Содержание
Алгоритм работы над текстом
Сегодня прошло дополнительное занятие трёхдневного курса. На этом занятии я дал те темы, которые мы не успели охватить 2, 3 и 4 марта.
Последняя тема — алгоритм работы над текстом. Она резюмирует основные темы, которые мы проработали, и выстраивает их в систему. Что-то вроде шпаргалки по всему курсу.
Алгоритм новой статьи, рекламы, новости, рассылки, подсказки и заметки
Понять, нужно ли писать вообще
Может, это одна из ситуаций, когда писать не нужно?
Текст работает не всегда. Извиняться за большой промах или выяснять отношения лучше лично.
Изучить предмет под микроскопом
Иногда идея рождается из деталей и тонкостей, на которые никто никогда не смотрел.
Определить контекст
Как читатель столкнется с нашим текстом? Зачем его читать? Что читатель делал, когда вы его отвлекли? Где появился ваш текст?
Занять позицию
Где мы в мире клиента? Чем мы поможем? Можем ли помочь вообще?
Придумать большую идею
Что изменится в голове читателя? Что он поймет из того, чего не знал раньше?
Если это реклама — придумать позиционирование. Что продаем? Как мы это опишем?
Что продаем? Как мы это опишем?
Придумать годный заголовок
Если нужно — еще и подзаголовок. Убедиться, что заголовок подходит ситуации.
Составить примерный план. Отложить его и написать все, что есть в голове
Выложить на лист все «мясо», без ограничений. Сосредоточиться на том, чтобы за час выложить все свои знания по предмету. Пока что не редактировать.
Структурировать
Определить лучший вариант структуры, в зависимости от специфики текста. Это аргументация сложной идеи, история, описание ситуации? Какая здесь нужна структура?
Разложить «мясо» по полочкам. Определить, на каких полочках не хватает «мяса». Исследовать и дописать недостающее.
Жестко отредактировать
— Убрать все не по теме
— Вытравить кислотой заискивание, фальшь, ложь
— Отжать: стоп-слова, слабые глаголы, отглагольные существительные и остальную шелуху
— Насытить потерянные на отжиме моменты. Добавить фактов и цифр
— Исправить синтаксис: выправить абзацы по «правилу капрала», сбалансировать длину предложений и абзацев, добиться контраста, выверить порядок слов
— Отжать еще
— Отложить
— Отжать
— Повторить
Оформить
— Абзацы
— Поля и «воздух»
— Подзаголовки
— Буллиты через тире
— Многоколонники, врезки, цитаты
— Фактоиды
— Кодирование цветом
Полюбоваться
Дать тексту полежать без вашего участия. Спросить мнения коллег. Потестировать.
Спросить мнения коллег. Потестировать.
Отжать
Алгоритм чтения текста сюжетной арифметической задачи Текст научной статьи по специальности «Языкознание и литературоведение»
УДК 373.33:[372.881.161.1+372.851]
Алгоритм чтения текста сюжетной арифметической задачи
М. В. Басалаева
В статье предлагается эффективный для учащихся начальной школы алгоритм чтения текстовой арифметической задачи. Дано описание этапов чтения, составляющих алгоритм действий учащихся. Традиционно выделяемые виды чтения рассматриваются автором методики как части единого процесса, как последовательные этапы деятельности учащихся. На примерах показаны основные принципы работы с алгоритмом.
Ключевые слова: алгоритм чтения текстовой арифметической задачи; понимание учебного текста; интерпретация текста; этапы чтения текста.
Обучение решению задач является одной из центральных проблем для учителя начальной школы. Существует большое количество различных методик для работы над сюжетной арифметической задачей, но все они имеют один общий этап — семантический анализ текста, который представляет наибольшую сложность для детей. По мнению учителей, текст сюжетной задачи сложен для понимания: дети не могут решить задачу, как правило, потому, что не понимают прочитанный текст.
Тексты сюжетных задач были проанализированы нами с нескольких позиций: длина предложения; наличие синтаксических конструкций, сложных для понимания; структурные особенности текста и т. д. Исходя из результатов анализа, мы поставили перед собой задачу по-
иска ответа на вопрос о том, как учащимся начальной школы следует читать «трудный» текст, чтобы он стал понятен.
В разработке алгоритма чтения арифметической задачи мы учитывали традиционно выделяемые в зависимости от целевой установки виды чтения, которые называет, например, С.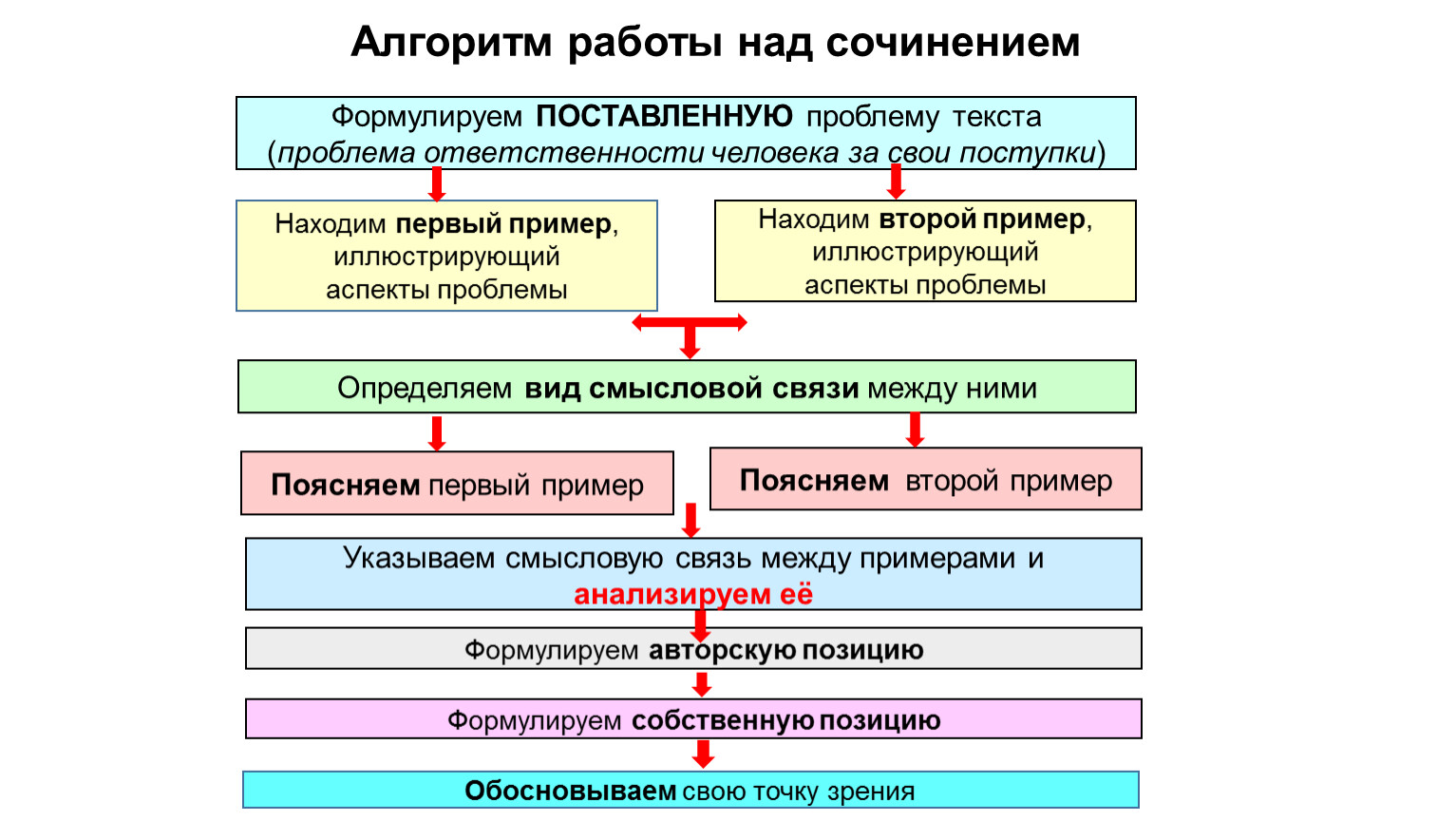 И. Львова. Применительно ко всей совокупности существующих текстов, без специального внимания к таким специфическим текстам, как тексты арифметических задач, различают 4 вида чтения: просмотровое, ознакомительное, изучающее и поисковое. Просмотровое чтение позволяет определить в общих чертах, о чем данный текст. Ознакомительное чтение направлено на извлечение основной информации: необходимо понять не только о чем текст, но и что именно говорится по тому или иному вопросу. Изучающее чтение — полное, точное и адекватное понимание всей содержащейся в тексте информации и критическое осмысление ее. Целью поискового чтения является нахождение в тексте конкретных данных [2, с. 204]. Эту концепцию мы взяли за основу при разработке эффективных методов работы над текстом арифметической задачи на уроке.
И. Львова. Применительно ко всей совокупности существующих текстов, без специального внимания к таким специфическим текстам, как тексты арифметических задач, различают 4 вида чтения: просмотровое, ознакомительное, изучающее и поисковое. Просмотровое чтение позволяет определить в общих чертах, о чем данный текст. Ознакомительное чтение направлено на извлечение основной информации: необходимо понять не только о чем текст, но и что именно говорится по тому или иному вопросу. Изучающее чтение — полное, точное и адекватное понимание всей содержащейся в тексте информации и критическое осмысление ее. Целью поискового чтения является нахождение в тексте конкретных данных [2, с. 204]. Эту концепцию мы взяли за основу при разработке эффективных методов работы над текстом арифметической задачи на уроке.
Текст любой арифметической задачи представляет собой «информационный клубок». В нем чаще всего сведения об объектах, связанных между собой по смыслу, находятся далеко друг от друга, а о несвязанных — близко. В одной из диагностических работ несколько учащихся, оценивая сложность текста арифметической задачи, отметили: «Текст сильно накручен, чтобы понять, надо долго распутывать». Практика работы на уроке показывает, что для адекватного понимания содержания текста арифметической задачи необходимо читать ее несколько раз.
В одной из диагностических работ несколько учащихся, оценивая сложность текста арифметической задачи, отметили: «Текст сильно накручен, чтобы понять, надо долго распутывать». Практика работы на уроке показывает, что для адекватного понимания содержания текста арифметической задачи необходимо читать ее несколько раз.
В связи с этим известные виды чтения будут рассматриваться нами как части единого процесса, как последовательные этапы деятельности учащихся, в то время как традиционно каждый из видов чтения
описывается изолированно от других, в противопоставлении другим, вне связи с ними.
Рассмотрим подробнее, в чем заключаются цели и результат каждого этапа чтения. Предварительно подчеркнем, что цель чтения на каждом этапе определяется, обсуждается учителем и учащимися до чтения.
1 этап — просмотровое чтение. Это первое чтение текста арифметической задачи. В связи с тем, что младшие школьники еще не являются опытными читателями, рекомендуем читать текст два раза подряд. Цель этого этапа чтения обозначается до чтения и заключается в том, чтобы определить в общих чертах, о чем текст. Учащимся можно обозначить эту цель с помощью таких вопросов: «Прочитайте текст задачи и скажите, где происходят события, описанные в задаче? Куда мы попадаем вместе с героями задачи?». Например: «Мы на складе, где конфеты раскладывают по пакетам» или «Мы на длинной улице, которую будут асфальтировать» и т. д. Если учащиеся смогли правильно сформулировать ответ на такие вопросы, можно переходить ко второму этапу.
Это первое чтение текста арифметической задачи. В связи с тем, что младшие школьники еще не являются опытными читателями, рекомендуем читать текст два раза подряд. Цель этого этапа чтения обозначается до чтения и заключается в том, чтобы определить в общих чертах, о чем текст. Учащимся можно обозначить эту цель с помощью таких вопросов: «Прочитайте текст задачи и скажите, где происходят события, описанные в задаче? Куда мы попадаем вместе с героями задачи?». Например: «Мы на складе, где конфеты раскладывают по пакетам» или «Мы на длинной улице, которую будут асфальтировать» и т. д. Если учащиеся смогли правильно сформулировать ответ на такие вопросы, можно переходить ко второму этапу.
2 этап — ознакомительное чтение. Главная цель этого этапа определить и назвать все субъекты (о ком / чем говорится в тексте задачи) и предикаты (что о них говорится). Если субъекты обозначены одушевленными существительными, то цель можно задать с помощью таких вопросов: «Прочитай внимательно текст и ответь на вопрос, кто является героем (героями) этого текста и какие события с ним происходят?» Если речь идет о неодушевленных предметах, то вопрос нужно формулировать с учетом этого. Отметим, что в ходе экспериментальной работы учащиеся называли героями и неодушевленные предметы: карандаши, которые раскладывают по коробкам; грузовики, которые развозят товар и т. д. Этот этап чтения можно завершить записью полученных выводов на доске в любом удобном для понимания виде.
Отметим, что в ходе экспериментальной работы учащиеся называли героями и неодушевленные предметы: карандаши, которые раскладывают по коробкам; грузовики, которые развозят товар и т. д. Этот этап чтения можно завершить записью полученных выводов на доске в любом удобном для понимания виде.
При этом следует учитывать пожелания, соображения детей. Иногда учащиеся предлагали нам выписать эту информацию в виде таблицы, так как было несколько субъектов, иногда в виде цепочки, когда субъект был один, а предикатов несколько. После этого можно переходить к следующему этапу.
3 этап — изучающее или выборочное чтение. Это один из ключевых этапов понимания текста. Именно при выборочном чтении «клубок информации» должен быть распутан. Целью прочтения текста задачи в этом случае является нахождение всех связей между субъектами, объектами. Путь к этой цели лежит через поиск различных средств связи между предложениями в тексте. Ср., например, использование родовидовых пар, когда в тексте говорится о стульях, столах, диванах, а в вопросе содержится слово мебель. Эту связь должны обнаружить учащиеся. Для того чтобы дать импульс к такому поиску, можно предложить детям вопрос о том, какие субъекты связаны между собой в этом тексте и как они связаны. После успешного прохождения этапа на доске можно отметить найденные связи. По окончании этой работы должно прийти понимание текста.
Ср., например, использование родовидовых пар, когда в тексте говорится о стульях, столах, диванах, а в вопросе содержится слово мебель. Эту связь должны обнаружить учащиеся. Для того чтобы дать импульс к такому поиску, можно предложить детям вопрос о том, какие субъекты связаны между собой в этом тексте и как они связаны. После успешного прохождения этапа на доске можно отметить найденные связи. По окончании этой работы должно прийти понимание текста.
