disallow: /category
Все разделы, кроме одного:
User-agent: * Disallow: / Allow: /category
Все директории, кроме нужной поддиректории:
User-agent: * Disallow: /direct Allow: /direct/subdirect
Скрыть директорию, кроме указанного файла:
User-agent: * Disallow: /category Allow: photo.
 png
pngЗаблокировать UTM-метки:
User-agent: * Disallow: *utm=
Заблокировать скрипты:
User-agent: * Disallow: /scripts/*.js
Я рассмотрел один из главных файлов, просматриваемых поисковыми роботами. Он использует лишь рекомендации, и не все правила могут быть корректно восприняты.
Способ 2: HTML-код
Отключение индексации можно осуществить также с помощью метатегов в блоке <head>. Обратите внимание на атрибут «content», он позволяет:
- активировать индексацию всей страницы;
- деактивировать индексацию всей страницы, кроме ссылок;
- разрешить индексацию ссылок;
- индексировать страницу, но запрещать ссылки;
- полностью индексировать веб-страницу.
Чтобы указать поискового робота, необходимо изменить атрибут «name», где устанавливается значение yandex для Яндекса и googlebot – для Гугла. Yandex» search_bot
Yandex» search_bot
Способ 4: Для WordPress
На CMS запретить индексирование всего сайта или страницы гораздо проще. Рассмотрим, как это можно сделать.
Как скрыть весь сайт
Открываем административную панель WordPress и переходим в раздел «Настройки» через левое меню. Затем перемещаемся в «Чтение» – там находим пункт «Попросить поисковые системы не индексировать сайт» и отмечаем его галочкой.
В завершение кликаем по кнопке «Сохранить изменения» – после этого система автоматически отредактирует файл robots.txt.
Как скрыть отдельную страницу
Для этого необходимо установить плагин Yoast SEO. После этого открыть страницу для редактирования и промотать в самый низ – там во вкладке «Дополнительно» указать значение «Нет».
Способ 5: Сервисы для вебмастеров
В Google Search Console мы можем убрать определенную страницу из поисковика. Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Процедура запрета на индексацию выбранной страницы может занять некоторое время. Аналогичные действия можно совершить в Яндекс.Вебмастере.
На этом статья подходит к концу. Надеюсь, что она была полезной. Теперь вы знаете, что такое индексация сайта и как ее правильно настроить. Удачи!
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на
другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots. txt
- Проверка корректности закрытия сайта от
индексации - Альтернативные способы закрыть сайт от поисковых
систем
 txt
txtОглавление
Процесс индексации
Индексация сайта – это процесс добавления данных вашего ресурса в индексную базу поисковых систем. Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот
момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.
Если сайта нет в индексной базе поисковой системе = тогда
сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым
запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров.
Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы
находитесь в стадии разработки (или доработки) ресурса. В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.txt
Обращение к Вашему сайту поисковой системой начинается с
прочтения содержимого файла robots.txt. Это служебный файл со специальными
правилами для поисковых роботов.
Подробнее о директивах robots.txt:
Самый простой и быстрый способ это при первом обращении к
вашему ресурсу со стороны поисковых систем (к файлу robots. txt) сообщить
txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
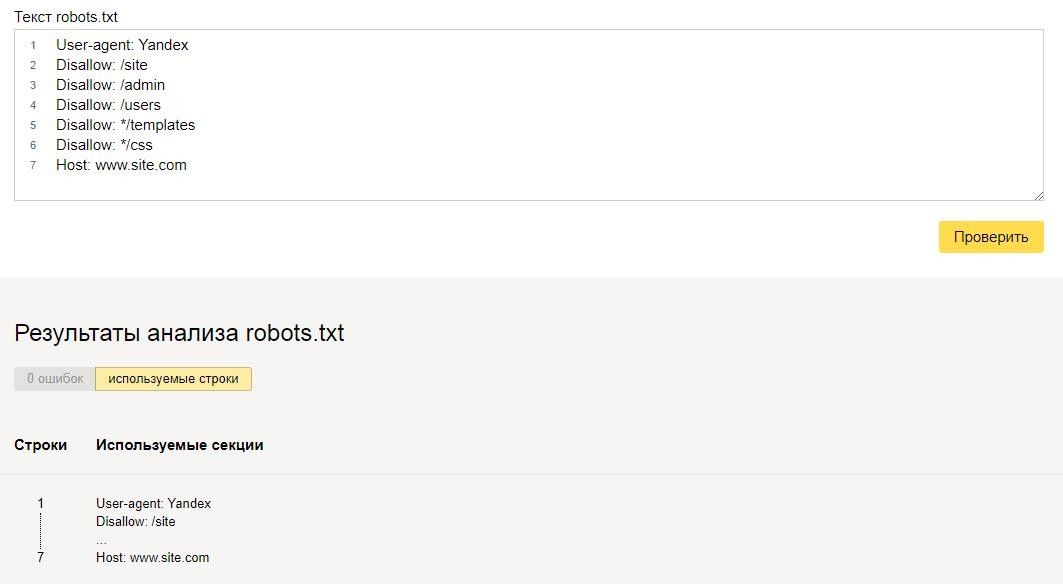
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем
способам подключения к хостингу или серверу, укажем самый простой способ на наш
взгляд.
Файл robots.txt всегда находится в корне Вашего сайта.
Например, robots.txt сайта iqad.ru будет
находится по адресу:
https://iqad.ru/robots.txt
Для подключения к сайту, мы должны в административной панели
нашего хостинг провайдера получить FTP (специальный протокол передачи файлов
по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
Авторизуемся в панели управления вашим хостингом и\или сервером, находим раздел FTP и создаем ( получаем ) уникальную пару логин \ пароль.
В описании
раздела или в разделе помощь, необходимо
найти и сохранить необходимую информацию для подключения по FTP к серверу,
на котором размещены файлы Вашего сайта. Данные отражают информацию, которую
нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно
воспользоваться бесплатной программой filezilla (https://filezilla.ru/).
Вводим данные в соответствующие поля и нажимаем подключиться.
FTP-клиент filezilla интуитивно прост и понятен: вводим cервер (host) + логин (имя пользователя) + пароль + порт и кнопка {быстрое соединение}. В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
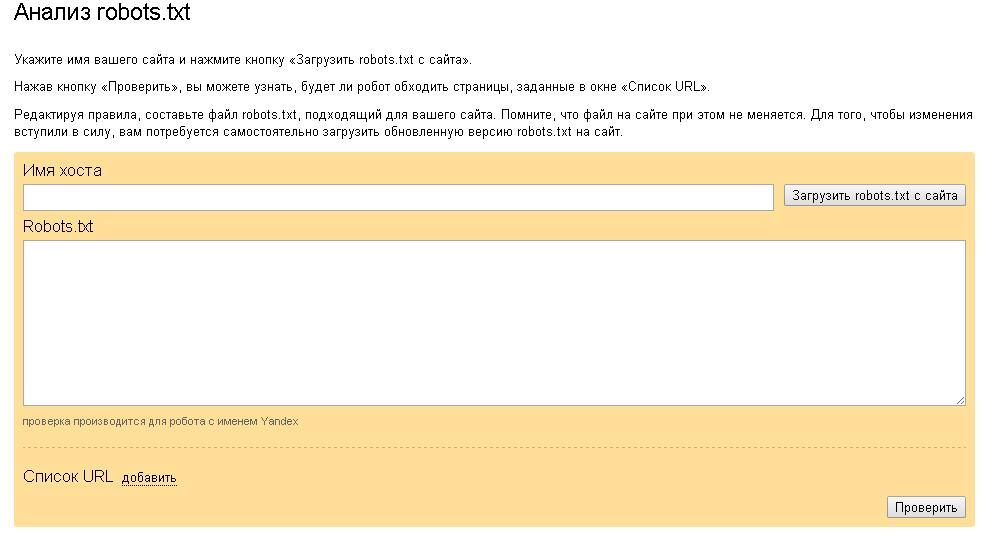
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt
необходимо убедится в том, что все сделано верно. Для этого открываем файл
robots.txt
на вашем сайте.
Инструменты iqad
В арсенале команды IQAD есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Самостоятельно
Открыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www.site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.
Сервис Я.ВЕБМАСТЕР
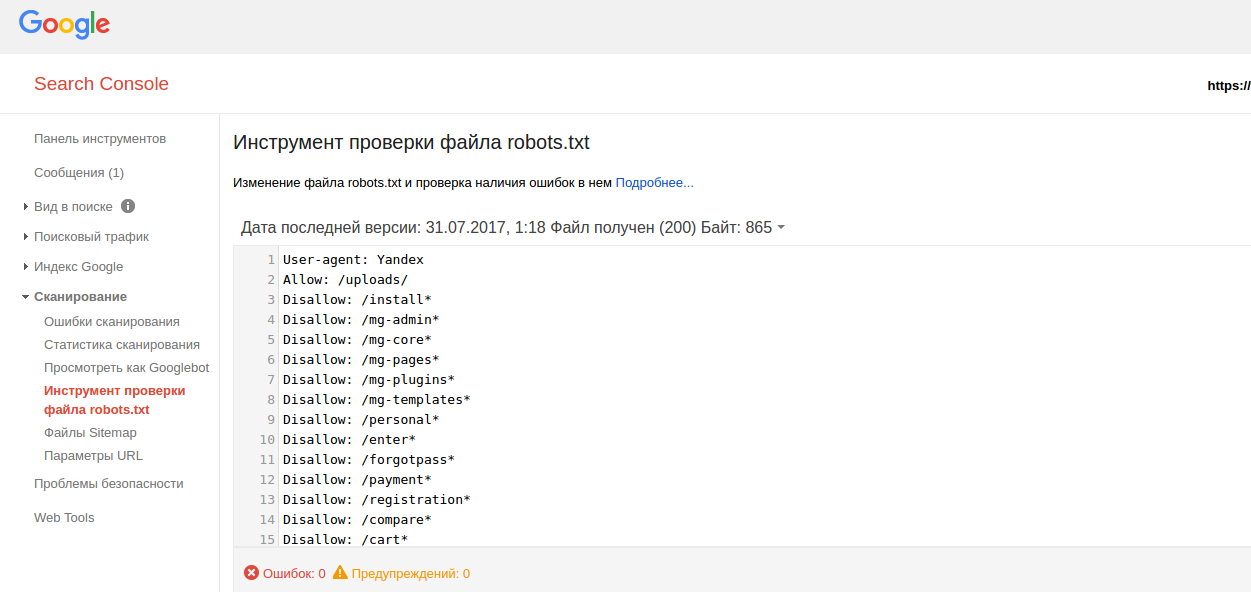
Бесплатный сервис Я.ВЕБМАСТЕР – анализ robots.txt.