4 этап — работа с прочитанным текстом. Это заключительный этап, на котором то, что понятно, будет выражено, как говорил А. А. Леонтьев, иначе. Цель этого этапа — создание собственной интерпретации исходного текста. Используя имеющиеся на доске записи, учащиеся описывают сами ту ситуацию, которая фигурирует в задаче — создают новый собственный текст. Цель можно сформулировать, например, так: «Теперь мы разобрались в событиях, которые описаны в задаче. Давайте расскажем эту историю сами так, чтобы события в ней описывались по порядку, а то, что раньше было спрятано, стало бы понятно». Интерпретацией исходного текста может быть пересказ, минитекст, концепт или любой другой вторичный текст. Важно, чтобы он был понятнее исходного. События в нем происходили последователь-
Интерпретацией исходного текста может быть пересказ, минитекст, концепт или любой другой вторичный текст. Важно, чтобы он был понятнее исходного. События в нем происходили последователь-
но, связанные между собой субъекты находились рядом, текст имел бы привычную трехчастную структуру. Отметим, что получившаяся интерпретация, скорее всего, будет длиннее исходного текста. Варианты интерпретаций можно писать на доске для сравнения с оригиналом. В процессе экспериментальной работы мы анализировали разные варианты интерпретаций одного текста и обсуждали с детьми их особенности. Важно, чтобы в результате обсуждения учащиеся поняли, что интерпретацию нельзя расценивать как текст, превосходящий по качеству исходный текст задачи. Новый текст просто другой, он более понятен, но это не значит, что исходный текст плохой. Он сложный, в нем «спрятана» информация, однако именно такие тексты помогают развивать речь и мышление.
Приведем описание работы с алгоритмом на примере конкретного текста: «Улицу длиной 672 м и шириной 13 м покрыли асфальтом, расходуя на каждый квадратный метр 39 кг асфальта. Сколько асфальта потребовалось?» [1, с. 58].
Сколько асфальта потребовалось?» [1, с. 58].
1 этап. Определение предмета речи. Учащиеся должны представить общую картину описанного в тексте события. Результат может быть сформулирован так: «Этот текст о том, как улицу покрывали асфальтом» или «Мы на улице, которую будут покрывать асфальтом».
2 этап. Нахождение всех субъектов и предикатов. На доске выписываем все информационные единицы, которые найдем в тексте задачи. Получается приблизительно следующая запись:
• улицу асфальтировали;
• длина улицы 672 метра;
• ширина улицы 13 метров;
• на каждый квадратный метр укладывали 39 кг асфальта.
3 этап. Установление связей между записанными на доске данными. Учащиеся должны провести связи между длиной улицы, ее шириной и информацией о «39 кг на квадратный метр асфальта». Обнаружива-
Учащиеся должны провести связи между длиной улицы, ее шириной и информацией о «39 кг на квадратный метр асфальта». Обнаружива-
ем «неявную информацию»: квадратные метры могут быть связаны с длиной и шириной через понятие площади: у улицы есть некоторая площадь, на которую укладывали асфальт. В тексте об этом понятии не упоминается — эта информация «скрыта».
4 этап. Интерпретация текста. Один из вариантов интерпретации может быть таким: «Улицу покрывали асфальтом. Длина улицы 672 метра, а ширина 13 метров. Всю площадь улицы покрывали асфальтом. На каждый квадратный метр площади укладывали 39 кг асфальта. Сколько всего кг асфальта понадобилось?» Предложения, выделенного курсивом, может не быть. Важно, что в данной интерпретации обозначена связь, которая была скрыта в исходном тексте.
В заключение отметим, что, прежде чем использовать алгоритм, необходимо объяснить учащимся, почему именно так следует читать текст арифметической задачи, убедить их в том, что это действительно необходимо. Такой шаг полезен для того, чтобы сформировать у детей серьезный настрой на работу над текстом задачи. На основе предложенного алгоритма в ходе его практической реализации можно разработать совместно с учащимися памятку, о том, как читать текст арифметической задачи. Например, в процессе экспериментальной работы учащиеся разработали такой вариант памятки:
Такой шаг полезен для того, чтобы сформировать у детей серьезный настрой на работу над текстом задачи. На основе предложенного алгоритма в ходе его практической реализации можно разработать совместно с учащимися памятку, о том, как читать текст арифметической задачи. Например, в процессе экспериментальной работы учащиеся разработали такой вариант памятки:
Как я читаю текст задачи
1. Я читаю текст два раза. Отвечаю коротко на вопрос, о чем этот текст.
2. Читаю еще раз. Нахожу всю информацию, которая есть в задаче. Выписываю или запоминаю.
3. Определяю, как связана между собой эта информация. Ищу доказательства в тексте.
4. Рассказываю текст по-своему снова так, чтобы он был последовательным и понятным.
Учащиеся под руководством учителя работали с помощью этого алгоритма над пониманием текстов арифметических задач на уроках русского языка. Школьники знали, что цель этой работы — точно понять текст, а не решить задачу. Однако многие отмечали: если текст понятен, то решить будет нетрудно. Применяя алгоритм, мы не ставили цель решить задачу. Наша цель состояла в том, чтобы школьники освоили прием «активного понимания» — понимания, которое происходит не само по себе при чтении, а в результате определенных действий. Работа с текстом, построенная таким образом, является одним из способов развития речи учащихся.
Литература
1. Рудницкая В. Н. Математика : учебник для учащихся 4 класса общеобразовательных учреждений / В. Н. Рудницкая, Т. В. Юдачева. — Москва : Вентана-Граф, 2005. — 160 с.
2. Львова С. И. Русский язык : сборник заданий : 9 класс / С. И. Львова. — Москва : Эксмо, 2009. — 304 с.
Львова С. И. Русский язык : сборник заданий : 9 класс / С. И. Львова. — Москва : Эксмо, 2009. — 304 с.
© Басалаева М. В., 2012
Algorithm for Reading Texts of Word Arithmetic Problems
M. Basalaeva
The article offers an algorithm for reading the text of a word arithmetic problem which is effective for elementary school pupils. The author describes all stages of reading that constitute the algorithm of pupils’ actions. The algorithm inventor considers the traditionally distinguished kinds of reading as parts of one process, as successive stages of pupils’ activity. Basic principles of work with the algorithm are shown by examples.
Key words: algorithm for reading a word arithmetic problem; academic text understanding; text interpretation; stages of text reading.
Басалаева Мария Владиславовна, аспирант, кафедра русского языка и методики преподавания, Красноярский государственный педагогический университет им. В. П. Астафьева (Красноярск), [email protected].
Basalaeva, M., post-graduate student, Department of Russian Language and Teaching Methods, Krasnoyarsk State Pedagogical University named after V P. Astafiev (Krasnoyarsk), m.basalaeva @ mail.ru.
Зачем нужны интегральный и дифференциальный алгоритмы чтения
Автор: Иpинa Oлeгoвнa Tюpинa, кандидат социологических наук, вeдущий научный сотpyдник Института социoлoгии Российской академии наук.
Чтение может быть представлено как следующие друг за другом действия мозга по обработке частей материала, содержащего информацию. Любое начинание требует определенного планирования, а следовательно, имеет алгоритмичную структуру.
В процессе своей деятельности человек соблюдает правила, без которых эта деятельность будет неразумной. Последовательность этих правил представляет собой алгоритм. Поэтому перед тем как приступить к знакомству с текстом, необходимо определить вариант чтения. В результате исследований выделены пять способов чтения:
- Углубленное чтение.
- Собственно быстрое чтение.
- Выборочное чтение.
- Чтение-просмотр.
- Чтение-сканирование.
Углубленное чтение — это такой процесс, когда читатель изучает все тонкости, содержащиеся в тексте, и анализирует их. Углубленное чтение наиболее подходит для изучения какого-либо предмета. Читатель, опираясь на ранее полученную информацию и собственный опыт, перерабатывает текст критически, что дает возможность лучшего понимания замысла автора. Такой вид чтения способствует также более глубокому запоминанию текста, так как у читателя формируются определения более близкими ему языковыми средствами.
Быстрое чтение характеризуется тем, что при достаточном уровне владения этим методом, оно обладает всеми достоинствами углубленного чтения при большой скорости обработки информации.
Выборочное чтение является вариантом быстрого чтения. Оно подразумевает чтение фрагментов текста, которые представляют непосредственную ценность для читателя. Он видит весь текст, но пропускает те места, которые либо были изучены ранее, либо не несут полезной на данный момент информации. Такое чтение по скорости превосходит быстрое, так как углубленно изучаются только отдельные части текста. Выборочное чтение уместно при повторном изучении материала.
Чтение-просмотр полезно при определении ценности текста. Читатель должен получить представление о содержании в сжатые сроки.
Сканирование представляет собой вид чтения-просмотра. Объем информации, извлекаемой при таком чтении, крайне невелик. Это может быть отдельное слово, дата или цифра.
Таким образом, эффективным и быстрым чтение становится в том случае, когда все его виды используются читателем в рациональном сочетании. Поэтому нельзя отождествлять быстрое чтение с выборочным, что часто ошибочно делается неопытными читателями.
Поэтому нельзя отождествлять быстрое чтение с выборочным, что часто ошибочно делается неопытными читателями.
Интегральным этот алгоритм назван потому, что он применяется ко всему тексту. Текст является продуктом мыслительной деятельности человека. Чтение означает процесс общения автора и читателя. При этом действуют законы языка, на котором создан текст, и у читателя начинают действовать психические процессы по распознаванию языковой системы.
Такие действия требуют определенной организации. Интегральный алгоритм помогает решить эту задачу. Он является единым способом усвоения информации.
Блок-схема интегрального алгоритма чтения выглядит так:
- Наименование (книги, статьи).
- Автор.
- Источник и его данные (год, №).
- Основное содержание, тема.
- Фактографические данные.
- Особенности излагаемого материала, которые кажутся спорными, критика.
- Новизна излагаемого материала и возможности его использования в практической работе.


Интегральный алгоритм чтения — это последовательные блоки, помогающие выстроить процесс чтения с максимальной эффективностью.
Сведения, содержащиеся в первых четырех блоках, не требуют комментариев. Пятый блок состоит из фактографических данных в письменном виде, фактов, распознавание их в тексте и понимание.
Шестой и седьмой блоки содержат понятия «спорные материалы, их критическое осмысление», «новая информация». В процессе чтения использование этих блоков подразумевает наличие у читателя определенной базы знаний. Читатели могут иметь разную степень подготовки и предварительный опыт. Более подготовленному человеку излагаемый материал может показаться лишним, так как он ему уже хорошо известен. Обладающий же глубокими знаниями в данной области читатель может и не согласиться с автором.
Таким образом, по мере усложнения обрабатываемых по рекомендациям блоков информации включаются дополнительные возможности головного мозга по ее осмыслению, и в этом состоит творческий процесс чтения.
Блоки интегрального алгоритма помогают организовать память в виде специальных отделов, в которые поступает на хранение информация после ее анализа на соответствие тому или иному блоку. Творчески подходя к освоению навыков быстрого чтения, читатель и сам может создать модель интегрального алгоритма в виде изображения.
Чтобы применять эту модель на практике, необходимо соблюдать некоторые правила. Перед тем как погрузиться в изучение текста, нужно вызвать в памяти блоки алгоритма. Этим действием программируется автоматическая способность использования алгоритма в процессе чтения.
Первые три блока схемы алгоритма воспроизводятся памятью без особых усилий, поскольку они наименее информативны. Дальнейшее знакомство с текстом может принести информацию, которая по результатам осмысления отправится в четвертый блок. Такие данные могут содержаться, например, в предисловии книги. Конкретные сведения (имена, даты, результаты статистических исследований) составят фактографический материал пятого блока.
При чтении большое значение имеет способность критически воспринимать изложенные автором соображения. Такая информация является содержанием шестого блока. Неизвестные ранее читателю сведения, которые воспринимаются им как необходимые для своей деятельности, отправляются в седьмой блок.
После прочтения всего текста вновь нужно обратиться к мысленному воспроизведению рисунка схемы интегрального алгоритма. Это прием своеобразного повторения пройденного материала. Происходит более глубокое понимание смысла текста и более стойкое отражение в памяти.
При традиционном чтении несистемная обработка текста приводит к неполному его пониманию: читатель вновь вынужден обращаться к ранее прочитанным фрагментам. Следование алгоритму активизирует мышление и способствует восприятию текста после первого прочтения. Применение метода интегрального алгоритма чтения способствует, таким образом, повышению скорости освоения текста в несколько раз.
Быстрый метод чтения подразумевает не только скорость изучения текста, но и полное понимание прочитанного. Необходимые в этом навыки приобретаются упражнениями, разработанными с помощью дифференциального алгоритма чтения.
Необходимые в этом навыки приобретаются упражнениями, разработанными с помощью дифференциального алгоритма чтения.
Интегральный алгоритм применяется ко всему тексту. Но для каждого фрагмента текста такой метод слишком громоздок, и потребуется слишком много времени, чтобы разработать свой алгоритм для каждой части.
Дифференциальный алгоритм решает эту задачу. Он представляет собой следующую парадигму:
выделение ключевых слов — выявление смысловых рядов — выявление цепи значений.
То есть его функция — разделение (дифференциация) текста на элементы.
Дифференциальный алгоритм имеет структуру, подобную структуре интегрального, но применяемую к значительно меньшему объему текста.
Применять его на практике можно следующим образом. Вначале внимание концентрируется на той части текста, которая представляется законченной по смыслу. В этом случае отмеченная часть может содержать в себе несколько абзацев. Затем происходит заполнение первого блока дифференциального алгоритма путем определения ключевых слов.
Выделенная лексическая единица описывает какой-либо предмет или явление, его характерные признаки. Служебные части речи не могут быть ключевыми словами. Также и местоимения употребляются только для обозначения уже выделенных в предыдущем тексте ключевых слов.
Выявленные ключевые слова помогают составить содержание второго блока, определяя смысловые ряды. Это такие ряды, которые образуются связанными друг с другом ключевыми словами и некоторыми второстепенными. Эти ряды являются золотым ядром печатного материала. В свою очередь, они делятся на именные, предикативные и фактографические.
Именные ряды несут номинативную функцию, то есть называют явление или объект. Вообще, смысловой ряд представляет собой сочетание двух слов. Примером именного ряда может служить сочетание «современный компьютер». Это сочетание может быть выделено из более сложной синтаксической единицы — «компьютер, обладающий в данное время наивысшими возможностями в скорости обработки информации и выдачи результата». Название описанному объекту дает вышеприведенный именной ряд.
Название описанному объекту дает вышеприведенный именной ряд.
Весь лексический материал текста преобразуется в смысловое ядро, занимающее гораздо меньший объем и, соответственно, требующий меньше времени для понимания.
Перед читателем стоит задача уяснить разницу между двумя вариантами сжатия текста. В одном случае в памяти фиксируются смысловые ряды в неизменной форме, в другом те же ряды представляют собой сочетания слов в нескольких синонимичных вариантах.
Таким образом, подготавливается основа не только для сжатия текста путем сокращения количества слов, но и для понимания прочитанного на качественно новом уровне. На этой стадии происходит заполнение третьего блока дифференциального алгоритма. Мыслительный процесс направлен на то, чтобы преобразовать полученную информацию в авторском изложении в свою привычную систему выделения значений слов.
Освоение метода дифференциального алгоритма подобно упражнениям с интегральным алгоритмом. Вначале в памяти должно быть закреплено содержание блоков и порядок их расположения друг за другом.
Затем нужно подобрать две страницы текста научно-популярного жанра и приступить к неторопливому чтению, отмечая части по алгоритму. Выделенные связанные значения образуют фрагменты текста, которые несут основной смысл, заложенный в него автором. Это то, что называется доминантой. Доминанта перекодируется читателем в привычную ему систему языковых единиц.
Таким образом, достигается конечная цель изучения текста в полном масштабе.
Научитесь наконец-то быстро читать изучив курс «Техники скорочтения»:
Техники скорочтения: практический интерактивный мультимедийный дистанционный курс
Алгоритм работы с текстом (составление плана
Просмотр содержимого документа
«Алгоритм работы с текстом (составление плана — конспекта)»
Составление плана — конспекта.
КОНСПЕКТ – это краткая запись содержания текста (устного или письменного)
ВИДЫ КОНСПЕКТОВ: план – конспект, цитатный, свободный, тематический, конспект – кластер (появился сравнительно недавно).
ОСНОВНЫЕ ТРЕБОВАНИЯ К КОНСПЕКТУ: логичность изложения материала, краткость, убедительность.
Тема – это то, о чём говорится в тексте.
Предмет речи – это то, что говорится об этом о чём.
Основная мысль – это то, что автор хочет сказать нам.
Например:
№ п/п | Тема (может быть одна) | Предмет речи (конкретизирует высказывание) | Основная мысль (как правило, выражает отношение автора к изображаемому, говорит о том, что тревожит автора и т.д.) |
Урок | Урок русского языка | Урок русского языка формирует навыки грамотного письма. | |
Урок | Урок литературы | Урок литературы формирует навыки связной речи. | |
Урок | Урок жизни | Урок жизни – это продолжительный и очень интересный урок. |
ПЛАН — КОНСПЕКТ – это сжатый пересказ прочитанного или услышанного в форме плана
ОСНОВНЫЕ ТРЕБОВАНИЯ К ПЛАНУ — КОНСПЕКТУ: логичность изложения материала, краткость, изложение только основных фактов, событий, мыслей и т.д., важных для понимания основной мысли.
ЭТАПЫ КОНСПЕКТИРОВАНИЯ:
1.Прочитайте текст, выписывая слова с непонятным для себя лексическим значением и неизвестные имена и даты.
2.Обращаясь к словарю и/или сети ИНТЕРНЕТ, найдите информацию о неизвестных людях и датах, найдите и дайте объяснение выписанным словам,
3.Прочитайте текст по абзацам, выделив тему, предмет речи и основную мысль.
4.Составьте план или воспользуйтесь готовым.
5.Разъсните кратко каждый пункт плана
6.Сформулируйте и запишите вывод
7.Прочитайте конспект ещё раз и проверьте, все ли части конспекта объединены одной темой, понятен ли вам ход рассуждения. Если да, то вы молодец, если нет – начните сначала!
Алгоритм письменного перевода
Как научиться переводить: алгоритм письменного перевода с английского на русский язык
Перевод текста с английского языка на русский, — на первый взгляд, простая задача. Во многих случаях для понимания сути текста, конечно, достаточно технического перевода — скопировать текст в Google или Yandex переводчик. Однако для полноценного перевода текста на неадаптированном английском, например, этого далеко недостаточно. В настоящем полноценном переводе нужно передать не только смысл, содержание текста, но и воспроизвести его особенности — тип, стиль, передать авторские метафоры, иронию и тому подобное.
Для того, чтобы научиться правильно переводить, рассмотрим алгоритм письменного перевода текста с английского на русский язык. Весь процесс перевода можно условно разделить на два этапа: осмысление и воспроизведение текста. Каким бы странным это не казалось, но сначала нужно поработать с текстом без словарей или онлайн переводчиков (или с их минимальным использованием).
The slovenliness of our language makes it easier for us to have foolish thoughts / George Orwell /
И только после этого приступать непосредственно к переводу.
Неряшливость нашего языка способствует появлению у нас глупых мыслей (Дж. Оруэлл)
Итак, обо всем подробнее.
Минимальные этапы перевода — план:
1. Осмысление текста.
Первое прочтение — знакомые слова — тема — стиль — тип.
Второе прочтение — образ текста
2. Воспроизведение текста.
Перевод — слово — предложение — абзац.
И третье прочтение.
ОСМЫСЛЕНИЕ ТЕКСТА
Первое прочтение. Специалисты в области перевода советуют: «Не думайте о том, что вы читаете на другом языке, постарайтесь абстрагироваться и просто понять смысл текста».
При этом опирайтесь на знакомые слова. Не спешите говорить, что не очень хорошо знаете английский. Даже те, кто никогда не сталкивался с английской речью, знают несколько сотен английских слов. Да, это правда. Это слова, которые пришли в русский из английского, например, бизнес, менеджер, мерчендайзер и интернациональные слова, которые пришли и в английский и в русский из латинского, греческого или французского языков, например, алгебра, география, музей, радио.
Также вы можете проверить свой словарный запас на специальных сайтах.
Знакомые слова свяжите в общую тему. Это облегчит перевод, ограничив словарь до узкого круга слов, например: home, sister, daddy, sweet… — тема текста очевидно «семья». Ограничение всех значений слов и фраз до определенной темы поможет вам на следующих этапах при выборе нужного значения из десятков возможных.
Затем определите тип текста:
повествование (рассказ о каких-либо событиях, действиях во времени),
описание (перечисление признаков или характеристик чего-либо — предмета, явления, места),
рассуждение (главным признаком которого будет доказательство чего-либо, указание причин, убеждение читателя или слушателя).
После этого узнайте стиль текста:
научный (который отличается наличием терминов, подчеркнутой логичностью изложения и отсутствием эмоций),
официально-деловой (в котором также важна информация, отсутствуют эмоции и оценка, но меньшее количество терминов),
публицистический стиль (его цель убеждение читателя, воздействие на него теперь уже всеми средствами — логикой и эмоциональностью),
художественный (где образность, метафоричность выходит на первый план, а логичность и последовательность отодвигаются на второй), и разговорный стиль текста (отличающийся простотой, непринужденностью и эмоциями).
Второе прочтение направлено на формирование мысленного образа текста — того, как все прочитанное на иностранном языке, можно сказать на своем. То есть знакомые слова связанные с темой, стилем и типом текста формируют его образ.
ВОСПРОИЗВЕДЕНИЕ ТЕКСТА
Далее переходим к воспроизведению текста — изложению того образа текста на английском, который сложился в нашем мозгу, на русский язык.
Перевод — слово. Найдите в словарях эквиваленты незнакомых слов или сочетаний, основываясь на сложившемся образе текста. самыми удобными и популярными словарями считаются:
lingvo-online.ru — удобный качественный поиск слов, устойчивые сочетания с ними и конкретные примеры, в которых встречается это слово.
dic.academic.ru, удобство которого в поиске значений по десяткам специализированных словарей, например, научный, экономический, политический и другие.
multitran.ru ценится за то, что варианты переводов редких слов и выражений здесь оставляют профессиональные переводчики, которые с этими словами уже сталкивались в практике. Здесь есть живой форум, где можно найти решения сложных ситуаций перевода.
Для еще более продвинутых переводов можно использовать толковые словари которые расшифровывают, объясняют значение английского слова или выражения более простыми английскими же словами: чаще других я использую urbandictionary.com — многие, в том числе самые свежие, сленговые выражения объясняются именно здесь.
Можно обратить внимание и на dictionary.cambridge.org, thefreedictionary.com.
На выбор значения слов и сочетаний влияют:
1) Контекст.
2) Метафоры, Идиомы.
3) Многозначность.
1) Контекст — окружение переводимого слова или фразы.
Например:
the theory of Einstein — теория Эйнштейна
the theory of Christ — учение Христа.
Одно слово переводится по-разному в разном окружении.
2) Метафоры, Идиомы. Слова и фразы в переносном значении переводятся эквивалентными — в словарях нужно искать целую фразу или пытаться понять тот переносный смысл, который вложил в него автор.
Например: I’ll move heaven and earth to achieve my goal — Я горы сверну за свою цель. Посмотрите: слова сворачивать в оригинале нет совсем, но мы видим, что предложение — «Я буду двигать небеса и землю чтобы достичь своей цели» — звучит не совсем по-русски и ищем то, что как бы выпадает из остального окружения — «буду двигать небеса и землю». Находим, что это идиома, фразеологизм и у нее есть конкретный словарный эквивалент «горы сверну».
3) Многозначность. Здесь нам и пригодится ограничение темы, которое мы сделали ранее на втором этапе, когда составляли мысленный образ текста. Опираясь на этот образ, мы и выбираем из десятков значений самое подходящее.
Например:
Some sort of religious thing? — Из религиозных соображений?
And then he did that odd thing. — И тут он сделал очень странную вещь.
Janey looked around the room for the nearest thing with which to hit her. — Джейни принялась оглядывать комнату в поисках тяжелого предмета.
Кстати, самым многозначным словом в английском является set у которого 127 значений.
Игнорирование этих трех показателей — контекста, переносного смысла и многозначности — можно легко посмотреть. Копируйте текст в онлайн переводчик и получите технический перевод — набор слов, не всегда связанный и часто бессмысленный. Почему? Подробности здесь.
Перевод — предложение. Переходим к следующему этапу и связываем знакомые слова и эквиваленты незнакомых (найденные в словарях только что) в предложения.
При этом помним, что в английском языке фиксированный порядок слов, в русском свободный.
Поэтому при выборе значения слова нужно смотреть на его место в предложении.
В русском: мама мыла раму — раму мыла мама — мыла раму мама.
В английском: mother washed frame, frame washed mother (от перемены порядка слов изменяется смысл).
Особое внимание — на глаголах. Глаголы в английском имеют ряд уникальных особенностей: существуют фразовые глаголы (get after — преследовать, take after — быть похожим и т.д.), которых нет в русском.
В английском 16 времен (простые, длительные, совершённые) — в русском три.
Затем переходим к составлению предложений в абзацы, чтобы выразить более крупную мысль в тексте. То, что не удалось сказать в одном предложении, например, шутку или авторскую метафору, можно перенести в другое место абзаца, сохранив оригинальную идею.
И наконец, третье прочтение — теперь уже своего перевода. Прочитайте получившийся текст, исправьте все ошибки (орфографические, грамматические, пунктуационные). Кроме встроенной в ворд функции проверки текста, существуют онлайн сервисы. Например text.ru.
В получившемся переводе обратите внимание на соответствие: смысла текста, общей тематики, типа, стиля, учтен ли контекст при переводе, правильно ли переданы авторские метафоры и идиомы и выбраны значения многозначных слов.
Очень важно. Перед прочтением получившегося перевода, нужно на время отвлечься от текста. В идеале выпить чашечку кофе или прогуляться. Третье прочтение должно быть «со стороны».
© Обжорин Алексей, 2015
подходы, алгоритмы, рекомендации и перспективы / Хабр
Ежедневно каждый из нас сталкивается с огромным информационным потоком. Нам часто необходимо изучить множество объемных текстов (статей, документов) в ограниченное время. Поэтому в области машинного обучения естественным образом родилась задача автоматического составления аннотации текста.
У нас в компании мы активно работаем над автореферированием документов, в эту статью не стал включать все подробности и код, но описал основные подходы и результаты на примере нейтрального датасета: 30 000 футбольных спортивных новостных статей, собранных с информационного портала «Спорт-Экспресс».
Итак, суммаризацию можно определить, как автоматическое создание краткого содержания (заголовка, резюме, аннотации) исходного текста. Существует 2 существенно отличающихся подхода к этой задаче: экстрактивный и абстрактивный.
Экстрактивная суммаризация
Экстрактивный подход заключается в извлечении из исходного текста наиболее «значимых» информационных блоков. В качестве блока могут выступать отдельные абзацы, предложения или ключевые слова.
Методы данного подхода характеризует наличие оценочной функции важности информационного блока. Ранжируя эти блоки по степени важности и выбирая ранее заданное их число, мы формируем итоговое резюме текста.
Перейдем же к описанию некоторых экстрактивных подходов.
Экстрактивная суммаризация на основе вхождения общих слов
Данный алгоритм очень прост как для понимания, так и дальнейшей реализации. Здесь мы работаем только с исходным текстом, и по большому счету у нас отсутствует потребность в обучении какой-либо модели извлечения. В моем случае извлекаемые информационные блоки будут представлять собой определенные предложения текста.
Итак, на первом шаге разбиваем входной текст на предложения и каждое предложение разбиваем на токены (отдельные слова), проводим для них лемматизацию (приведение слова к «канонической» форме). Этот шаг необходим для того, чтобы алгоритм объединял одинаковые по смыслу слова, но отличающиеся по словоформам.
Затем задаем функцию схожести для каждой пары предложений. Она будет рассчитываться как отношение числа общих слов, встречающихся в обоих предложениях, к их суммарной длине. В результате мы получим коэффициенты схожести для каждой пары предложений.
Предварительно отсеяв предложения, которые не имеют общих слов с другими, построим граф, где вершинами являются сами предложения, ребра между которыми показывают наличие в них общих слов.
Далее ранжируем все предложения по их значимости.
Выбирая несколько предложений с наибольшими коэффициентами и далее сортируя их по номеру появления в тексте, получаем итоговое резюме.