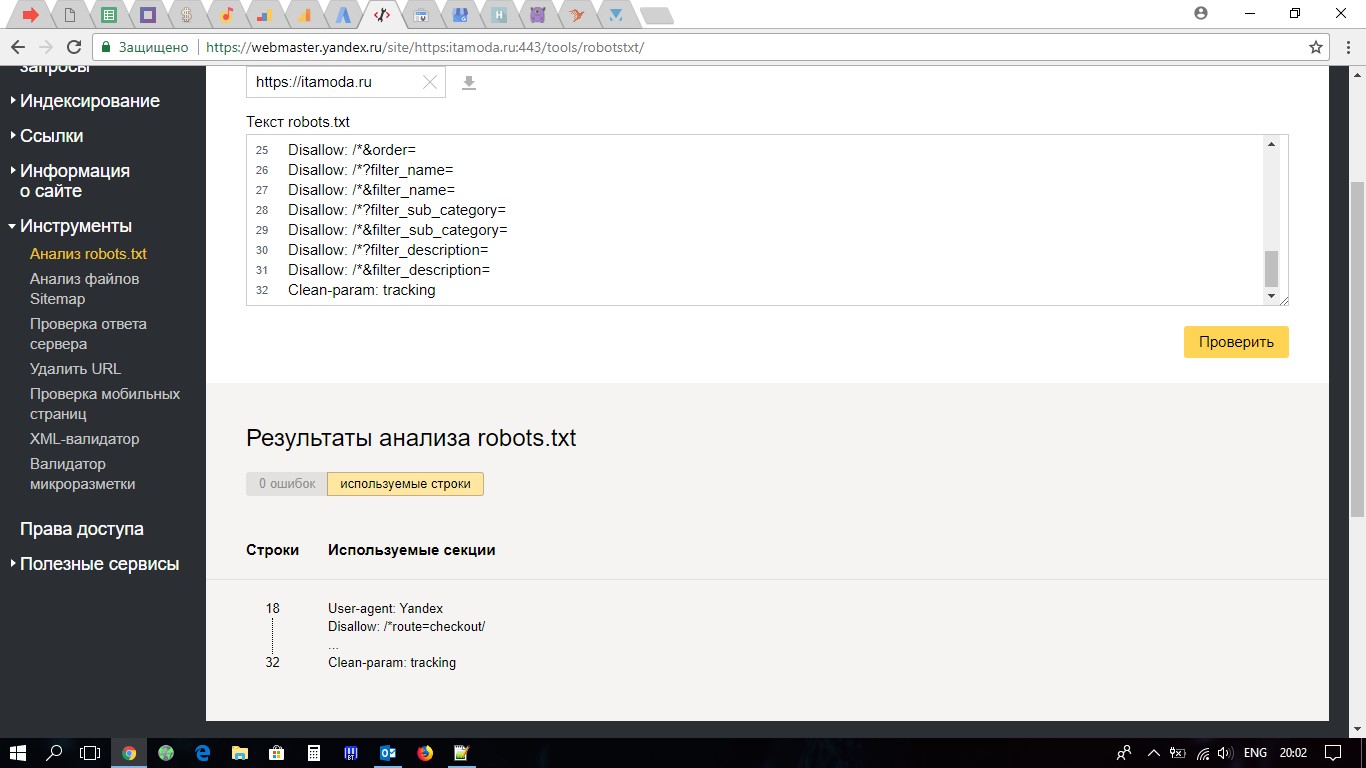
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.
Альтернативные способы закрыть сайт от поисковых систем
Помимо классического
способа с использованием файла robots.txt можно прибегнуть и к другим, не
стандартным, подходам. Однако у них есть ряд недостатков.
- Вы можете
отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не
гарантирует 100% исключения сайта из индекса. Какое-то время робот может
хранить копию Ваших страниц и отдавать именно их. - С помощью специального
meta тега: <meta name=”robots”>
<meta name=”robots” content=”noindex, nofollow”>
Но
так как метатег размещается и его действие относиться только к 1 странице, то
для полного закрытия сайта от индексации Вам придется разместить такой тег на
каждой странице Вашего сайта.
Недостатком
этого может быть несовершенство поисковых систем и проблемы с индексацией
ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться
много времени, иногда несколько месяцев, часть страниц будет присутствовать в
поиске.
- Использование
технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент
Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет
увидеть контент сайта. При этом по названию сайта или по открытой части в
индексе поисковиков может что-то хранится. Более того, уже завра новое
обновление поисковых роботов может научится индексировать такой контент. - Скрыть все
данные Вашего сайта за регистрационной формой. При этом стартовая страница в
любом случае будет доступна поисковым роботам.
Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле
robots.txt прописать следующую директиву:
Disallow: /
«robots. txt» это служебный файл со специальными правилами для поисковых роботов.
txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения
директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Запретить индексацию страниц/директорий (robots.txt) — База знаний
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx. txt нет в каталоге вашего сайта, тогда вы можете его создать.
txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
Disallow: / # будет запрещено индексирование всего сайта
Disallow: /page/ # будет запрещено индексирование директории /page/
Примеры:
1. Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
2. Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
3. Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
4. Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
5. Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
6. Усложняем задачу и например Яндексу запрещаем индексировать папки cgi-bin и images, а Апорту файлы myfile1.htm и myfile2.htm в директории subdir (название папки где расположены файлы myfile1.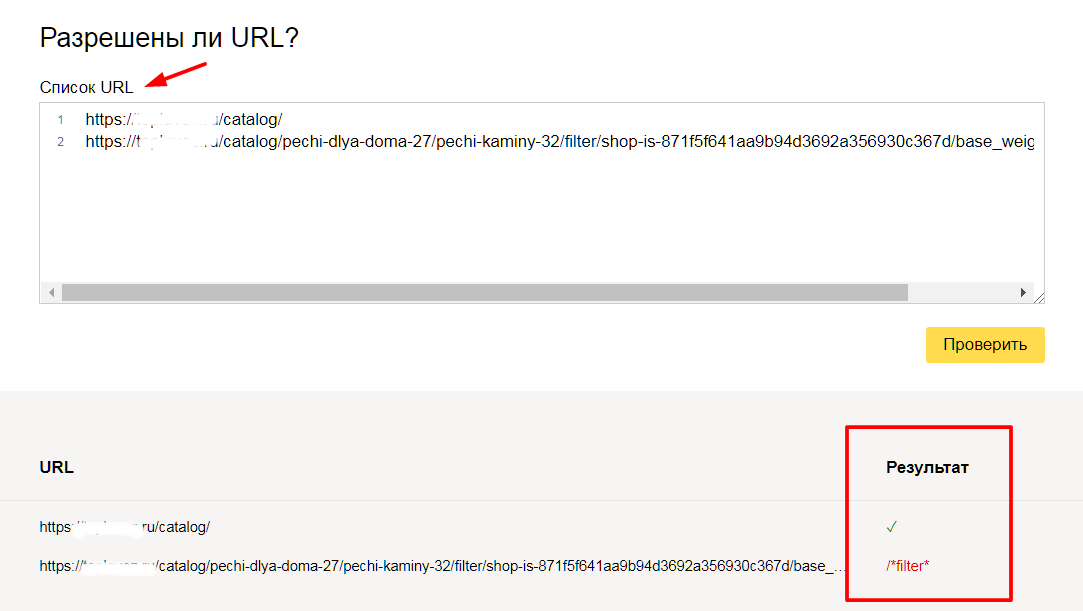 htm и myfile2.htm)
htm и myfile2.htm)
User-agent: Yandex
Disallow: /cgi-bin/
Disallow: /images/
User-agent: Aport
Disallow: /subdir/myfile1.htm
Disallow: /subdir/myfile2.htm
7. Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots.txt):
User-agent: *
Disallow:
P.S. Для различных CMS, в интернете можно найти рекомендации, какие директории лучше закрыть от индексации поисковиками., в большей степени это нужно ради безопасности и уменьшения нагрузки на сервер.
Robots.txt Введение и руководство | Центр поиска Google
Файл robots.txt сообщает сканерам поисковых систем, к каким URL-адресам сканер может получить доступ на вашем сайте.
Это используется в основном для того, чтобы избежать перегрузки вашего сайта запросами; это не
механизм для защиты веб-страницы от Google . Чтобы веб-страница не попала в Google, вы
Чтобы веб-страница не попала в Google, вы
должен блокировать индексацию с помощью noindex
или защитите страницу паролем.
Что такое роботы.txt используется для?
Файл robots.txt используется в первую очередь для управления трафиком сканеров на ваш сайт, а также
обычно , чтобы хранить файл вне Google, в зависимости от типа файла:
| Влияние robots.txt на разные типы файлов | |
|---|---|
| Интернет-страница | Вы можете использовать файл robots.txt для веб-страниц (HTML, PDF или другие Не используйте файл robots.txt как средство, чтобы скрыть свои веб-страницы от поиска Google. Если другие страницы указывают на вашу страницу с описательным текстом, Google все равно может проиндексировать Если ваша веб-страница заблокирована файлом robots.txt , ее URL-адрес все еще может |
| Медиа-файл | Используйте файл robots.txt для управления трафиком сканирования, а также для предотвращения изображений, видео и |
| Файл ресурсов | Вы можете использовать файл robots.txt, чтобы заблокировать файлы ресурсов, такие как неважное изображение, сценарий, или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не будут существенно повлияет убыток . Однако если их отсутствие ресурсы затрудняют понимание страницы поисковым роботом Google, вам следует не блокировать их, иначе Google не будет хорошо анализировать страницы, зависящие от эти ресурсы. 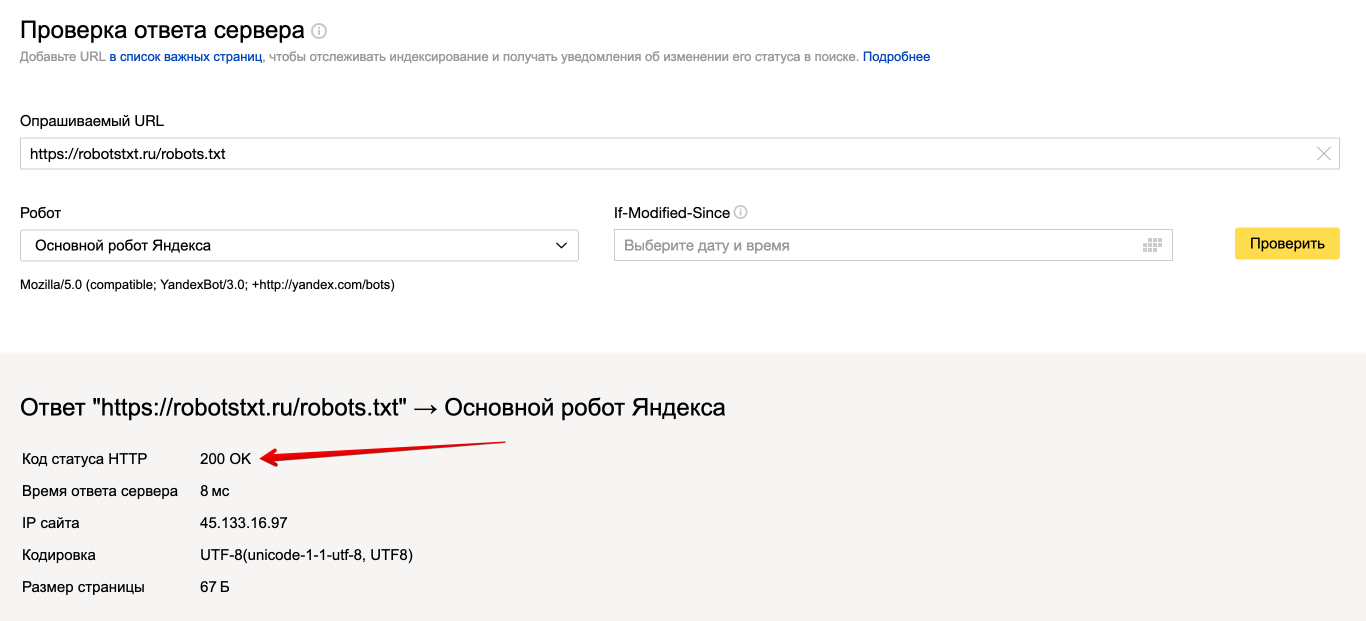 |
 txt
txtПоймите ограничения роботов.txt файл
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этой блокировки URL.
метод. В зависимости от ваших целей и ситуации вы можете рассмотреть другие механизмы
убедитесь, что ваши URL-адреса не могут быть найдены в Интернете.
- Директивы robots.txt могут поддерживаться не всеми поисковыми системами.
Инструкции в файлах robots.txt не могут принудить сканер к вашему сайту; работает
гусеницу подчиняться им.В то время как робот Googlebot и другие уважаемые веб-сканеры подчиняются
инструкции в файле robots.txt, другие сканеры не могут. Поэтому, если вы хотите сохранить
информация защищена от веб-сканеров, лучше использовать другие методы блокировки, такие как
защита паролем личных файлов на вашем сервере. - Разные сканеры по-разному интерпретируют синтаксис
Хотя уважаемые поисковые роботы следуют директивам в файле robots.txt, каждый поисковый робот
могут интерпретировать директивы по-разному.Вы должны знать
правильный синтаксис для адресации
разные поисковые роботы, так как некоторые могут не понимать определенные инструкции. - Роботизированная страница может
по-прежнему будет индексироваться, если на него ссылаются с других сайтов
Хотя Google не будет сканировать или индексировать контент, заблокированный файлом robots.txt, мы все же можем
найти и проиндексировать запрещенный URL, если на него есть ссылки из других мест в Интернете. Как результат,
URL-адрес и, возможно, другая общедоступная информация, например текст привязки
в ссылках на страницу все еще может отображаться в результатах поиска Google.Чтобы правильно предотвратить ваш URL
от появления в результатах поиска Google,
защитить паролем файлы на вашем сервере,
используйте метатегnoindexили заголовок ответа,
или удалите страницу полностью.

Важно : сочетание нескольких директив сканирования и индексирования может вызвать
некоторые директивы для противодействия другим директивам. Узнайте, как
совместить сканирование с директивами индексирования и обслуживания.
Создайте файл robots.txt файл
Если вы решили, что он вам нужен, узнайте, как
создайте файл robots.txt.
Как Google интерпретирует спецификацию robots.txt | Центр поиска
Автоматизированная система Google
краулеры поддерживают
Протокол исключения роботов (REP).
Это означает, что перед сканированием сайта сканеры Google загружают и анализируют
Файл robots.txt для извлечения информации о том, какие части сайта можно сканировать.REP
неприменимо к сканерам Google, которые контролируются пользователями (например, фид
подписок) или поисковые роботы, которые используются для повышения безопасности пользователей (например, вредоносное ПО
анализ).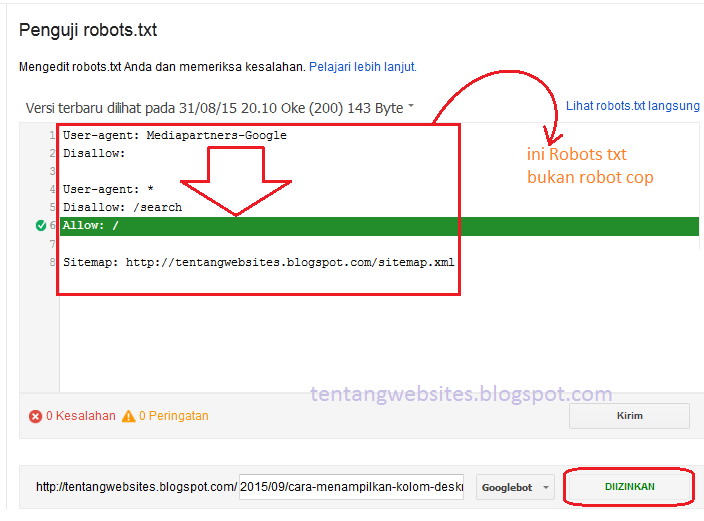
На этой странице описывается интерпретация REP в Google. Для оригинала
проект стандарта, проверьте
IETF Data Tracker.
Если вы новичок в robots.txt, начните с нашего
введение в robots.txt. Вы также можете найти
советы по созданию файла robots.txt
и обширный список
часто задаваемые вопросы и ответы на них.
Что такое файл robots.txt
Если вы не хотите, чтобы сканеры получали доступ к разделам вашего сайта, вы можете создать файл robots.txt.
с соответствующими правилами. Файл robots.txt — это простой текстовый файл, содержащий правила, в отношении которых
сканеры могут получить доступ к каким частям сайта.
Местоположение файла и срок действия
Вы должны поместить файл robots.txt в каталог верхнего уровня сайта на поддерживаемом
протокол. В случае поиска Google поддерживаемые протоколы: HTTP,
HTTPS и FTP. По HTTP и HTTPS сканеры получают файл robots.txt с помощью HTTP
По HTTP и HTTPS сканеры получают файл robots.txt с помощью HTTP
безусловный запрос GET ; на FTP сканеры используют стандартный
RETR (RETRIEVE) команда с использованием анонимного входа в систему.
Правила, перечисленные в файле robots.txt, применяются только к хосту, протоколу и номеру порта.
где размещен файл robots.txt.
URL-адрес файла robots.txt (как и другие URL-адреса) чувствителен к регистру.