Экстрактивная суммаризация на основе обученных векторных представлений
При построении следующего алгоритма уже использовались ранее собранные данные полных текстов новостей.
Слова во всех текстах разбиваем на токены и объединяем в список. Всего в текстах оказалось 2 270 778 слов, среди которых уникальных — 114 247.
С помощью популярной модели Word2Vec для каждого уникального слова найдем его векторное представление. Модель присваивает каждому слову случайные вектора и далее на каждом шаге обучения, «изучая контекст», корректирует их значения. Размерность вектора, которая способна «запомнить» особенность слова можно задать любую. Исходя из объема имеющегося датасета, будем брать векторы, состоящие из 100 чисел. Также отмечу, что Word2Vec является дообучаемой моделью, что позволяет подать на вход новые данные и на их основе скорректировать уже имеющиеся векторные представления слов.
Для оценки качества модели применим метод понижения размерности T-SNE, который итеративно построит отображение векторов для 1000 самых употребляемых слов в двумерное пространство. Полученный график представляет собой расположение точек, каждая из которых соответствует определенному слову таким образом, что схожие по смыслу слова располагаются близко друг к другу, а различные наоборот. Так в левой части графика располагаются названия футбольных клубов, а точки в левом нижнем углу представляют собой имена и фамилии футболистов и тренеров:
После получения обученных векторных представлений слов можно переходить к самому алгоритму. Как и в предыдущем случае, на входе у нас текст, который мы разбиваем на предложения. Токенизируя каждое предложение, составляем для них векторные представления. Для этого берем отношение суммы векторов для каждого слова в предложении к длине самого предложения. Здесь нам помогают ранее обученные векторы слов. При отсутствии слова в словаре к текущему вектору предложения прибавляется нулевой вектор. Тем самым мы нивелируем влияние появления нового слова, отсутствующего в словаре, на общий вектор предложения.
Далее составляем матрицу схожести предложений, которая использует формулу косинусного сходства для каждой пары предложений.
На последнем этапе на основе матрицы схожести также создаем граф и выполняем ранжирование предложений по значимости. Как и в предыдущем алгоритме, получаем список отсортированных предложений по их значимости в тексте.
В конце изображу схематично и еще раз опишу основные этапы реализации алгоритма (для первого экстрактивного алгоритма последовательность действий абсолютно такая же, за исключением того, что нам не нужно находить векторные представления слов, а функция сходства для каждой пары предложений вычисляется на основе появления в них общих слов):
- Разбиение входного текста на отдельные предложения и их обработка.
- Поиск векторного представления для каждого предложения.
- Вычисление и сохранение в матрице подобия сходства между векторами предложений.
- Преобразование полученной матрицы в граф с предложениями в виде вершин и оценками подобия в виде ребер для вычисления ранга предложений.
- Выбор предложений с наивысшей оценкой для итогового резюме.
Сравнение экстрактивных алгоритмов
С помощью микрофреймворка Flask (инструмент для создания минималистичных веб-приложений) был разработан тестовый веб-сервис для наглядного сравнения результатов вывода экстрактивных моделей на примере множества исходных новостных текстов. Мною проанализировано краткое содержание, генерируемое обеими моделями (извлекалось 2 наиболее значимых предложения) для 100 различных спортивных новостных статей.
По результатам сравнения результатов определения обеими моделями наиболее релевантных предложений могу предложить следующие рекомендации по использованию алгоритмов:
- Первая модель больше подходит для формирования заголовков или различного рода вступлений. На рассмотренных статьях выделялись именно те предложения, которые могли бы привлечь внимание потенциального читателя новости. Поэтому использование данной модели оправдано при формировании заголовка спортивной статьи, блога или иной новости.
- Вторая модель качественнее отражала основную суть полного текста. За счет обученных векторов, которые учитывали похожесть слов даже если они отличаются в написании, этот алгоритм хорошо подходит для формирования аннотации, содержащей основные мысли исходного текста. Обучая модель на других данных, которые связаны с интересующей предметной областью, можно получить качественный результат передачи основного смысла новости, документа или другого текста.
Абстрактивная суммаризация
Абстрактивный подход существенно отличается от своего предшественника и заключается в генерации краткого содержания с порождением нового текста, содержательно обобщающего первичный документ.
Основная идея данного подхода состоит в том, что модель способна генерировать абсолютно уникальное резюме, которое может содержать слова, отсутствующие в исходном тексте. Вывод модели представляет собой некоторый пересказ текста, который более близок к ручному составлению краткого содержания текста людьми.
Этап обучения
Я не буду подробно останавливаться на математических обоснованиях работы алгоритма, все известные мне модели основаны на архитектуре «кодера-декодера», которая в свою очередь построена с помощью рекуррентных слоев LSTM (о принципе работе которых можно почитать здесь). Кратко опишу шаги для декодирования тестовой последовательности.
- Кодируем всю входную последовательность и инициализируем декодер внутренними состояниями кодера
- Передаем токен «start» в качестве входных данных для декодера
- Запускаем декодер с внутренними состояниями кодера на один временной шаг, в результате получаем вероятность следующего слова (слово с максимальной вероятностью)
- Передаем выбранное слово в качестве входных данных для декодера на следующем временном шаге и обновляем внутренние состояния
- Повторяем шаги 3 и 4, пока не сгенерируем токен «end»
Подробно с архитектурой «кодера-декодера» можно ознакомиться здесь.
Реализация абстрактивной суммаризации
Для построения более сложной абстрактивной модели извлечения краткого содержания потребуются как полные тексты новостей, так и их заголовки. В качестве резюме будет выступать именно заголовок новости, так как модель «плохо запоминает» длинные текстовые последовательностями.
При чистке данных используем перевод в нижний регистр и отбрасывание не русскоязычных символов. Лемматизация слов, удаление предлогов, частиц и других неинформативных частей речи окажет отрицательное воздействие на конечный вывод модели, так как потеряется взаимосвязь между словами в предложении.
Далее тексты и их заголовки разбиваем на обучающую и тестовую выборки в отношении 9 к 1, после чего преобразуем их в векторы (случайным образом).
На следующем шаге создаем саму модель, которая будет считывать переданные ей векторы слов и осуществлять их обработку с помощью 3 рекуррентных слоев LSTM кодера и 1 слоя декодера.
После инициализации модели обучаем ее с применением кросс-энтропийной функции потерь, которая показывает расхождения между реальным целевым заголовком и тем, который предсказывает наша модель.
Наконец, выводим результат модели для тренировочного множества. Как можно заметить в примерах, исходные тексты и резюме содержат неточности из-за отбрасывания перед построением модели редко встречающихся слов (отбрасываем для того, чтобы «упростить обучение»).
Вывод модели на данном этапе оставляет желать лучшего. Модель «успешно запоминает» некоторые названия клубов и фамилии футболистов, но сам контекст практически не уловила.
Несмотря на более современный подход к извлечению резюме, пока данный алгоритм сильно уступает созданным ранее экстрактивным моделям. Тем не менее, для того, чтобы улучшить качество модели, можно обучать модель на более объемном датасете, но, на мой взгляд, для получения действительного хорошего вывода модели необходимо изменить или, возможно, полностью сменить саму архитектуру используемых нейросетей.
Так какой же подход лучше?
Подытоживая данную статью, перечислю основные плюсы и минусы рассмотренных подходов извлечения краткого содержания:
1. Экстрактивный подход:
Преимущества:
- Интуитивно понятна суть алгоритма
- Относительная простота реализации
Недостатки:
- Качество содержания во многих случаях может быть хуже, чем написанное вручную человеком
2. Абстрактивный подход:
Преимущества:
- Качественно реализованный алгоритм способен выдать результат наиболее близкий к ручному составлению резюме
Недостатки:
- Сложности при восприятии основных теоретических идей алгоритма
- Большие трудозатраты при реализации алгоритма
Однозначного ответа на вопрос, какой же подход лучше сформирует итоговое резюме, не существует. Всё зависит от конкретной задачи и целей пользователя. К примеру, экстрактивный алгоритм скорее всего лучше подойдет для формирования содержания многостраничных документов, где извлечение релевантных предложений действительно сможет корректно передать идею объемного текста.
На мой взгляд, будущее все-таки за абстрактивными алгоритмами. Несмотря на то, что на данных момент они развиты слабо и на определенном уровне качества вывода могут использоваться только для генерации небольших резюме (1-2 предложения), стоит ждать прорыв именно от нейросетевых методов. В перспективе они способны формировать содержание для абсолютно любых по размеру текстов и, что самое главное, само содержание будет максимально соответствовать ручному составлению резюме экспертом в той или иной области.
Векленко Влад, системный аналитик,
Консорциум «Кодекс»
Алгоритм выполнения заданий ReACT | Учим учиться
Для правильного выполнения заданий информационного тренинга необходимо выстроить последовательность элементарных учебных действий, своего рода алгоритм работы с информационным источниками. Эту когнитивную цепочку мы называем ReACT.
Расшифруем:
Re (read) – читаем
Этот шаг последовательности подразумевает считывание исходной информации с предлагаемого источника. Эта информация может быть представлена в различных форматах. Это может быть в буквальном смысле чтение текста, но мы также можем говорить и о считывании сведений с карты, со схемы, из таблицы, о восприятии информации на слух и т.п. Исходная информация может быть статичной или динамически меняться. В любом случае мы говорим о чтении, понимая этот термин в расширительном его смысле.
A (analyse) – анализируем
Если первая фаза предполагает непосредственное восприятие информации из конкретного источника (с учетом его формата), то второе звено цепочки предполагает соотнесение между собой сведений, которые представлены в этом источнике с формулировкой задания, содержанием вопроса, на который нужно ответить, с другими источниками данных, представленными в других форматах и т.п. Иногда необходимо повторное прочтение формулировки задания (или вопроса), так как после изучения информационного источника (или источников) она может восприниматься в ином или более определенном смысловом контексте.
C (compress) – “сжимаем” информацию, выделяем значимое
Сведения, предлагаемые в информационных источниках, почти всегда избыточны, если рассматривать их с точки зрения выполнения конкретного задания. Важно научиться уменьшать объем исходной информации, “сжимать” ее, выделяя только те данные, которые требуются для выполнения задания (и даже конкретного шага задания). То есть необходимо научиться отбрасывать все несущественное в заданном контексте и работать только с частью исходных данных; это облегчает и ускоряет процесс выполнения задания.
T (transform) – преобразуем (в тот формат, который требуется в задании).
Как правило, в задании требуется преобразовать исходную информацию и дать ответ в какой-то форме, отличной от исходного представления. Например, на основании текста нужно заполнить таблицу. Или на основе данных, представленных на карте, нужно составить корректное высказывание по текстовому шаблону. Эти активные действия, завершающие алгоритм выполнения задания, могут рассматриваться как расширительное толкование письма (письменной речи), то есть тренинг создания собственных информационных объектов.
Таким образом образуется цепочка “чтение” – ”преобразование” – “письмо”, характерная и для компьютерного алгоритма, и для когнитивного процесса.
Давайте попробуем на примере конкретного задания разобраться, как действует данный алгоритм.
В примере ниже мы имеем дело со следующим набором информационных объектов:
– исходная информация задана в формате карты Балтийского моря, на которую нанесено множество текстовых надписей;
– “рабочий” текст – это текст, в котором оставлены пропуски, которые должны быть заполнены на основе исходной информации, представленной в графическом формате (с учетом содержания самого «рабочего» текста).
– формулировка задания, которая акцентирует внимание на том, что пропуски в «рабочем» тексте заполняются не выбором из предложенных вариантов, а вписыванием сведений, представленных на карте.
Особо следует подчеркнуть, что сведения, необходимые для выполнения задания, представлены внутри самого задания; не требуется ничего вспоминать или искать в Интернете.
Re
Чтение карты требует особого умения, так как информация представлена в виде сочетания различных средств: надписей, линий, цветовых пятен и т.д. Кроме того, данная информация не структурирована для удобства визуального просмотра, как, например, таблица. Поэтому для поиска и считывания необходимых сведений с географической карты может потребоваться довольно много времени. Однако, без полноценного ознакомления с исходным информационным ресурсом последующие фазы могут быть непродуктивными и привести к ошибкам.
A
Фаза анализа предполагает изучение информации, представленной в источнике, в контексте решаемой задачи. В данном примере нужно ознакомиться с рабочим текстом и соотнести его содержание с данными карты. Не стоит торопиться выполнять какие-либо действия, даже если они кажутся очевидными. Следует сначала разобраться, на основе какой именно информации, представленной на карте, могут быть заполнены пропуски в тексте. В предлагаемом примере требуется заполнить семь пропусков. Во всех случаях требуется ввести в свободное текстовое поле географическое название города или страны. Для этого необходимо найти соответствующие объекты (город или страну) на карте и аккуратно списать их названия.
C
Во всех заданиях информация, представленная на экране, является избыточной. В фазе компрессии (сжатия) нужно определить, какие данные потребуются для выполнения задания, а какие – нет. Прочитав рабочий текст, можно сделать вывод, что вся информация, необходимая для заполнения пропусков, относится к Финскому заливу и его побережьям. Значит, на карте необходимо найти именно Финский залив, то есть сосредоточить свое внимание только на этой части Балтийского моря. Это позволяет сразу же исключить из рассмотрения значительную часть предлагаемой информации. Можно даже изменить масштаб карты и приблизить к себе нужную часть изображения, чтобы лучше читались требуемые для вписывания названия.
T
Заключительная фаза выполнения задания – представление информации в заданном формате. В задании требуется написать, то есть набрать на клавиатуре соответствующие географические названия. “Написать” в данном случае означает “списать”, так как все города и страны, о которых идет речь, подписаны на карте. Естественно, что компьютерная операция копирования здесь отключена. Нужно именно написать названия, причем сделать это в соответствии с правилами русского языка. Это, казалось бы, несложное действие требует внимания, чтобы не допустить ошибок при списывании.
Когда все пропуски в тексте заполнены, нужно проверить решение, нажав кнопку “Готово”.
Характерные ошибки
Ошибки “чтения” — учащийся неправильно считывает информацию с карты. Например, не понимает, что столицы обозначены на карте специальным символом – звездочкой. Другая возможная ошибка — неумение соотносить расположение городов и границы стран.
Ошибки, связанные с неверным определением сторон света. На карте нет надписей, прямо указывающих направления, карта дана в стандартной ориентации — “север сверху”. Кроме того, в нижнем правом углу предлагается «роза ветров», которая указывает все стороны света. Если учащийся не ориентируется в том, как определить по карте стороны света, это ведет к ошибочным ответам.