Примеры действительных роботов.txt URL
| Robots.txt Примеры URL | |
|---|---|
http://example.com/robots.txt | Действителен до:
Не действует для:
Это общий случай. Это не действует для других поддоменов, протоколов или портов. |
http://www.example.com/robots.txt | Действителен до: Недействительно для:
Файл robots.txt на субдомене действителен только для этого субдомена. |
http://example.com/folder/robots.txt | Не действующий robots.txt файл. Сканеры не проверяют файлы robots.txt в подкаталогах. |
http://www.exämple.com/robots.txt | Действителен до:
Не действует для: IDN эквивалентны своим версиям punycode. |
ftp://example.com/robots.txt | Действителен до: Не действует для: |
http://212.96.82.21/robots.txt | Действителен до: Не действует для: Файл robots.txt с IP-адресом в качестве имени хоста действителен только для сканирования этого |
http://example.com:80/robots.txt | Действительно для:
Не действует для: Стандартные номера портов ( |
http://example.com:8181/robots.txt | Действителен до: Не действует для: Файлы robots.txt с нестандартными номерами портов действительны только для контента, созданного |
 com/folder/file
com/folder/file  www.example.com/
www.example.com/ 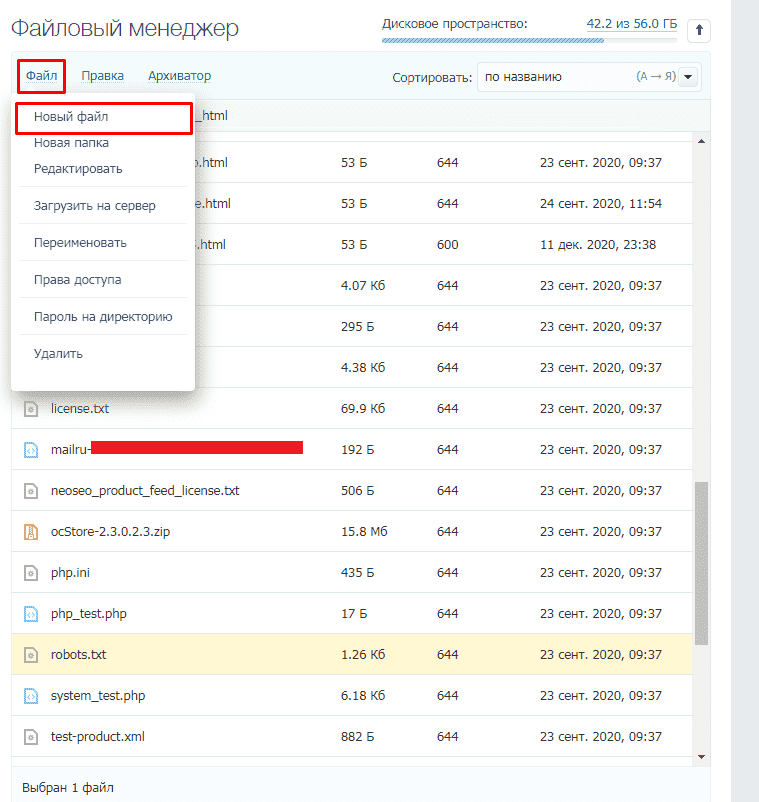 Смотрите также
Смотрите также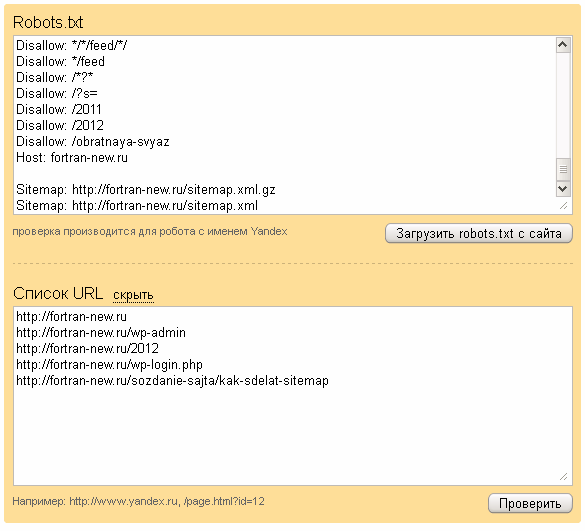 Это не распространяется автоматически на все веб-сайты, размещенные на этом
Это не распространяется автоматически на все веб-сайты, размещенные на этом
Обработка ошибок и кодов состояния HTTP
При запросе файла robots.txt код статуса HTTP ответа сервера влияет на то, как
файл robots.txt будет использоваться поисковыми роботами Google.
| Обработка ошибок и кодов состояния HTTP | |
|---|---|
2xx (успешно) | Коды состояния HTTP, которые сигнализируют об успехе, побуждают сканеры Google обрабатывать файл robots.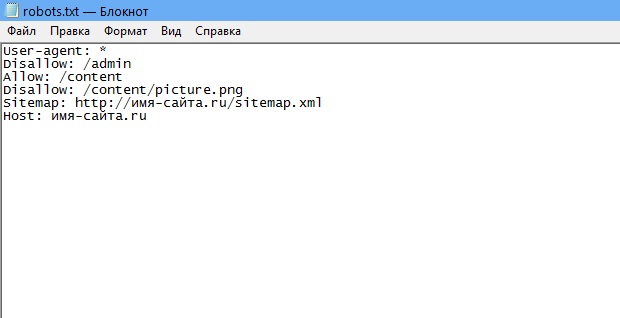 текст текстфайл, предоставленный сервером. |
3xx (перенаправление) | Google выполняет не менее пяти переходов переадресации, как определено Google не выполняет логические перенаправления в файлах robots.txt (фреймы, JavaScript или |
4xx (ошибки клиента) | Сканеры Google обрабатывают все ошибки Сюда входят |
5xx (ошибка сервера) | Поскольку сервер не смог дать однозначный ответ на запрос Google robots.txt, Если вам нужно временно приостановить сканирование, мы рекомендуем Если мы можем определить, что сайт неправильно настроен для возврата |
| Прочие ошибки | Файл robots. txt, который невозможно получить из-за проблем с DNS или сетью, например txt, который невозможно получить из-за проблем с DNS или сетью, напримертаймауты, недопустимые ответы, сброс или прерванные соединения и ошибки фрагментации HTTP рассматривается как ошибка сервера. |
 txt. Если недоступен, Google предполагает, что нет
txt. Если недоступен, Google предполагает, что нетКэширование
Google обычно кэширует содержимое файла robots.txt на срок до 24 часов, но может кэшировать его.
дольше в ситуациях, когда обновление кэшированной версии невозможно (например, из-за
таймауты или ошибки 5xx ). Кешированный ответ может использоваться разными сканерами.
Google может увеличивать или уменьшать время жизни кеша в зависимости от
Максимальный возраст Cache-Control
Заголовки HTTP.
Формат файла
Роботы.txt должен быть
Простой текст в кодировке UTF-8
файл и строки должны быть разделены символами CR , CR / LF или
LF .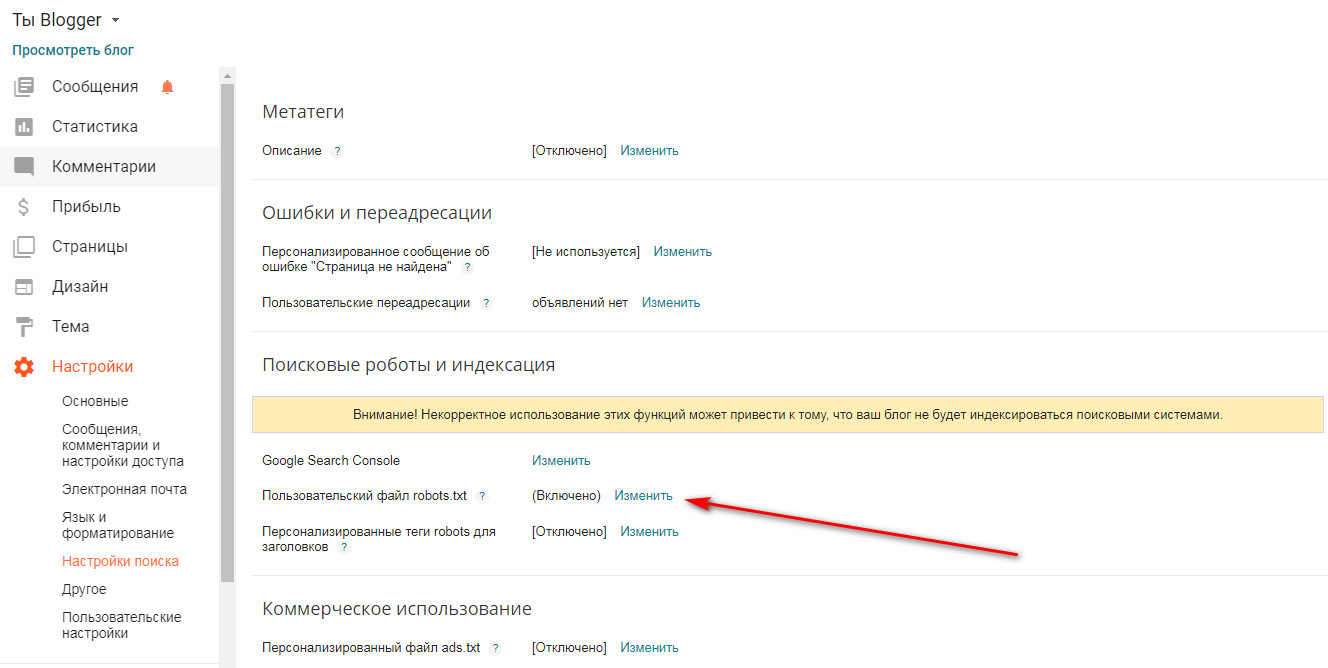
Google игнорирует недопустимые строки в файлах robots.txt, включая Unicode.