Ошибки “списывания” — для многих учащихся процесс написания незнакомых (а порой и знакомых) географических терминов представляет собой трудную задачу. От ошибок может спасти тщательная проверка набранного на клавиатуре слова до нажатия кнопки “Готово”, но сам по себе навык проверки сформирован далеко не у всех учащихся.
Найдите похожие тексты с помощью собственного алгоритма машинного обучения | by Günter Röhrich
4. Алгоритм TF-IDF
Поскольку мы использовали вышеупомянутую функцию для очистки и фильтрации данных, а также для настройки наших счетчиков, мы продолжим реализацию основных функций нашего эксперимента, tf- Алгоритм idf:
TF IDF в основном использует словари
Воспользовавшись нашим алгоритмом tf-idf, мы теперь можем решить рассматривать только ограниченное количество слов, только n слов с наивысшей оценкой, рассчитанной для каждого документа [3].Это n произвольно, чем больше n, тем более разреженной будет наша матрица сходства — имейте это в виду.
Чтобы вычислить сходство, нам нужен опорный вектор. Выполняя итерацию по всем документам, очищая их и подсчитывая слова, мы будем
- вычислить оценки tf_idf, а
- создадим опорный вектор — вектор, состоящий из набора всех релевантных слов (n слов на документ). Естественно, чем больше похожих документов, тем меньше будет наш вектор. Ожидайте, что он будет большим.
5. Вычислить сходство
Что мы сделаем дальше, так это вычислим сходство мешков, где мешок представлен своими n верхними словами. Все главные слова собраны в единый вектор слов. Мы создадим векторы для каждого пакета (итеративный процесс), а на следующем шаге мы сложим все векторы вместе в одну матрицу.
6. Правильное хранение данных
Мы уже проделали значительную работу по обработке и организации данных таким образом, чтобы мы могли значительно приблизиться к нашим заключительным этапам нашего анализа.После сложения наших векторов мы находим разреженную матрицу, которая плотна только вокруг своей диагонали (что имеет смысл, но больше, чем 7. Вычислить сходства ). Давайте сначала проверим здравомыслие.
# для нашей матрицы m
np.where (m.toarray () [0]> 0)
# n верхних значений:
(array ([52, 803, 1151, 1778, 1993], dtype = int64), )
Давайте проверим наши матрицы для Reuters и IMDB (график ограничен 25000 обзорами):
Matrix m , как он выглядит по данным Reuters — широкий из-за огромного количества главных слов Matrix m , как он выглядит по данным IMDB [: 25,000] —плотный
7.Вычислить сходства
Вычислить сходство — увлекательная задача, линейная алгебра предоставляет очень простой способ вычисления подобия: нас интересует косинусный угол между двумя векторами A и B, чем ближе эти две точки к одному направлению, тем ближе их значения к единице:
Косинусное сходство — первое изображение, появившееся в Google;) [5]
На нашем последнем шаге мы умножим наши значения матрицы на все другие значения в матрице (сходство равно 1, если мы умножим вектор с самим собой), мы называем эту матрицу подобия m_d_m .Как мы видим, существует четкая закономерность, в которой мы можем найти очевидные сходства — если бы нам нужно было сопоставить их вместе, это была бы идеальная задача кластеризации.
На следующем рисунке мы проверим данные Reuters по простой причине: данные Reuters — это ежедневные новости. Это означает, что мы, конечно, ожидаем определенных шаблонов сходства, однако новости охватывают множество разных областей, которые, естественно, имеют более широкий набор слов. Если бы мы использовали тот же сюжет для обзоров фильмов, мы бы в основном получили огромный синий квадрат (из-за плотности).
Наша матрица Reuters m_d_m , содержащая ненулевые значения
8. Анализ
В нашей задаче мы стремились найти документ, похожий на тот, который мы выбрали. Мы используем простую итерацию, чтобы найти все связанные документы, которые как минимум на x% похожи, где x снова определяется произвольно. Я пришел к выводу, что сходства вокруг .5 работают неплохо.
Руководство по классификации текста с машинным обучением и NLP
Текст может быть чрезвычайно богатым источником информации, но извлечение из него понимания может быть трудным и трудоемким из-за его неструктурированной природы.
Но благодаря достижениям в области обработки естественного языка и машинного обучения, которые подпадают под обширную область искусственного интеллекта, сортировка текстовых данных становится проще.
Тег настроения и темы в тексте с NLP
Он работает, автоматически анализируя и структурируя текст, быстро и экономично, так что предприятия могут автоматизировать процессы и обнаруживать идеи, которые приводят к более эффективному принятию решений.
Прочтите, чтобы узнать больше о классификации текста, о том, как она работает, и о том, как легко начать работу с инструментами классификации текста без кода, такими как анализатор тональности MonkeyLearn.
- Что такое классификация текста?
- Как работает классификация текста?
- Примеры классификации текста
- Ресурсы
Что такое классификация текста?
Классификация текста — это метод машинного обучения, который назначает набор предопределенных категорий открытому тексту. Текстовые классификаторы можно использовать для организации, структурирования и категоризации практически любого текста — от документов, медицинских исследований и файлов, а также по всему Интернету.
Например, новые статьи могут быть организованы по темам; билеты поддержки могут быть организованы в срочном порядке; чаты могут быть организованы по языку; упоминания бренда могут быть организованы по настроениям; и так далее.
Классификация текста — одна из фундаментальных задач обработки естественного языка с широкими приложениями, такими как анализ тональности, маркировка тем, обнаружение спама и обнаружение намерений.
Вот пример того, как это работает:
«Пользовательский интерфейс довольно прост и удобен.”
Классификатор текста может использовать эту фразу в качестве входных данных, анализировать ее содержимое, а затем автоматически назначать соответствующие теги, такие как UI и Easy To Use .
Почему важна классификация текста?
По оценкам, около 80% всей информации является неструктурированной, причем текст является одним из наиболее распространенных типов неструктурированных данных. Из-за беспорядочного характера текста анализ, понимание, организация и сортировка текстовых данных трудны и требуют много времени, поэтому большинству компаний не удается использовать их в полной мере.
Здесь на помощь приходит классификация текста с помощью машинного обучения. Используя текстовые классификаторы, компании могут автоматически структурировать любой релевантный текст: электронные письма, юридические документы, социальные сети, чат-боты, опросы и т. Д. Быстрым и экономичным способом. . Это позволяет компаниям экономить время на анализе текстовых данных, автоматизировать бизнес-процессы и принимать бизнес-решения на основе данных.
Зачем нужна классификация текста машинного обучения? Некоторые из основных причин:
Ручной анализ и систематизация медленные и гораздо менее точные.. Машинное обучение может автоматически анализировать миллионы опросов, комментариев, электронных писем и т. Д. За небольшую часть стоимости, часто всего за несколько минут. Инструменты классификации текста масштабируются для любых бизнес-потребностей, больших или малых.
Существуют критические ситуации, которые компаниям необходимо выявлять как можно скорее и принимать немедленные меры (например, PR-кризисы в социальных сетях). Классификация текста с помощью машинного обучения может отслеживать упоминания вашего бренда постоянно и в режиме реального времени, поэтому вы сможете определить важную информацию и сразу же принять меры.
Люди-аннотаторы делают ошибки при классификации текстовых данных из-за отвлекающих факторов, усталости и скуки, а человеческая субъективность создает противоречивые критерии. С другой стороны, машинное обучение применяет одни и те же критерии и критерии ко всем данным и результатам. Как только модель классификации текста обучена должным образом, она работает с непревзойденной точностью.
Как работает классификация текста?
Вы можете выполнить классификацию текста двумя способами: вручную или автоматически.
Ручная классификация текста включает человека-комментатора, который интерпретирует содержание текста и соответствующим образом классифицирует его. Этот метод может дать хорошие результаты, но требует много времени и средств.
Автоматическая классификация текста использует машинное обучение, обработку естественного языка (NLP) и другие методы на основе искусственного интеллекта, чтобы автоматически классифицировать текст быстрее, экономичнее и точнее.
В этом руководстве мы сосредоточимся на автоматической классификации текста.
Существует много подходов к автоматической классификации текста, но все они относятся к трем типам систем:
- Системы на основе правил
- Системы на основе машинного обучения
- Гибридные системы
Системы на основе правил
Правило- Основанные на подходе подходы классифицируют текст на организованные группы с использованием набора вручную созданных лингвистических правил. Эти правила предписывают системе использовать семантически релевантные элементы текста для определения релевантных категорий на основе его содержимого.Каждое правило состоит из антецедента или шаблона и прогнозируемой категории.
Предположим, вы хотите разделить новостные статьи на две группы: Спорт и Политика . Во-первых, вам нужно определить два списка слов, которые характеризуют каждую группу (например, слова, относящиеся к спорту, такие как футбол , баскетбол , LeBron James и т. Д., И слова, относящиеся к политике, например Дональд Трамп , Хиллари Клинтон , Путин и т. Д.).
Затем, когда вы хотите классифицировать новый входящий текст, вам нужно будет подсчитать количество слов, связанных со спортом, которые появляются в тексте, и сделать то же самое для слов, связанных с политикой. Если количество слов, связанных со спортом, превышает количество слов, связанных с политикой, тогда текст классифицируется как спорт и наоборот.
Например, эта основанная на правилах система классифицирует заголовок «Когда состоится первая игра Леброна Джеймса с« Лейкерс »?» как Sports , потому что в нем учитывался один термин, связанный со спортом (Леброн Джеймс), и не учитывались термины, связанные с политикой.
Системы, основанные на правилах, понятны человеку и со временем могут быть улучшены. Но у этого подхода есть недостатки. Для начала, эти системы требуют глубокого знания предметной области. Они также отнимают много времени, поскольку создание правил для сложной системы может быть довольно сложной задачей и обычно требует большого анализа и тестирования. Системы, основанные на правилах, также сложно поддерживать, и они плохо масштабируются, учитывая, что добавление новых правил может повлиять на результаты уже существующих правил.
Системы на основе машинного обучения
Вместо того, чтобы полагаться на правила, созданные вручную, классификация текста машинного обучения учится делать классификации на основе прошлых наблюдений.Используя предварительно размеченные примеры в качестве обучающих данных, алгоритмы машинного обучения могут изучать различные ассоциации между частями текста и то, что конкретный результат (то есть теги) ожидается для определенного ввода (то есть текста). «Тег» — это заранее определенная классификация или категория, в которую может попасть любой данный текст.
Первым шагом на пути к обучению классификатора НЛП машинного обучения является извлечение признаков: метод используется для преобразования каждого текста в числовое представление в виде вектора.Один из наиболее часто используемых подходов — это набор слов, где вектор представляет частоту слова в заранее определенном словаре слов.
Например, если мы определили наш словарь, чтобы он содержал следующие слова { This, is, the, not, awesome, bad, Basketball }, и мы хотели векторизовать текст «This is awesome», we будет иметь следующее векторное представление этого текста: (1, 1, 0, 0, 1, 0, 0).
Затем в алгоритм машинного обучения поступают обучающие данные, которые состоят из пар наборов функций (векторов для каждого примера текста) и тегов (например.грамм. спорт , политика ) для создания классификационной модели:
После обучения с использованием достаточного количества обучающих выборок модель машинного обучения может начать делать точные прогнозы. Тот же самый экстрактор признаков используется для преобразования невидимого текста в наборы признаков, которые могут быть введены в модель классификации для получения прогнозов по тегам (например, спорт , политика ):
Классификация текста с помощью машинного обучения обычно намного точнее, чем система правил, созданная человеком, особенно в сложных задачах классификации НЛП.Кроме того, классификаторы с машинным обучением легче поддерживать, и вы всегда можете пометить новые примеры, чтобы изучить новые задачи.
Алгоритмы классификации текста машинного обучения
Некоторые из наиболее популярных алгоритмов классификации текста включают семейство алгоритмов Наивного Байеса, вспомогательные векторные машины (SVM) и глубокое обучение.
Наивный Байес
Семейство статистических алгоритмов Наивного Байеса — одни из наиболее часто используемых алгоритмов классификации и анализа текста в целом.
Одним из членов этого семейства является Multinomial Naive Bayes (MNB) с огромным преимуществом, заключающимся в том, что вы можете получить действительно хорошие результаты, даже когда ваш набор данных не очень велик (~ пара тысяч помеченных образцов) и вычислительные ресурсы дефицитный.
Наивный Байес основан на теореме Байеса, которая помогает нам вычислить условные вероятности возникновения двух событий на основе вероятностей наступления каждого отдельного события. Таким образом, мы вычисляем вероятность каждого тега для данного текста, а затем выводим тег с наибольшей вероятностью.
Вероятность A, если B истинно, равна вероятности B, если A истинно, умноженной на вероятность того, что A истинно, деленная на вероятность того, что B истинно.
Это означает, что любой вектор, представляющий текст, должен содержать информацию о вероятностях появления определенных слов в текстах данной категории, чтобы алгоритм мог вычислить вероятность того, что этот текст принадлежит к категории.
Прочтите это сообщение в блоге, чтобы узнать больше о Наивном Байесе.
Машины опорных векторов
Машины опорных векторов (SVM) — еще один мощный алгоритм машинного обучения классификации текста, потому что, как и наивный Байес, SVM не требует большого количества обучающих данных, чтобы начать предоставлять точные результаты. Однако SVM требует больше вычислительных ресурсов, чем наивный байесовский метод, но результаты еще быстрее и точнее.
Короче говоря, SVM рисует линию или «гиперплоскость», разделяющую пространство на два подпространства. Одно подпространство содержит векторы (теги), которые принадлежат группе, а другое подпространство содержит векторы, которые не принадлежат этой группе.
Оптимальная гиперплоскость — это гиперплоскость с наибольшим расстоянием между тегами. В двух измерениях это выглядит так:
Эти векторы представляют собой ваши учебные тексты, а группа — это тег, которым вы пометили свои тексты.
По мере того, как данные становятся более сложными, может оказаться невозможным классифицировать векторы / теги только по двум категориям. Итак, это выглядит так:
Но что самое замечательное в алгоритмах SVM — они «многомерны.«Таким образом, чем сложнее данные, тем точнее будут результаты. Представьте вышеупомянутое в трех измерениях с добавленной осью Z, чтобы создать круг.