Знак порядка байтов
(BOM) в начале файла robots.txt и используйте только допустимые строки. Например, если
загруженный контент представляет собой HTML, а не правила robots.txt, Google попытается проанализировать контент
и извлекать правила, а все остальное игнорировать.
Точно так же, если кодировка файла robots.txt отличается от UTF-8, Google может игнорировать
символы, не входящие в диапазон UTF-8, потенциально могут отображать правила robots.txt
инвалид.
В настоящее время Google применяет ограничение на размер файла robots.txt, равное 500.
кибибайт (KiB). Содержание
после того, как максимальный размер файла игнорируется. Вы можете уменьшить размер файла robots.txt.
файл, объединив директивы, которые могут привести к слишком большому размеру файла robots.txt файл. Для
Например, поместите исключенный материал в отдельный каталог.
Синтаксис
Допустимые строки robots.txt состоят из поля, двоеточия и значения. Пробелы необязательны, но
рекомендуется для улучшения читаемости. Пробел в начале и в конце строки равен
игнорируется. Чтобы включить комментарии, поставьте перед комментарием символ # . Держать в
Учтите, что все, что находится после символа # , будет проигнорировано.Общий формат
<поле>: <значение> <# необязательный-комментарий> .
Google поддерживает следующие поля:
-
user-agent: определяет, к какому искателю применяются правила. -
разрешить: путь URL-адреса, который можно сканировать. -
запретить: путь URL, сканирование которого невозможно. -
карта сайта: полный URL карты сайта.
Поля allow и disallow также называются директивами .
Эти директивы всегда указываются в виде
Директива : [путь] , где [путь] является необязательным. По умолчанию нет
ограничения на сканирование для указанных сканеров. Сканеры игнорируют директивы без
[путь] .
Значение [путь] , если указано, относится к корню веб-сайта, откуда
роботы.txt был получен (с использованием того же протокола, номера порта, имени хоста и домена).
Значение пути должно начинаться с / для обозначения корня, а значение —
с учетом регистра. Узнать больше о
Соответствие URL-адресов на основе значений пути.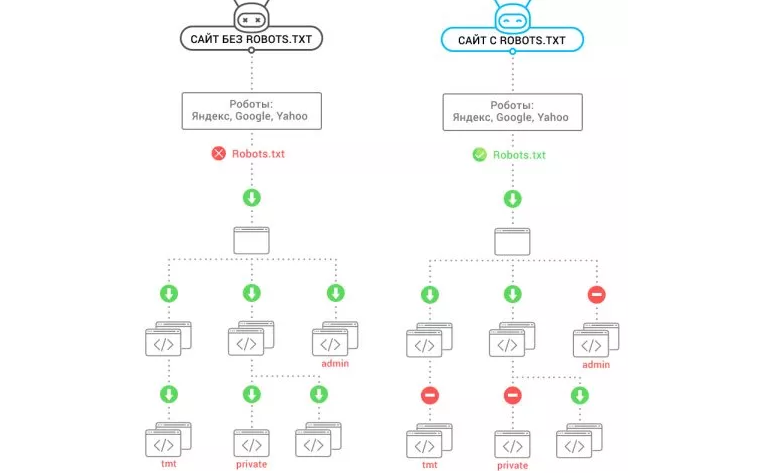
агент пользователя
Строка пользовательского агента определяет, к каким правилам искателя применяются. Видеть
Сканеры Google и строки пользовательского агента
для получения исчерпывающего списка строк пользовательских агентов, которые вы можете использовать в своих файлах robots.txt файл.
Значение строки пользовательского агента не чувствительно к регистру.
запретить
Директива disallow указывает пути, к которым не должны обращаться сканеры.
идентифицируется строкой user-agent, с которой сгруппирована директива disallow .
Сканеры игнорируют директиву без пути.
Google не может индексировать содержание страниц, сканирование которых запрещено, но все же может
проиндексировать URL-адрес и показать его в результатах поиска без фрагмента. Узнайте, как
Узнайте, как
блочная индексация.
Значение директивы disallow чувствительно к регистру.
использование:
запретить: [путь]
разрешить
Директива allow определяет пути, к которым могут получить доступ указанные
краулеры. Если путь не указан, директива игнорируется.
Значение директивы allow чувствительно к регистру.
использование:
разрешить: [путь]
карта сайта
Google, Bing и другие основные поисковые системы поддерживают поле карты сайта в
robots.txt, как определено sitemaps.org.
Значение поля карты сайта чувствительно к регистру.
использование:
карта сайта: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла карты сайта или файла индекса карты сайта.Это должен быть полный URL-адрес, включая протокол и хост, и не обязательно
В кодировке URL. URL-адрес не обязательно должен находиться на том же хосте, что и файл robots.txt. Ты можешь
укажите несколько полей карты сайта . Поле карты сайта не привязано к какому-либо конкретному
пользовательский агент, за которым могут следить все сканеры, при условии, что сканирование не запрещено.
Например:
пользовательский агент: otherbot запретить: / капуста карта сайта: https://example.com/sitemap.xml карта сайта: https://cdn.example.org/other-sitemap.xml карта сайта: https://ja.example.org/ テ ス ト - サ イ ト マ ッ プ .xml
Группировка строк и правила
Вы можете сгруппировать правила, которые применяются к нескольким пользовательским агентам, повторяя
пользовательских агентов строк для каждого поискового робота.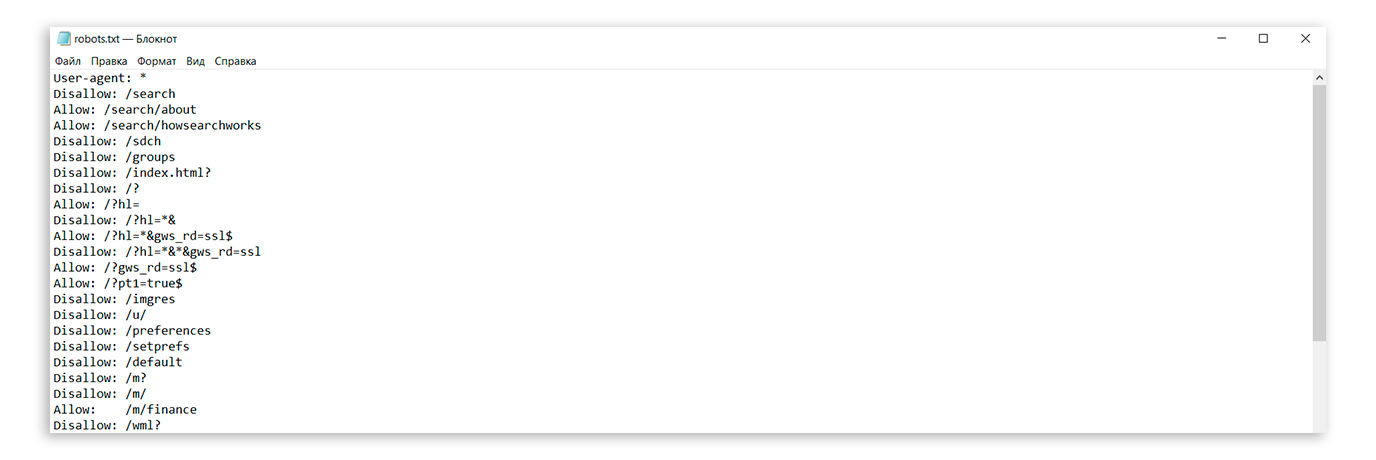
Например:
пользовательский агент: a запретить: / c пользовательский агент: b запретить: / d пользовательский агент: e пользовательский агент: f запретить: / г пользовательский агент: h
В этом примере есть четыре отдельные группы правил:
- Одна группа для пользовательского агента «a».
- Одна группа для пользовательского агента «b».
- Одна группа для пользовательских агентов «e» и «f».
- Одна группа для пользовательского агента «h».
Техническое описание группы см.
раздел 2.1 РЭП.
Порядок приоритета для пользовательских агентов
Для конкретного поискового робота действительна только одна группа. Сканеры Google определяют правильный
группу правил, найдя в файле robots.txt группу с наиболее конкретным пользовательским агентом
который соответствует пользовательскому агенту поискового робота.Остальные группы игнорируются. Весь несоответствующий текст
игнорируются (например, googlebot / 1.2 и googlebot * являются
эквивалент googlebot ). Порядок групп в файле robots.txt:
не имеющий отношения.
Если для определенного пользовательского агента объявлено несколько групп, все правила из
группы, применимые к конкретному пользовательскому агенту, внутренне объединяются в одну группу.
Примеры
Сопоставление
пользовательского агента полей
пользовательский агент: googlebot-news (группа 1) пользовательский агент: * (группа 2) пользовательский агент: googlebot (группа 3)
Вот как поисковые роботы выберут соответствующую группу:
| Группа отслеживаемых на гусеничном ходу | |
|---|---|
| Новости робота Googlebot | googlebot-news следует за группой 1, потому что группа 1 является наиболее специфической группой. |
| Googlebot (Интернет) | googlebot следует за группой 3. |
| Изображения робота Googlebot | googlebot-images следует за группой 2, потому что нет конкретного googlebot-images группа. |
| Googlebot News (при сканировании изображений) | При сканировании изображений за группой 1 следует googlebot-news . googlebot-news не сканирует изображения для Картинок Google, поэтому толькоследует за группой 1. |
| Другой бот (Интернет) | Другие сканеры Google следуют за группой 2. |
| Otherbot (новости) | Другие сканеры Google, которые сканируют новостной контент, но не идентифицируют себя как googlebot-news следуйте за группой 2. Даже если есть запись для связаннойпоисковый робот, он действителен только в том случае, если он специально соответствует. |
Группировка правил
Если в файле robots.txt есть несколько групп, относящихся к определенному пользовательскому агенту,
Сканеры Google внутренне объединяют группы. Например:
пользовательский агент: googlebot-news запретить: / рыба пользовательский агент: * запретить: / морковь пользовательский агент: googlebot-news запретить: / креветка
Сканеры внутренне группируют правила на основе пользовательского агента, например:
пользовательский агент: googlebot-news запретить: / рыба запретить: / креветка пользовательский агент: * запретить: / морковь
Соответствие URL на основе значений пути
Google использует значение пути в директивах allow и disallow в качестве
основа для определения того, применяется ли правило к определенному URL-адресу на сайте.Это работает
сравнение правила с компонентом пути URL-адреса, который поисковый робот пытается получить.