В двух измерениях идеальная гиперплоскость выглядит так:
Глубокое обучение
Глубокое обучение — это набор алгоритмов и методов, основанных на том, как работает человеческий мозг, называемых нейронными сетями. Архитектуры глубокого обучения предлагают огромные преимущества для классификации текста, поскольку они работают со сверхвысокой точностью при проектировании и вычислениях нижнего уровня.
Двумя основными архитектурами глубокого обучения для классификации текста являются сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN).
Глубокое обучение — это иерархическое машинное обучение с использованием нескольких алгоритмов в последовательной цепочке событий. Это похоже на то, как человеческий мозг принимает решения, используя одновременно разные методы для обработки огромных объемов данных.
Алгоритмы глубокого обучения требуют гораздо больше обучающих данных, чем традиционные алгоритмы машинного обучения (по крайней мере, миллионы помеченных примеров).Тем не менее, у них нет порога для обучения на основе обучающих данных, так как традиционные алгоритмы машинного обучения, такие как обучающие классификаторы SVM и NBeep, продолжают улучшаться, чем больше данных вы их вводите:
Алгоритмы глубокого обучения, такие как Word2Vec или GloVe, также используются для получения лучшего векторного представления слов и повышения точности классификаторов, обученных с помощью традиционных алгоритмов машинного обучения.
Гибридные системы
Гибридные системы сочетают в себе базовый классификатор, обученный машинному обучению, с системой на основе правил, которая используется для дальнейшего улучшения результатов.Эти гибридные системы можно легко настроить, добавив специальные правила для тех конфликтующих тегов, которые не были правильно смоделированы базовым классификатором.
Метрики и оценка
Перекрестная проверка — это распространенный метод оценки производительности текстового классификатора. Он работает путем разделения набора обучающих данных на случайные наборы примеров равной длины (например, 4 набора с 25% данных). Для каждого набора текстовый классификатор обучается с оставшимися выборками (например, 75% выборок).Затем классификаторы делают прогнозы для своих соответствующих наборов, и результаты сравниваются с тегами, аннотированными людьми. Это позволит определить, когда прогноз был верным (истинные положительные и истинные отрицательные), а когда был ошибочным (ложные срабатывания, ложные отрицания).
С этими результатами вы можете построить метрики производительности, которые полезны для быстрой оценки того, насколько хорошо работает классификатор:
- Точность: процент текстов, которые были отнесены к категории с правильным тегом.
- Точность: процент примеров, которые классификатор получил прямо из общего числа примеров, которые он спрогнозировал для данного тега.
- Напомним: процент примеров, предсказанных классификатором для данного тега, из общего числа примеров, которые он должен был спрогнозировать для данного тега.
- Оценка F1: среднее гармоническое значение точности и отзывчивости.
Почему важна классификация текста?
По оценкам, около 80% всей информации является неструктурированной, причем текст является одним из наиболее распространенных типов неструктурированных данных.Из-за беспорядочного характера текста анализ, понимание, организация и сортировка текстовых данных трудны и требуют много времени, поэтому большинству компаний не удается использовать их в полной мере.
Здесь на помощь приходит классификация текста с помощью машинного обучения. Используя текстовые классификаторы, компании могут автоматически структурировать любой релевантный текст: электронные письма, юридические документы, социальные сети, чат-боты, опросы и т. Д. Быстрым и экономичным способом. . Это позволяет компаниям экономить время на анализе текстовых данных, автоматизировать бизнес-процессы и принимать бизнес-решения на основе данных.
Зачем нужна классификация текста машинного обучения? Некоторые из основных причин:
Анализ и организация вручную медленные и гораздо менее точные. Машинное обучение может автоматически анализировать миллионы опросов, комментариев, электронных писем и т. Д. За небольшую часть стоимости, часто всего за несколько минут. Инструменты классификации текста масштабируются для любых бизнес-потребностей, больших или малых.
Существуют критические ситуации, которые компаниям необходимо выявлять как можно скорее и незамедлительно принимать меры (например,г., PR-кризисы в социальных сетях). Классификация текста с помощью машинного обучения может отслеживать упоминания вашего бренда постоянно и в режиме реального времени, поэтому вы сможете определить важную информацию и сразу же принять меры.
Люди-аннотаторы делают ошибки при классификации текстовых данных из-за отвлекающих факторов, усталости и скуки, а человеческая субъективность создает противоречивые критерии. С другой стороны, машинное обучение применяет одни и те же критерии и критерии ко всем данным и результатам. Как только модель классификации текста обучена должным образом, она работает с непревзойденной точностью.
Примеры классификации текста
Классификация текста может использоваться в широком диапазоне контекстов, таких как классификация коротких текстов (например, твиты, заголовки, запросы чат-ботов и т. Д.) Или организация гораздо более крупных документов (например, обзоры клиентов, новостные статьи, юридические контракты, длинные формы клиентов опросы и др.). Некоторые из наиболее известных примеров классификации текста включают анализ тональности, обозначение тем, определение языка и обнаружение намерений.
Анализ настроений
Возможно, наиболее популярным примером классификации текстов является анализ настроений (или анализ мнений ): автоматизированный процесс чтения текста на предмет полярности мнения (положительного, отрицательного, нейтрального и не только).Компании используют классификаторы настроений в широком спектре приложений, таких как аналитика продуктов, мониторинг брендов, исследования рынка, поддержка клиентов, аналитика персонала и многое другое.
Анализ тональности позволяет автоматически анализировать все формы текста на предмет чувств и эмоций автора.
Попробуйте этот предварительно обученный классификатор тональности со своим собственным текстом, чтобы убедиться, насколько легко это сделать.
Тест с собственным текстом
Новый UX потрясающий. Так легко использовать.Классифицируйте текст
Если вы видите странный результат, не волнуйтесь, это просто потому, что он не был обучен (пока) подобным выражениям. Для получения сверхточных результатов, обученных конкретному языку и критериям вашего бизнеса, следуйте этому краткому руководству по анализу настроений, чтобы создать собственную модель анализа настроений всего за пять шагов.
Обозначение темы
Другой распространенный пример классификации текста — это обозначение темы, то есть понимание того, о чем говорит данный текст.Его часто используют для структурирования и систематизации данных, например для организации отзывов клиентов по темам или для организации новостных статей по темам.
Попробуйте эту предварительно обученную модель для классификации ответов NPS для продуктов SaaS в соответствии с их темой. Он помечает отзывы клиентов по категориям: Поддержка клиентов, Простота использования, Функции, и Ценообразование :
Протестируйте своим собственным текстом
Обслуживание клиентов ужасное. Я был в ожидании в течение нескольких часов. Классифицировать текст
Узнайте больше о маркировке тем и о том, как создать собственный текстовый классификатор с несколькими метками.
Определение языка
Определение языка — еще один отличный пример классификации текста, то есть процесс классификации входящего текста в соответствии с его языком. Эти текстовые классификаторы часто используются для целей маршрутизации (например, билеты поддержки маршрутов в соответствии с их языком в соответствующую команду).
Ниже приводится классификатор, обученный обнаруживать 49 различных языков в тексте:
Тест с вашим собственным текстом
Научный метод — это совокупность техник для исследования явлений, получения новых знаний или исправления и интеграции предыдущих знаний.Классифицируйте текст
Обнаружение намерения
Обнаружение намерения или классификация намерений — еще один отличный вариант использования классификации текста, который анализирует текст, чтобы понять причину обратной связи. Может быть, это жалоба, а может быть, покупатель выражает намерение приобрести товар. Он используется для обслуживания клиентов, маркетинговых ответов по электронной почте, создания аналитики продуктов и автоматизации бизнес-практик. Обнаружение намерений с помощью машинного обучения может читать электронные письма и разговоры с чат-ботами и автоматически направлять их в нужный отдел.
Попробуйте этот классификатор намерений электронной почты, который обучен определять цель ответов по электронной почте. Он классифицируется по тегам: Заинтересован, Не заинтересован, Отказаться от подписки, Не тот человек, Отказ электронной почты, и Автоответчик :
Тест с вашим собственным текстом
Программа выглядит довольно круто. Я хотел бы выделить время, чтобы поговорить побольше. Классификация текста
Классификация текста Приложения и варианты использования
Классификация текста имеет тысячи вариантов использования и применяется к широкому кругу задач.В некоторых случаях инструменты классификации данных работают за кулисами, чтобы улучшить функции приложения, с которыми мы взаимодействуем ежедневно (например, фильтрация спама в электронной почте). В некоторых других случаях классификаторы используются маркетологами, менеджерами по продукции, инженерами и продавцами для автоматизации бизнес-процессов и экономии сотен часов ручной обработки данных.
Некоторые из основных приложений и вариантов использования текстовой классификации включают:
- Обнаружение срочных проблем
- Автоматизация процессов поддержки клиентов
- Прислушивание к голосу клиента (VoC)
Обнаружение срочных проблем
Только в Twitter, пользователи отправляют 500 миллионов твитов каждый день.
Опросы показывают, что 83% клиентов, которые комментируют или жалуются в социальных сетях, ожидают ответа в тот же день, а 18% ожидают, что он придет немедленно.
С помощью классификации текста компании могут анализировать большие объемы данных, используя такие методы, как анализ тональности на основе аспектов, чтобы понять, о чем люди говорят и как они говорят о каждом аспекте. Например, потенциальный кризис с общественностью, клиент, который вот-вот уйдет, жалобы на ошибку или простои, затрагивающие более чем несколько клиентов.
Автоматизация процессов поддержки клиентов
Создание хорошего клиентского опыта — одна из основ устойчивой и растущей компании. Согласно Hubspot, вероятность того, что люди станут постоянными клиентами в компаниях с отличным обслуживанием, на 93% выше. Исследование также показало, что 80% респондентов заявили, что прекратили вести дела с компанией из-за плохого качества обслуживания клиентов.
Классификация текста может помочь командам поддержки обеспечить отличный опыт, автоматизируя задачи, которые лучше доверить компьютерам, экономя драгоценное время, которое можно потратить на более важные дела.
Например, классификация текста часто используется для автоматизации маршрутизации билетов и сортировки. Текстовая классификация позволяет автоматически направлять заявки в службу поддержки товарищу по команде, обладающему определенным опытом работы с продуктом. Если клиент пишет с просьбой о возврате средств, вы можете автоматически назначить билет своему товарищу по команде с разрешением на выполнение возмещения. Это гарантирует, что заказчик быстрее получит качественный ответ.
Группы поддержки также могут использовать классификацию настроений, чтобы автоматически определять срочность обращения в службу поддержки и определять приоритетность тех, которые содержат негативные настроения.Это может помочь вам снизить отток клиентов и даже исправить плохую ситуацию.
Прислушиваясь к голосу клиентов (VoC)
Компании используют опросы, такие как Net Promoter Score, чтобы прислушиваться к голосу своих клиентов на каждом этапе пути.
Собираемая информация является как качественной, так и количественной, и хотя оценки NPS легко анализировать, открытые ответы требуют более глубокого анализа с использованием методов классификации текста. Вместо того, чтобы полагаться на людей для анализа голосовых данных о клиентах, вы можете быстро обрабатывать открытые отзывы клиентов с помощью машинного обучения.Классификационные модели могут помочь вам проанализировать результаты опроса, чтобы выявить закономерности и идеи, например:
- Что людям нравится в наших продуктах или услугах?
- Что мы должны улучшить?
- Что нам нужно изменить?
Комбинируя количественные результаты и качественный анализ, команды могут принимать более обоснованные решения, не тратя часы на ручной анализ каждого отдельного открытого ответа.
Текстовая классификация Ресурсы
Как только вы начнете автоматизировать ручные и повторяющиеся задачи, используя всевозможные методы классификации текста, вы можете сосредоточиться на других областях своего бизнеса.
Но… как, черт возьми, начать с классификации текста? Так много информации об анализе текста, машинном обучении и обработке естественного языка, что это может показаться огромным.
В MonkeyLearn мы помогаем вам узнать, с чего начать. Мы предоставляем конструктор текстовых классификаторов без кода, так что вы можете создать свой собственный текстовый классификатор за несколько простых шагов.
Создание вашего первого классификатора текста может помочь вам по-настоящему понять преимущества классификации текста, но прежде чем мы углубимся в подробности того, что может сделать MonkeyLearn, давайте посмотрим, что вам понадобится для создания вашей собственной модели классификации текста:
1.Наборы данных
Классификатор текста бесполезен без точных данных обучения. Алгоритмы машинного обучения могут делать точные прогнозы только на основе предыдущих примеров.
Вы показываете примеры алгоритма правильно помеченных данных, и он использует эти помеченные данные для прогнозирования невидимого текста.
Допустим, вы хотите предсказать намерение разговоров в чате; вам нужно будет определить и собрать разговоры в чате, которые представляют различные намерения, которые вы хотите предсказать.Если вы тренируете свою модель с другим типом данных, классификатор даст плохие результаты.
Итак, как получить данные для обучения?
Вы можете использовать внутренних данных , сгенерированных из приложений и инструментов, которые вы используете каждый день, таких как CRM (например, Salesforce, Hubspot), приложения для чата (например, Slack, Drift, Intercom), программное обеспечение службы поддержки (например, Zendesk, Freshdesk, Front ), инструменты для проведения опросов (например, SurveyMonkey, Typeform, Google Forms) и инструменты для обеспечения удовлетворенности клиентов (например, Promoter.io, Retently, Satismeter).Эти инструменты обычно предоставляют возможность экспортировать данные в файл CSV, который можно использовать для обучения классификатора.
Другой вариант — использовать внешних данных из Интернета, либо с помощью веб-скрейпинга, API-интерфейсов или общедоступных наборов данных.
Ниже приведены некоторые общедоступные наборы данных, которые вы можете использовать для создания своего первого текстового классификатора и сразу же начать экспериментировать.
Классификация тем:
Набор данных новостей Reuters: вероятно, один из наиболее широко используемых наборов данных для классификации текста; он содержит 21 578 новостных статей от Reuters, разделенных на 135 категорий в соответствии с их тематикой, таких как политика, экономика, спорт и бизнес.
20 Группы новостей: еще один популярный набор данных, состоящий из ~ 20 000 документов по 20 различным темам.
Анализ настроений:
Обзоры продуктов Amazon: широко известный набор данных, содержащий ~ 143 миллионов отзывов и звездных оценок (от 1 до 5 звезд) за период с мая 1996 г. по июль 2014 г. Вы можете получить альтернативный набор данных для Amazon обзоры товаров здесь.
Обзоры IMDB: гораздо меньший набор данных с 25 000 обзоров фильмов, помеченных как положительные и отрицательные, из базы данных Internet Movie Database (IMDB).
Twitter Мнение авиакомпаний: этот набор данных содержит около 15 000 твитов об авиакомпаниях, помеченных как положительные, нейтральные и отрицательные.
Другие популярные наборы данных:
Спамбаза: набор данных с 4601 электронным письмом, помеченным как спам, а не как спам.
Сборник SMS-спама: еще один набор данных для обнаружения спама, состоящий из 5 574 SMS-сообщений, помеченных как спам или законные.
Разжигание ненависти и ненормативная лексика: этот набор данных содержит 24 802 помеченных твита, разделенных на три категории: чистые, разжигающие ненависть высказывания и оскорбительные выражения.
2. Инструменты классификации текста
Хорошо. Теперь, когда у вас есть данные для обучения, пришло время передать их алгоритму машинного обучения и создать классификатор текста.
Итак, как нам это сделать?
К счастью, многие ресурсы могут помочь вам на разных этапах процесса, например, преобразование текстов в векторы, обучение алгоритма машинного обучения и использование модели для прогнозирования. В общих чертах, эти инструменты можно разделить на две разные категории:
Споры продолжаются: сборка vs.Купить. Библиотеки с открытым исходным кодом могут работать в верхнем эшелоне инструментов машинного обучения для классификации текста, но их создание требует больших затрат и времени, а также требует многолетнего опыта в области науки о данных и компьютерной инженерии.
Инструменты SaaS, с другой стороны, практически не требуют кода, полностью масштабируемы и намного дешевле, поскольку вы используете только те инструменты, которые вам нужны. Лучше всего то, что большинство из них можно реализовать сразу же и обучить (часто всего за несколько минут) действовать так же быстро и точно.
Библиотеки с открытым исходным кодом для классификации текста
Одной из причин, по которой машинное обучение стало массовым явлением, является огромное количество библиотек с открытым исходным кодом, доступных для разработчиков, заинтересованных в его применении. Хотя они требуют серьезного опыта в области науки о данных и машинного обучения, эти библиотеки предлагают достаточный уровень абстракции и упрощения. Python, Java и R предлагают широкий выбор библиотек машинного обучения, которые активно разрабатываются и предоставляют разнообразный набор функций, производительности и возможностей.
Классификация текста с помощью Python
Python обычно является предпочтительным языком программирования для разработчиков и специалистов по данным, которые работают с моделями машинного обучения. Простой синтаксис, обширное сообщество и удобство математических библиотек для научных вычислений — вот некоторые из причин, по которым Python так распространен в этой области.
Scikit-learn — одна из популярных библиотек для машинного обучения общего назначения. Он поддерживает множество алгоритмов и предоставляет простые и эффективные функции для работы с моделями классификации текста, регрессии и кластеризации.Если вы новичок в машинном обучении, scikit-learn — одна из самых удобных библиотек для начала работы с классификацией текста с десятками руководств и пошаговых руководств по всему Интернету.
NLTK — популярная библиотека, ориентированная на обработку естественного языка (NLP), за которой стоит большое сообщество. Он очень удобен для классификации текста, поскольку предоставляет всевозможные полезные инструменты для того, чтобы машина понимала текст, например, разбиение абзацев на предложения, разбиение слов и распознавание части речи этих слов.
Современная и более новая библиотека НЛП — это SpaCy, набор инструментов с более простым и простым подходом, чем NLTK. Например, spaCy реализует только один стеммер (NLTK имеет 9 различных опций). SpaCy также имеет встроенные слова, которые могут быть полезны для повышения точности классификации текста.
Когда вы будете готовы экспериментировать с более сложными алгоритмами, вам следует попробовать библиотеки глубокого обучения, такие как Keras, TensorFlow и PyTorch. Keras, вероятно, является лучшей отправной точкой, поскольку он разработан для упрощения создания рекуррентных нейронных сетей (RNN) и сверточных нейронных сетей (CNN).
TensorFlow — самая популярная библиотека с открытым исходным кодом для реализации алгоритмов глубокого обучения. Эта библиотека, разработанная Google и используемая такими компаниями, как Dropbox, eBay и Intel, оптимизирована для настройки, обучения и развертывания искусственных нейронных сетей с массивными наборами данных. Хотя его сложнее освоить, чем Кераса, это бесспорный лидер в области глубокого обучения. Надежной альтернативой TensorFlow является PyTorch, обширная библиотека глубокого обучения, изначально разработанная Facebook и поддерживаемая Twitter, Nvidia, Salesforce, Стэнфордским университетом, Оксфордским университетом и Uber.
Классификация текста с помощью Java
Другим языком программирования, широко используемым для реализации моделей машинного обучения, является Java. Как и Python, у него большое сообщество, обширная экосистема и большой выбор библиотек с открытым исходным кодом для машинного обучения и НЛП.
CoreNLP — самый популярный фреймворк для NLP на Java. Созданный Стэнфордским университетом, он предоставляет разнообразный набор инструментов для понимания человеческого языка, таких как синтаксический анализатор текста, теггер части речи (POS), распознаватель именованных сущностей (NER), систему разрешения кореференции и инструменты извлечения информации. .
Еще один популярный инструментарий для задач на естественном языке — OpenNLP. Созданный Apache Software Foundation, он предоставляет набор инструментов лингвистического анализа, полезных для классификации текста, таких как токенизация, сегментация предложений, теги частей речи, фрагменты и синтаксический анализ.
Weka — это библиотека машинного обучения, разработанная Университетом Вайкато и содержащая множество инструментов, таких как классификация, регрессия, кластеризация и визуализация данных. Он предоставляет графический пользовательский интерфейс для применения коллекции алгоритмов Weka непосредственно к набору данных и API для вызова этих алгоритмов из вашего собственного кода Java.
Классификация текста с помощью R
Язык R — доступный язык программирования, который становится все более популярным среди энтузиастов машинного обучения. Исторически он наиболее широко использовался учеными и статистиками для статистического анализа, графического представления и отчетности. Согласно KDnuggets, в настоящее время это второй по популярности язык программирования для аналитики, обработки данных и машинного обучения (в то время как Python занимает первое место).
R — отличный выбор для задач классификации текста, поскольку он предоставляет обширный, согласованный и интегрированный набор инструментов для анализа данных.
Caret — это комплексный пакет для построения моделей машинного обучения в R. Сокращение от «Classification and Regression Training», он предлагает простой интерфейс для применения различных алгоритмов и содержит полезные инструменты для классификации текста, такие как предварительная обработка, выбор функций и тюнинг модели.
Mlr — еще один пакет R, который предоставляет стандартизированный интерфейс для использования алгоритмов классификации и регрессии вместе с соответствующими методами оценки и оптимизации.
API-интерфейсы классификации текста SaaS
Инструменты с открытым исходным кодом — это здорово, но они в основном ориентированы на людей с опытом машинного обучения. Кроме того, они не обеспечивают простой способ развертывания и масштабирования моделей машинного обучения, очистки и обработки данных, примеров обучения тегов, разработки функций или начальной загрузки моделей.
Вам может быть интересно, есть ли более простой способ?
Что ж, если вы хотите избежать этих неприятностей, отличной альтернативой является использование программного обеспечения как услуги (SaaS) для классификации текста, которое обычно решает большинство проблем, упомянутых выше.Еще одно преимущество состоит в том, что им не требуется опыт машинного обучения, и даже люди, не умеющие кодировать, могут использовать и использовать текстовые классификаторы. В конце концов, если переложить тяжелую работу на SaaS, вы сможете сэкономить время, деньги и ресурсы при внедрении системы классификации текста.
Некоторые из самых замечательных SaaS-решений и API для классификации текста включают:
- MonkeyLearn
- Google Cloud NLP
- IBM Watson
- Lexalytics
- MeaningCloud
- Amazon Comprehend
- Aylienin
Text Classification
Лучший способ узнать о классификации текста — это намочить ноги и построить свой первый классификатор.Если вы не хотите тратить слишком много времени на изучение машинного обучения или развертывание необходимой инфраструктуры, вы можете использовать MonkeyLearn, платформу, которая упрощает создание, обучение и использование текстовых классификаторов. А как только вы построите свой классификатор, вы сможете увидеть свои результаты в мельчайших деталях с помощью MonkeyLearn Studio. Зарегистрируйтесь бесплатно и создайте свой собственный классификатор, выполнив следующие четыре простых шага:
1. Создайте новый классификатор текста:
Перейдите на панель управления, затем щелкните Создать модель и выберите Классификатор :
2.Загрузите данные обучения:
Затем вам необходимо загрузить данные, которые вы хотите использовать в качестве примеров для обучения своей модели. Вы можете загрузить файл CSV или Excel или импортировать текстовые данные непосредственно из стороннего приложения, например Twitter, Gmail, Zendesk или RSS-каналов:
3. Определите теги для своей модели:
Следующим шагом является определение тегов, которые вы хотите использовать для классификатора текста:
После обучения классификатора входящие данные будут автоматически классифицироваться по тегам, которые вы укажете на этом шаге.Старайтесь избегать использования перекрывающихся или неоднозначных тегов, поскольку это может вызвать путаницу и ухудшить точность классификатора.
4. Пометьте данные для обучения классификатора:
Наконец, вам нужно пометить каждый пример ожидаемой категорией, чтобы начать обучение модели машинного обучения:
По мере того, как вы помечаете данные, классификатор будет учиться распознавать похожие шаблоны при представлении нового текста и проводить точную классификацию. Помните: чем больше данных вы пометите, тем точнее будет модель.
Тестирование классификатора
После того, как вы закончите работу с мастером создания, вы сможете протестировать классификатор в «Выполнить»> «Демо» и посмотреть, как модель классифицирует тексты, которые вы пишете:
Протестируйте с вашим собственным text
Я должен сказать, что в этом отеле наихудшее обслуживание клиентов. .грамм. точность, оценка F1, точность и отзывчивость) и облако ключевых слов, состоящее из n граммов для каждой категории.
Пометьте дополнительные данные обучения, пройдя через ложные срабатывания и ложные отрицания, и пометьте неправильно помеченные примеры.
Очистите данные, чтобы отделить ключевые слова от определенного тега.
Используйте соответствующие обучающие данные, другими словами, данные, которые представляют проблему, которую вы пытаетесь решить.
Добавьте биграммы в свой набор функций, чтобы модели классификации лучше понимали контекст слов.
Интеграция классификатора
Как только прогнозы станут достаточно хорошими, модель будет готова к категоризации нового невидимого текста. MonkeyLearn предоставляет разные способы достижения этого: пакетная обработка, API или интеграции.
Вы можете загрузить файл CSV или Excel для классификации текста в пакете в «Выполнить»> «Пакет»:
После загрузки файла классификатор проанализирует данные и вернет новый файл с теми же данными плюс прогнозы.
В качестве альтернативы вы можете использовать API MonkeyLearn для программной классификации новых данных:
Другая возможность — использовать одну из доступных интеграций, чтобы запустить классификатор и автоматически классифицировать входящий текст в ваших любимых приложениях с нулевыми строками кода:
Визуализируйте свои классификационные данные
Теперь, когда вы создали классификатор, пришло время представить ваши результаты яркими визуальными деталями. Платформы визуализации бизнес-аналитики позволяют видеть широкий обзор данных или детальные результаты.
MonkeyLearn Studio — это универсальный инструмент для анализа и визуализации текстовых данных. Выберите необходимые методы классификации (и другие) и выполняйте их вместе — от сбора данных до организации, анализа и визуализации. Все это работает в едином бесшовном интерфейсе.
Взгляните на панель управления MonkeyLearn Studio. Поиск по аспекту, настроению и т. Д. Вы можете добавлять или удалять анализы или изменять данные прямо в панели управления браузера и мгновенно просматривать результаты.
Взгляните на приведенный ниже пример, в котором мы провели анализ настроений на основе аспектов по отзывам клиентов о Zoom.Каждый отзыв классифицируется по юзабилити, поддержке, надежности, и т. Д., Затем анализируется тональность, чтобы показать мнение автора.
Отдельные обзоры упорядочены по дате и времени, чтобы соответствовать категориям и настроениям по мере их изменения с течением времени.
Поэкспериментируйте с общедоступной информационной панелью MonkeyLearn Studio, чтобы убедиться, насколько легко ею пользоваться.
Takeaway
Классификация текста может стать вашим новым секретным оружием для создания передовых систем и организации деловой информации.Превращение ваших текстовых данных в количественные данные невероятно полезно для получения практических сведений и принятия бизнес-решений. Кроме того, автоматизация выполняемых вручную и повторяющихся задач поможет вам сделать больше.
Вы заинтересованы в создании своего первого классификатора текста? Посетите MonkeyLearn и сразу же начните экспериментировать. Вы можете быстро создавать текстовые классификаторы с помощью машинного обучения, используя наш простой в использовании пользовательский интерфейс (кодирование не требуется!), И использовать их с помощью нашего API или интеграции.
Посетите MonkeyLearn Studio и запросите демонстрацию, чтобы увидеть, что анализ текста и визуализация данных могут сделать для вашего бизнеса.
Есть вопросы? Свяжитесь с нами, и мы поможем вам начать работу с классификацией текста.
5 Подходы к аналитике текста: всесторонний обзор
Получаете ли вы больше отзывов, чем могли бы прочитать, не говоря уже о том, чтобы подвести итоги? Может быть, вы использовали методы Text Analytics для анализа отзывов в произвольной форме?
Эти методы варьируются от простых методов, таких как сопоставление слов в Excel, до нейронных сетей, обученных на миллионах точек данных.
Вот мое резюме, чтобы разбить эти методы на 5 основных подходов, которые обычно используются сегодня.
Что такое текстовая аналитика?
Текстовая аналитика — это процесс извлечения смысла из текста. Например, это может быть анализ текста, написанного клиентами в ходе опроса клиентов, с упором на поиск общих тем и тенденций. Идея состоит в том, чтобы иметь возможность изучать отзывы клиентов, чтобы информировать бизнес о стратегических действиях, направленных на улучшение качества обслуживания клиентов.
Что такое программа для анализа текста?
Чтобы сделать аналитику текста максимально эффективной, организации могут использовать программное обеспечение для анализа текста, используя алгоритмы машинного обучения и обработки естественного языка для поиска смысла в огромных объемах текста.
Как компании используют текстовую аналитику?
Чтобы взять в качестве примера тематику, мы анализируем отзывы в виде произвольного текста, представленные в формах отзывов клиентов, которые ранее было трудно анализировать, поскольку компании тратят время и ресурсы, пытаясь сделать это вручную.