Не 7-битные символы ASCII в пути могут быть включены как символы UTF-8 или как экранированные с помощью процентов
Символов в кодировке UTF-8 на
RFC 3986.
Google, Bing и другие основные поисковые системы поддерживают ограниченную форму подстановочных знаков для
значения пути. Эти:
-
*обозначает 0 или более экземпляров любого допустимого символа. -
$обозначает конец URL-адреса.
| Пример совпадения пути | |
|---|---|
/ | Соответствует корневому URL-адресу и любому URL-адресу нижнего уровня. |
/ * | Эквивалент /. Завершающий подстановочный знак игнорируется. |
/ рыба | Соответствует любому пути, который начинается с Матчей:
Не соответствует:
Примечание. При сопоставлении учитывается регистр. |
/ рыба * | Эквивалент Матчей:
Не соответствует:
|
/ рыба / | Соответствует чему-либо в папке Матчей:
Не соответствует:
|
/*.php | Соответствует любому пути, который содержит Матчей:
Не соответствует:
филиппинских песо |
/*.php $ | Соответствует любому пути, который заканчивается на Матчей:
Не соответствует:
|
/fish*.php | Соответствует любому пути, который содержит Матчей:
Не совпадает: |
Порядок приоритетности правил
При сопоставлении правил robots.txt с URL-адресами сканеры используют наиболее конкретное правило, основанное на
длина его пути. В случае противоречивых правил, в том числе с подстановочными знаками, Google использует
наименее ограничительное правило.
Следующие примеры демонстрируют, какое правило поисковые роботы Google будут применять к заданному URL-адресу.
| Примеры ситуаций | |
|---|---|
http://example.com/page | разрешить: / p запретить: / Применимое правило : |
http://example.com/folder/page | разрешить: / папка disallow: / папка Применимое правило : |
http://example.com/page.htm | разрешить: / страница запретить: /*.htm Применимое правило : |
http://example.com/page.php5 | разрешить: / страница запретить: / *.ph Применимое правило : |
http://example.com/ | разрешить: / $ запретить: / Применимое правило : |
http: // example.com / page.htm | разрешить: / $ запретить: / Применимое правило : |
Отключить индексацию поисковой системой | Webflow University
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, а какие нет на вашем сайте, написав файл robots.txt файл. Вы можете запретить сканирование страниц, папок, всего вашего сайта. Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
В этом уроке
Отключение индексации субдомена Webflow
Вы можете запретить Google и другим поисковым системам индексировать субдомен webflow.io, просто отключив индексирование в настройках вашего проекта.
- Перейдите в Project Settings → SEO → Indexing
- Установите Disable Subdomain Indexing на «Yes»
- Сохраните изменения и опубликуйте свой сайт
A unique robots.txt будет опубликовано только на поддомене, указав поисковым системам игнорировать домен.
Создание файла robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, которые вы не хотите, чтобы поисковые системы сканировали. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать .
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена.Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках своего проекта.
- Перейдите в Project Settings → SEO → Indexing
- Добавьте robots.txt правила, которые вы хотите (см. Ниже)
- Сохраните изменения и опубликуйте свой сайт
Создайте роботов .txt для вашего сайта, добавив правила для роботов, сохранив изменения и опубликовав свой сайт.
Robots.txt rules
Вы можете использовать любое из этих правил для заполнения роботов.txt файл.
- User-agent: * означает, что этот раздел применим ко всем роботам.
- Disallow: запрещает роботу посещать сайт, страницу или папку.
Чтобы скрыть весь ваш сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: / page-name
Чтобы скрыть всю папку страниц
User-agent: *
Disallow: / folder-name /
Чтобы включить карту сайта
Sitemap: https: // your-site.com / sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt
Должен знать
- Содержимое вашего сайта может быть проиндексировано, даже если оно не сканировалось. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент в другом онлайн-контенте. Чтобы страница не проиндексировалась, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex.
- Кто угодно может получить доступ к robots вашего сайта.txt, чтобы они могли идентифицировать ваш личный контент и получить к нему доступ.
Лучшие практики
Если вы не хотите, чтобы кто-либо мог найти определенную страницу или URL на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL. Вместо этого используйте любой из следующих вариантов:
Попробуйте Webflow — это бесплатно
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Остановить индексирование Google — qaru
Я должен добавить сюда свой ответ, поскольку принятый ответ на самом деле не затрагивает проблему должным образом.Также помните, что предотвращение сканирования Google не означает, что вы можете сохранить конфиденциальность своего контента.
Мой ответ основан на нескольких источниках: https://developers.google.com/webmasters/control-crawl-index/docs/getting_started
https://sites.google.com/site/webmasterhelpforum/en/faq—crawling—indexing—ranking
Файл robots.txt управляет сканированием, но не индексированием! Эти два совершенно разных действия выполняются отдельно. Некоторые страницы могут сканироваться, но не индексироваться, а некоторые могут даже индексироваться, но никогда не сканироваться.Ссылка на не просканированную страницу может существовать на других веб-сайтах, что заставит индексатор Google следовать по ней и пытаться проиндексировать.
Вопрос касается индексации, которая собирает данные о странице, чтобы они могли быть доступны через результаты поиска. Его можно заблокировать добавлением метатега:
или добавление HTTP-заголовка в ответ:
X-Robots-Tag: noindex
Если речь идет о сканировании, то, конечно, можно создать роботов.txt и введите следующие строки:
Агент пользователя: *
Запретить: /
Сканирование — это действие, выполняемое для сбора информации о структуре одного конкретного веб-сайта. Например. вы добавили сайт с помощью Инструментов Google для веб-мастеров. Сканер примет это к сведению и посетит ваш веб-сайт, выполнив поиск по запросу robots.txt . Если он ничего не найдет, он будет считать, что может сканировать что угодно (очень важно также иметь файл sitemap.xml , чтобы помочь в этой операции и указать приоритеты и определить частоту изменений).Если он найдет файл, он будет следовать правилам. После успешного сканирования он в какой-то момент запустит индексирование просканированных страниц, но вы не можете сказать, когда …
Важно : все это означает, что ваша страница по-прежнему может отображаться в результатах поиска Google независимо от robots.txt .
Я надеюсь, что по крайней мере некоторые пользователи прочитают этот ответ, и он будет понятен, поскольку очень важно знать, что происходит на самом деле.
php — Google игнорирует мой robots.txt
Цитата из Документов Google для веб-мастеров
Если я заблокирую сканирование страницы Google с помощью файла robots.txt запретить
директива, она исчезнет из результатов поиска?Блокирование сканирования страницы Google может снизить ее
рейтинг или привести к тому, что он со временем исчезнет. Это также может
уменьшить количество деталей, предоставляемых пользователям в тексте под
результат поиска. Это потому, что без содержания страницы поиск
Движок имеет гораздо меньше информации для работы.
–
Однако запрещение robots.txt не гарантирует, что страница не будет
появляются в результатах : Google все еще может принять решение на основе внешних
информация, такая как входящие ссылки, что она актуальна.Если хочешь
чтобы явно заблокировать индексирование страницы, вы должны вместо этого использовать
метатег noindex robots или HTTP-заголовок X-Robots-Tag. В таком случае,
вы не должны запрещать страницу в robots.txt, потому что страница должна
сканироваться, чтобы тег был виден и соблюдался.
Установить заголовок X-Robots-Tag без индекса для всех файлов в папках. Установите этот заголовок из конфигурации вашего веб-сервера для папок. https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag?hl=de
Установить заголовок из Apache Config для файлов pdf:
<Файлы ~ "\.pdf $ ">
Заголовочный набор X-Robots-Tag "noindex, nofollow"
Отключить индексирование каталога / листинг этой папки.
Добавьте пустой index.html с метатегом robots noindex.
Принудительное удаление проиндексированных страниц вручную с помощью инструментов для веб-мастеров.
Вопрос в комментарии: Как запретить все файлы в папке?
// 1) Полностью запретить доступ к папке
<Каталог / var / www / denied_directory>
Заказать разрешить, запретить
// 2) внутри папки поместите файл./ $ / main / [R = 301, L]
сканеров google — индексируется сам контент robots.txt?
сканеры google — индексируется сам контент robots.txt? — Переполнение стека
Присоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено
3к раз
Закрыто. Это вопрос не по теме. В настоящее время он не принимает ответы.
Содержимое моего файла robots.txt фактически индексируется и отображается в результатах поиска Google. Например, это только Google, а не Yahoo.
Я действительно думаю, что Google должен понимать , а не , чтобы проиндексировать содержимое моего файла robots, поскольку он нужен только для того, чтобы указать Google , что не индексировать!
Я что-то упустил?
Создан 08 ноя.
Майкл Майкл
48266 серебряных знаков1010 бронзовых знаков
2
Это нормально.Моя тоже была проиндексирована несколько месяцев назад. Я думаю, это проблема краулера. edit: Кстати, вы можете удалить ссылку на веб-сайте инструментов для веб-мастеров.
Создан 08 ноя.
сашасаша
4,6133 золотых знака3434 серебряных знака5151 бронзовый знак
0
Я бы не рекомендовал запрещать использование роботов.txt из самого себя. Вместо этого вы можете использовать http-заголовок X-Robots-Tag со значением noindex, что предотвратит индексацию файла поисковыми системами.
Это позволит им получить доступ к вашему robots.txt, но предотвратит его отображение в результатах поиска.
Создан 05 дек.
Eywueywu
2,74711 золотых знаков2020 серебряных знаков2424 бронзовых знака
Вы можете добавить Disallow: / robots.txt в файл robots.txt. Я думаю, следует избегать индексации самого файла robots.txt.
Создан 08 ноя.
acmeacme
13.4k66 золотых знаков6767 серебряных знаков104104 бронзовых знака
1
Думаю, что запрет на собственные роботы.txt (если возможно) приведет к тому, что все остальные команды, написанные в нем, также будут игнорироваться ботами.
Создан 28 ноя.
1
Stack Overflow лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie
Настроить параметры
Robots.txt: Как создать идеальный файл для SEO
В этой статье мы расскажем, что такое робот.txt в SEO, как он выглядит и как его правильно создать. Это файл, который отвечает за блокировку индексации страниц и даже всего сайта. Неправильная структура файла — обычная ситуация даже среди опытных SEO-оптимизаторов, поэтому остановимся на типичных ошибках при редактировании robot.txt.
Что такое Robots.txt?
Robots.txt — это текстовый файл, информирующий поисковых роботов о том, какие файлы или страницы закрыты для сканирования и индексации. Документ размещается в корневом каталоге сайта.
Давайте посмотрим, как работает robot.txt. У поисковых систем две цели:
- Для сканирования сети для обнаружения контента;
- Индексировать найденный контент, чтобы показывать его пользователям по идентичным поисковым запросам.
Для индексации поисковый робот посещает URL-адреса с одного сайта на другой, просматривая миллиарды ссылок и веб-ресурсов. После открытия сайта система ищет файл robots.txt. Если сканер находит документ, он сначала сканирует его, а после получения от него инструкций продолжает сканирование страницы.
Если в файле нет директив или он не создается вообще, робот продолжит сканирование и индексацию без учета данных о том, как система должна выполнять эти действия. Это может привести к индексации нежелательного содержания поисковой системой.
Но многие SEO-специалисты отмечают, что некоторые поисковые системы игнорируют инструкции в файле robot.txt. Например, парсеры электронной почты и вредоносные robots. Google также не воспринимает документ как строгую директиву, но рассматривает его как рекомендацию при сканировании страницы.
User-agent и основные директивы
Агент пользователя
У каждой поисковой системы есть свои собственные пользовательские агенты. Robots.txt прописывает правила для каждого. Вот список самых популярных поисковых ботов:
- Google: Googlebot
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
При создании правила для всех поисковых систем используйте этот символ: (*). Например, давайте создадим бан для всех роботов, кроме Bing. В документе это будет выглядеть так:
Пользовательский агент: *
Запрещено: /
Пользовательский агент: Bing
Разрешить: /
Роботы.txt может содержать различное количество правил для поисковых агентов. При этом каждый робот воспринимает только свои директивы. То есть, инструкции для Google, например, не актуальны для Yahoo или какой-либо другой поисковой системы. Исключение будет, если вы укажете один и тот же агент несколько раз. Тогда система выполнит все директивы.
Важно указать точные имена поисковых ботов; в противном случае роботы не будут следовать указанным правилам.
Директивы
Это инструкции по сканированию и индексации сайтов поисковыми роботами.
Поддерживаемые директивы
Это список директив, поддерживаемых Google:
1. Запретить
Позволяет закрыть доступ поисковых систем к контенту. Например, если вам нужно скрыть каталог и все его страницы от сканера для всех систем, то файл robots.txt будет выглядеть следующим образом:
Пользовательский агент: *
Запрещено: / catalog /
Если это для конкретного краулера, то это будет выглядеть так:
Пользовательский агент: Bingbot
Запрещено: / catalog /
Примечание: Укажите путь после директивы, иначе роботы его проигнорируют.
2. Разрешить
Это позволяет роботам сканировать определенную страницу, даже если она была ограничена. Например, вы можете разрешить поисковым системам сканировать только одно сообщение в блоге:
Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Также можно указать robots.txt, чтобы разрешить весь контент:
Пользовательский агент: *
Разрешить: /
Примечание. Поисковые системы Google и Bing поддерживают эту директиву.Как и в случае с предыдущей директивой, всегда указывайте путь после , разрешите .
Если вы ошиблись в robots.txt, запретят и разрешат будут конфликтовать. Например, если вы упомянули:
Пользовательский агент: *
Disallow: / blog / что такое SEO
Разрешить: / blog / что такое SEO
Как видите, URL разрешен и запрещен для индексации одновременно. Поисковые системы Google и Bing будут отдавать приоритет директиве с большим количеством символов.В данном случае это , запретить . Если количество символов одинаково, то будет использоваться директива allow , то есть ограничивающая директива.
Другие поисковые системы выберут первую директиву из списка. В нашем примере это , запрещает .
3. Карта сайта
Карта сайта, указанная в robots.txt, позволяет поисковым роботам указывать адрес карты сайта. Вот пример такого файла robots.txt:
Карта сайта: https: // www.site.com/sitemap.xml
Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Если карта сайта указана в Google Search Console, то этой информации Google будет достаточно. Но другие поисковые системы, такие как Bing, ищут его в robots.txt.
Не нужно повторять директиву для разных роботов, она работает для всех. Рекомендуем записать его в начале файла.
Примечание : Вы можете указать любое количество карт сайта.
Вы также можете прочитать соответствующую статью XML-руководство по файлам Sitemap: лучшие приемы, советы и инструменты.
Директивы без поддержки
1. Задержка сканирования
Раньше директива показывала задержку между сканированиями. Google в настоящее время не поддерживает его, но может быть указан для Bing. Для робота Googlebot скорость сканирования указывается в консоли поиска Google.
Например:
Пользовательский агент: Bingbot
Задержка сканирования: 10
2.Noindex
Для робота Googlebot в файле robots.txt noindex никогда не поддерживался. Мета-теги роботов используются для исключения страницы из поисковой системы.
3. Nofollow
Это не поддерживается Google с прошлого года. Вместо этого используется атрибут URL rel = «nofollow».
Примеры robots.txt
Рассмотрим пример стандартного файла robot.txt:
Карта сайта: https://www.site.com/sitemap.xml
Пользовательский агент: Googlebot
Запретить: / blog /
Разрешить: / blog / что такое SEO
Пользовательский агент: Bing
Запретить: / blog /
Разрешить: / blog / что такое SEO
Примечание: Вы можете указать любое количество пользовательских агентов и директив по вашему желанию.Всегда пишите команды с новой строки.
Почему Robots.txt важен для SEO?
Файл
Robots txt для SEO играет важную роль, поскольку он позволяет вам давать инструкции поисковым роботам, какие страницы вашего сайта следует сканировать, а какие нет. Кроме того, файл позволяет:
- Избегайте дублирования контента в результатах поиска;
- Блокировать закрытые страницы; например, если вы создали промежуточную версию;
- Запретить индексирование определенных файлов, например PDF-файлов или изображений; и
- Увеличьте бюджет сканирования Google.Это количество страниц, которые может сканировать робот Googlebot. Если на сайте их много, то поисковому роботу потребуется больше времени, чтобы просмотреть весь контент. Это может негативно повлиять на рейтинг сайта. Вы можете закрыть неприоритетные страницы со сканера, чтобы бот мог проиндексировать только те страницы, которые важны для продвижения.
Если на вашем сайте нет контента для управления доступом, возможно, вам не потребуется создавать файл robots.txt. Но мы все же рекомендуем создать его, чтобы лучше оптимизировать свой сайт.
Robots.txt и Мета-теги роботов
Мета-теги robots не являются директивами robots.txt; они являются фрагментами HTML-кода. Это команды для поисковых роботов, которые позволяют сканировать и индексировать контент сайта. Они добавляются в раздел страницы.
Мета-теги роботов состоят из двух частей:
- name = ”‘. Здесь нужно ввести название поискового агента, например, Bingbot.
- content = ». Вот инструкции, что должен делать бот.
Итак, как выглядят роботы? Взгляните на наш пример:
Существует два типа мета-тегов роботов:
- Тег Meta Robots: указывает поисковым системам, как сканировать определенные файлы, страницы и подпапки сайта.
- Тег X-robots: фактически выполняет ту же функцию, но в заголовках HTTP. Многие эксперты склоняются к мнению, что теги X-robots более функциональны, но требуют открытого доступа к файлам .php и .htaccess или к серверу. Поэтому использовать их не всегда возможно.
В таблице ниже приведены основные директивы для мета-тегов роботов с учетом поисковых систем.
Содержимое файла robots.txt должно соответствовать мета-тегам robots.Самая распространенная ошибка, которую допускают SEO-оптимизаторы: в robots.txt закрывают страницу от сканирования, а в данных мета-тегов роботов открывают.
Многие поисковые системы, включая Google, отдают приоритет содержанию robots.txt, чтобы важную страницу можно было скрыть от индексации. Вы можете исправить это несоответствие, изменив содержание в метатегах robots и в документе robots.txt.
Как найти Robots.txt?
Robots.txt можно найти во внешнем интерфейсе сайта.Этот способ подходит для любого сайта. Его также можно использовать для просмотра файла любого другого ресурса. Просто введите URL-адрес сайта в строку поиска своего браузера и добавьте в конце /robots.txt. Если файл найден, вы увидите:
Нил Патель
Или откроется пустой файл, как в примере ниже:
Нил Патель
Также вы можете увидеть сообщение об ошибке 404, например, здесь:
MOZ
Если при проверке robots.txt на своем сайте, вы обнаружили пустую страницу или ошибку 404, значит, для ресурса не был создан файл или в нем были ошибки.
Для сайтов, разработанных на базе CMS WordPress и Magento 2, есть альтернативные способы проверки файла:
- Вы можете найти robots.txt WordPress в разделе WP-admin. На боковой панели вы найдете один из плагинов Yoast SEO, Rank Math или All in One SEO, которые генерируют файл. Подробнее читайте в статьях Yoast против Rank Math SEO, Пошаговое руководство по установке плагина Rank Math, Настройка плагинов SEO, Yoast против All in One SEO Pack.
- В Magento 2 файл можно найти в разделе Content-Configuration на вкладке Design.
Для платформы Shopware сначала необходимо установить плагин, который позволит вам создавать и редактировать robots.txt в будущем.
Как создать Robots.txt
Для создания robots.txt вам понадобится любой текстовый редактор. Чаще всего специалисты выбирают Блокнот Windows. Если этот документ уже был создан на сайте, но вам нужно его отредактировать, удалите только его содержимое, а не весь документ.
Вне зависимости от ваших целей формат документа будет выглядеть как стандартный образец robot.txt:
Карта сайта: URL – адрес (рекомендуем всегда указывать)
user – agent: * (или укажите имя определенного поискового бота)
Disallow: / (путь к контенту, который вы хотите скрыть)
Затем добавьте оставшиеся директивы в необходимом количестве.
Вы можете ознакомиться с полным руководством от Google по созданию правил для поисковых роботов здесь.Информация обновляется, если поисковая система вносит изменения в алгоритм создания документа.
Сохраните файл под именем robot.txt.
Для создания файла можно использовать генератор robots.txt.
Инструменты SEO Книга
Основным преимуществом этой услуги является то, что она помогает избежать синтаксических ошибок.
Где разместить Robots.txt?
Файл robots.txt по умолчанию находится в корневой папке сайта. Управлять сканером на сайте.com, документ должен находиться по адресу sitename.com/robots.txt.
Если вы хотите контролировать сканирование контента на субдоменах, например blog.sitename.com, то документ должен находиться по этому URL: blog.sitename.com/robots.txt.
Используйте любой FTP-клиент для подключения к корневому каталогу.
Лучшие практики оптимизации Robots.txt для SEO
- Маски (*) можно использовать для указания не только всех поисковых роботов, но и идентичных URL-адресов на сайте. Например, если вы хотите закрыть от индексации все категории продуктов или разделы блога с определенными параметрами, то вместо их перечисления вы можете сделать следующее:
пользовательский агент: *
Запретить: / blog / *?
Боты не будут сканировать все адреса в подпапке / blog / со знаком вопроса.
- Не используйте документ robots.txt для скрытия конфиденциальной информации в результатах поиска. Иногда другие страницы могут ссылаться на контент вашего сайта, и данные будут индексироваться в обход директив. Чтобы заблокировать страницу, используйте пароль или NoIndex.
- В некоторых поисковых системах есть несколько ботов. Например, у Google есть агент для общего поиска контента — Googlebot и Googlebot-Image, который сканирует изображения. Рекомендуем прописать директивы для каждого из них, чтобы лучше контролировать процесс сканирования на сайте.
- Используйте символ $ для обозначения конца URL-адресов. Например, если вам нужно отключить сканирование файлов PDF, директива будет выглядеть так: Disallow: / * .pdf $.
- Вы можете скрыть версию страницы для печати, так как это технически дублированный контент. Сообщите ботам, какой из них можно сканировать. Это полезно, если вам нужно протестировать страницы с одинаковым содержанием, но с разным дизайном.
- Обычно при внесении изменений содержимое robots.txt кэшируется через 24 часа. Можно ускорить этот процесс, отправив адрес файла в Google.
- При написании правил указывайте путь как можно точнее. Например, предположим, что вы тестируете французскую версию сайта, находящуюся в подпапке / fr /. Если вы напишете такую директиву: Disallow: / fr, вы закроете доступ к другому контенту, который начинается с / fr. Например: / французская парфюмерия /. Поэтому всегда добавляйте «/» в конце.
- Для каждого поддомена необходимо создать отдельный файл robots.txt.
- Вы можете оставлять в документе комментарии оптимизаторам или себе, если вы работаете над несколькими проектами.Чтобы ввести текст, начните строку с символа «#».
Как проверить файл robots.txt
Проверить корректность созданного документа можно в Google Search Console. Поисковая система предлагает бесплатный тестер robots.txt.
Чтобы начать процесс, откройте свой профиль для веб-мастеров.
Выберите нужный веб-сайт и нажмите кнопку «Сканировать» на левой боковой панели.
Нил Патель
Вы получите доступ к сервису роботов Google.txt тестер.
Нил Патель
Если адрес robots.txt уже был введен в поле, удалите его и введите свой собственный. Нажмите кнопку test в правом нижнем углу.
Нил Патель
Если текст изменится на «разрешено», значит ваш файл был создан правильно.
Вы также можете протестировать новые директивы прямо в инструменте, чтобы проверить, насколько они верны. Если ошибок нет, вы можете скопировать текст и добавить его в файл robots.txt документ. Подробные инструкции по использованию сервиса читайте здесь.
Распространенные ошибки в файлах Robots.txt
Ниже приведен список наиболее распространенных ошибок, которые допускают веб-мастера при работе с файлом robots.txt.
- Имя состоит из прописных букв. Файл называется просто robots.txt. Не используйте заглавные буквы.
- Он содержит неверный формат поискового агента. Например, некоторые специалисты пишут имя бота в директиве: Disallow: Googlebot.Всегда указывайте роботов после строки пользовательского агента.
- Каждый каталог, файл или страницу следует записывать с новой строки. Если вы добавите их в один, боты проигнорируют данные.
- Правильно напишите директиву host, если она вам нужна в работе.
Неправильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Правильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Хост: www.sitename.com
5. Неверный заголовок HTTP.
Неправильно:
Content-Type: text / html
Правильно:
Content-Type: text / plain
Не забудьте проверить отчет об охвате в Google Search Console. Там будут отображаться ошибки в документе.
Рассмотрим самые распространенные.
1. Доступ к URL-адресу заблокирован:
Эта ошибка появляется, когда один из URL-адресов в карте сайта заблокирован роботами.текст. Вам необходимо найти эти страницы и внести в файл изменения, чтобы снять запрет на сканирование. Чтобы найти директиву, блокирующую URL, вы можете использовать тестер robots.txt от Google. Основная цель — исключить дальнейшие ошибки при блокировке приоритетного контента.
2. Запрещено в robots.txt:
Сайт содержит контент, заблокированный файлом robots.txt и не индексируемый поисковой системой. Если эти страницы необходимы, вам необходимо снять блокировку, предварительно убедившись, что страница не запрещена для индексации с помощью noindex.
Если вам нужно закрыть доступ к странице или файлу, чтобы исключить их из индекса поисковой системы, мы рекомендуем использовать метатег robots вместо директивы disallow. Это гарантирует положительный результат. Если не снять блокировку сканирования, то поисковая система не найдет noindex, и контент будет проиндексирован.
3. Контент индексируется без блокировки в документе robots.txt:
Некоторые страницы или файлы могут все еще присутствовать в индексе поисковой системы, несмотря на то, что они запрещены в robots.текст. Возможно, вы случайно заблокировали нужный контент. Чтобы исправить это, исправьте документ. В других случаях для вашей страницы следует использовать метатег robots = noindex. Подробнее читайте в статье Возможности ссылок Nofollow. Новая тактика SEO.
Как закрыть страницу из индексации в Robots.txt
Одна из основных задач robots.txt — скрыть определенные страницы, файлы и каталоги от индексации в поисковых системах. Вот несколько примеров того, какой контент чаще всего блокируется от ботов:
- Дублированный контент;
- Страницы пагинации;
- Категории товаров и услуг;
- Контентные страницы для модераторов;
- Интернет-корзины для покупок;
- Чаты и формы обратной связи; и
- Страницы благодарности.
Чтобы предотвратить сканирование содержимого, следует использовать директиву disallow. Давайте рассмотрим примеры того, как можно заблокировать поисковым агентам доступ к различным типам страниц.
1. Если вам нужно закрыть определенную подпапку:
user – agent: (укажите имя бита и добавьте *, если правило должно применяться ко всем поисковым системам)
Disallow: / name – subfolder /
2. Если закрыть определенную страницу на сайте:
user – agent: (* или имя робота)
Disallow: / name –subfolder / page.HTML
Вот пример того, как интернет-магазин указывает запрещающие директивы:
Журнал поисковых систем
Оптимизаторы заблокировали весь контент и страницы, не являющиеся приоритетными для продвижения в результатах поиска. Это увеличивает краулинговый бюджет некоторых поисковых роботов, например Googlebot. Это действие позволит улучшить рейтинг сайтов в будущем, конечно, с учетом других важных факторов.
Мы не рекомендуем скрывать конфиденциальную информацию с помощью директивы disallow, так как вредоносные системы все же могут обойти блокировку.