Впоследствии мы используем текстовую аналитику, чтобы помочь компаниям найти скрытые данные о клиентах и получить возможность легко отвечать на вопросы об имеющихся у них данных о клиентах. Кроме того, с помощью программного обеспечения для анализа текста, такого как Thematic, компании могут находить повторяющиеся и возникающие темы, отслеживать тенденции и проблемы и создавать визуальные отчеты для менеджеров, чтобы отслеживать, замыкают ли они цикл с конечным клиентом.
Немного об аналитике текста…
В течение долгого времени я планировал написать пост, чтобы прояснить, что возможно в текстовой аналитике сегодня, в 2018 году.
На протяжении своей карьеры я разговаривал со многими, кто переживает боль анализа текста и пытается найти решение.
Некоторые пытаются изобрести велосипед, написав свои собственные алгоритмы с нуля, другие считают, что Google и IBM API — спасители, другие снова застряли на технологиях конца 90-х, которые поставщики называют «продвинутой текстовой аналитикой».
Последние 15 лет я посвятил обработке естественного языка, особенно в области понимания текста с помощью алгоритмов: исследования, создания, применения и продажи лежащих в их основе технологий.
В результате моих научных исследований были найдены алгоритмы, используемые сотнями организаций (я автор книг KEA и Maui). Изюминкой моей карьеры текстового аналитика стала компания Google, где я написал алгоритм, который может анализировать текст на языках, на которых я не говорю.
И за последние 3 года, будучи генеральным директором компании Thematic, я многое узнал о том, что доступно на рынке.
Итак, будет справедливо сказать, что я имею право говорить на эту тему.
Я постараюсь быть объективным в своем обзоре, но , конечно, я предвзято отношусь к из-за своей позиции. Рад обсудить это со всеми, кто заинтересован в обратной связи.
5 методов и примеров текстовой аналитики
Вот мое резюме, чтобы разбить эти методы на 5 основных подходов, которые обычно используются сегодня.
Подход 1 к аналитике текста: обнаружение слов
Давайте начнем с слов, найдя .Во-первых, это не вещь!
Академическое сообщество по обработке естественного языка не поддерживает такой подход, и это правильно. Фактически, в академическом мире определение слов относится к распознаванию почерка (определение того, какое слово написал человек, возможно, врач).
Есть также определение ключевых слов, которое фокусируется на обработке речи.
Но, насколько мне известно, выделение слов не используется ни для какого типа анализа текста .
Но я слышал об этом достаточно часто на собраниях, чтобы включить его в этот обзор.Его любят домашние аналитики и мастера Excel, и он пользуется популярностью среди многих профессионалов в области клиентского анализа.
Основная идея выделения текстовых слов заключается в следующем: если слово появляется в тексте, мы можем предположить, что этот фрагмент текста «о» конкретном слове. Например, если в обзоре упоминаются такие слова, как «цена» или «стоимость», это означает, что этот обзор посвящен «цене».
Прелесть метода определения слов в простоте.
Вы можете реализовать выделение слов в электронной таблице Excel менее чем за 10 минут.
Или вы можете написать сценарий на Python или R. Вот как это сделать.
Как создать решение для анализа текста за 10 минут
Вы можете ввести формулу, подобную этой, в Excel, чтобы разделить комментарии на «Выставление счетов», «Цены» и «Простота использования»:
И вуаля!
Здесь он применяется к опросу Net Promoter Score, где столбец B содержит открытые ответы на вопросы «Почему вы дали нам эту оценку»:
На его создание у меня, наверное, ушло меньше 10 минут, и результат так обнадеживает! Но подождите…
Все любят простоту.Но в данном случае простота — отстой
При таком подходе могут легко возникнуть различные проблемы.
Вот, я их вам пометил.
Из 7 комментариев здесь только 3 были отнесены к категории правильно. «Биллинг» на самом деле связан с «ценой», и в трех других комментариях пропущены дополнительные темы. Вы бы поставили свою точку зрения на то, что в лучшем случае точнее на 50?
Когда определение слов в порядке
Вы можете себе представить, что формулу выше можно изменить дальше.И действительно, я разговаривал с компаниями, которые вручную создавали огромные таблицы на заказ, и очень довольны результатами.
Если у вас есть набор данных с парой сотен ответов, которые вам нужно проанализировать только один или два раза, вы можете использовать этот подход. Если набор данных невелик, вы можете очень быстро просмотреть результаты и обеспечить высокую точность.
Когда определение слов не удается
Что касается обратной стороны? Пожалуйста, не используйте определение слов:
- Если у вас есть значительный объем данных, более нескольких сотен ответов
- Если у вас нет времени проверять и исправлять точность каждого фрагмента текста
- Если вам нужно визуализировать результаты (Excel услышит вашу ругань)
- Если вам нужно поделиться результатами с коллегами
- Если вам необходимо постоянно поддерживать данные
У самодельного выделения слов есть много других недостатков, которые мы обсудим в следующем посте.Я также расскажу о том, что на самом деле работает и является хорошим подходом.
Если вы хотите создать собственное решение для анализа текста, ознакомьтесь с нашим подробным руководством: Как создать собственное решение для анализа отзывов.
Подход к аналитике текста 2. Ручные правила
Подход «Ручные правила» тесно связан с распознаванием слов. Оба подхода работают по одному и тому же принципу создания шаблона соответствия, но эти шаблоны также могут быть довольно сложными.
Например, ручное правило может включать использование регулярных выражений, что нелегко реализовать в Excel.Вот правило присвоения категории «Знания персонала» популярного корпоративного решения Medallia:
Большинство поставщиков текстовой аналитики, а также многие другие более мелкие игроки, которые продают текстовую аналитику в качестве дополнения к своему основному предложению, предоставляют интерфейс, который упрощает создание таких правил и управление ими. Иногда они также предлагают профессиональные услуги, чтобы помочь в создании этих правил.
Самое лучшее в ручных правилах — это то, что их может понять человек.Они объяснимы и, следовательно, могут быть изменены и скорректированы при необходимости.
Но суть в том, что создание этих правил требует больших усилий. Вам также необходимо убедиться, что они точны, и поддерживать их в течение долгого времени.
Для начала некоторые компании поставляют готовые правила, уже организованные в таксономию. Например, у них будет категория «Цена» с заранее установленными сотнями слов и фраз, а под ними могут быть подкатегории, такие как «Дешево» и «Дорогой».
Они также могут иметь определенные категории, настроенные для определенных отраслей, например банки. А если вы банк, вам просто нужно добавить названия своих продуктов в эту таксономию, и все готово.
Преимущество этого подхода заключается в том, что после настройки вы можете запускать миллионы частей обратной связи и получать хороший обзор основных категорий, упомянутых в тексте.
Но у этого подхода много недостатков, как и у любых ручных правил и техники выделения слов:
1.Наличие нескольких значений слов затрудняет создание правил
Наиболее частая причина того, что правила не работают, происходит от многозначности , когда одно и то же слово может иметь разные значения:
2. Упомянутое слово! = Основная тема
Тот факт, что слово или фраза упоминается в тексте, не всегда означает, что текст посвящен этой теме. Например, когда клиент объясняет ситуацию, которая приводит к проблеме: « Моя кредитная карта была отклонена, и кассир был очень любезен, терпеливо ждал, пока я искал наличные в сумке .«Этот комментарий не о кредитных картах или наличных деньгах, а о поведении персонала.
3. Правила не могут уловить настроения
Одного знания общей категории недостаточно. Как люди думают о «Прайсе», счастливы они или нет? Улавливание настроений с помощью заранее установленных вручную правил невозможно. Люди часто не осознают, насколько разнообразен и разнообразен наш язык.
Итак, такую подкатегорию, как «дорогие», на самом деле чрезвычайно сложно смоделировать.Человек мог сказать что-то вроде « Я не думал, что этот продукт был дорогим ». Чтобы отнести этот комментарий к категории «хорошая цена», вам понадобится сложный алгоритм для обнаружения отрицания и его объема. Простое регулярное выражение не поможет.
4. Таксономии программных продуктов и многих других предприятий не существует
Предустановленные таксономии с правилами не будут существовать для нестандартных продуктов или услуг. Это особенно проблематично для индустрии программного обеспечения, где каждый продукт уникален, а отзывы клиентов говорят об очень конкретных проблемах.
5.Не все могут соблюдать правила
В любой отрасли, даже если у вас есть работающая таксономия, основанная на правилах, кому-то с хорошими лингвистическими знаниями потребуется постоянно поддерживать правила, чтобы гарантировать, что все отзывы точно классифицированы. Этому человеку нужно будет постоянно искать новые выражения, которые люди так легко создают на лету, а также любые возникающие темы, которые ранее не рассматривались. Это бесконечный процесс, который стоит очень дорого.
И все же, несмотря на эти недостатки, этот подход является наиболее широко используемым коммерческим приложением Text Analytics, уходящим корнями в 90-е годы, и нет четкого пути для решения этих проблем.
Итак, достаточно ли хороши ручные правила?
Мой ответ: Нет . Большинство людей, использующих ручные правила, недовольны временем, необходимым для настройки решения, затратами на его поддержку и действенностью полученных идей.
Подход к аналитике текста 3. Категоризация текста
Давайте внесем некоторую ясность в беспорядочную тему Advanced Text Analytics в том виде, как ее предлагают различные поставщики и специалисты по обработке данных.
Здесь мы рассмотрим Классификация текста , первый из трех подходов, которые фактически автоматизированы и используют алгоритмы.
Что такое категоризация текста?
Этот подход основан на машинном обучении. Основная идея состоит в том, что алгоритм машинного обучения (их много) анализирует ранее классифицированные вручную примеры (данные обучения) и определяет правила категоризации новых примеров. Это контролируемый подход.
Прелесть категоризации текста в том, что вам просто нужно предоставить примеры, не требуется ручного создания шаблонов или правил, в отличие от двух предыдущих подходов.
Еще одно преимущество категоризации текста состоит в том, что теоретически она должна улавливать относительную важность вхождения слова в текст. Вернемся к примеру из предыдущих сообщений. Клиент может объяснять ситуацию, которая приводит к проблеме: «Моя кредитная карта была отклонена, и кассир был очень любезен, терпеливо ждал, пока я искал наличные в сумке». Этот комментарий не о кредитных картах или наличных деньгах, а о поведении персонала. Тема «кредитная карта», упомянутая в комментарии, не важна, но важны «услужливость» и «терпение».Подход к категоризации текста может уловить это при правильном обучении.
Все сводится к тому, чтобы увидеть похожие примеры в обучающих данных.
Почти идеальная точность… но только с правильными данными обучения
Существуют научные исследования, которые показывают, что категоризация текста позволяет достичь почти идеальной точности. Алгоритмы глубокого обучения даже более мощные, чем старые наивные алгоритмы (один из старых алгоритмов на самом деле называется наивным байесовским).
И все же все исследователи согласны с тем, что алгоритм не так важен, как данные обучения .
Качество и количество обучающих данных являются решающим фактором в том, насколько успешен этот подход для работы с обратной связью. Итак, сколько достаточно? Ну, это зависит от количества категорий и алгоритма, используемого для создания модели категоризации.
Чем больше у вас категорий и чем теснее они связаны, тем больше обучающих данных необходимо, чтобы алгоритм мог различать их.
Некоторые из новых стартапов Text Analytics, которые полагаются на категоризацию текста, предоставляют инструменты, которые позволяют людям легко обучать алгоритмы, чтобы они со временем становились лучше. Но есть ли у вас время подождать, пока алгоритм станет лучше, или вам нужно действовать в соответствии с отзывами клиентов уже сегодня?
Четыре проблемы с категоризацией текста
Помимо необходимости обучения алгоритма, есть еще четыре проблемы с использованием категоризации текста для анализа отзывов людей:
- Вы не заметите возникающих тем
Вы узнаете только те категории, для которых вы тренировались, и пропустите неизвестные неизвестные.Это тот же недостаток, что и ручные правила и определение слов: необходимость постоянно отслеживать поступающие отзывы на предмет возникающих тем и неправильно классифицированных элементов.
- Непрозрачность
Хотя алгоритм со временем становится лучше, невозможно понять, почему он работает так, как он работает, и, следовательно, легко изменить результаты. Качественные исследователи сказали мне, что отсутствие прозрачности — основная причина, по которой категоризация текста не стала популярной в их мире.Например, если внезапно наблюдается низкая точность различения между двумя темами «время ожидания для установки волокна» и «время ожидания на телефоне для настройки волокна», сколько обучающих данных нужно добавить, пока алгоритм не перестанет их делать. ошибки?
- Подготовка данных обучения и управление ими — сложная задача
Отсутствие обучающих данных — реальная проблема. Трудно начать с нуля, и у большинства компаний нет достаточно точных данных для обучения алгоритмов.Фактически, компании всегда переоценивают объем имеющихся у них обучающих данных, из-за чего реализация не оправдывает ожиданий. И, наконец, если вам нужно уточнить одну конкретную категорию, вам нужно будет заново разметить все данные.
- Переобучение для каждого нового набора данных
Передача может быть действительно проблематичной! Представьте, что у вас есть рабочее решение для категоризации текста для одного из ваших отделов, например support, и теперь хотите анализировать отзывы, полученные в ходе опросов клиентов, таких как NPS или CSAT.Опять же, вам нужно будет заново обучить алгоритм.
Я только что разговаривал по телефону с профильным экспертом по анализу опросов, который рассказал мне такую историю: группа специалистов по данным потратила много месяцев и создала решение, которое ей в конечном итоге пришлось отклонить из-за недостаточной точности. У компании не было времени ждать, пока алгоритм со временем улучшится.
Подход 4: Тематическое моделирование
Тематическое моделирование — это тоже подход машинного обучения, но неконтролируемый, что означает, что этот подход учится на необработанном тексте.Звучит захватывающе, правда?
Иногда я слышу, как профессионалы в области аналитики называют любой подход машинного обучения «тематическим моделированием», но специалисты по данным обычно имеют в виду конкретный алгоритм, когда говорят «тематическое моделирование».
Он называется LDA, аббревиатура от запутанного скрытого распределения Дирихле. Это элегантная математическая модель языка, которая фиксирует темы (списки похожих слов) и то, как они охватывают различные тексты.
Пример тематического моделирования в действии
Вот пример применения тематического моделирования к обзорам пива:
- На входе рецензии на разные сорта пива
- Тема — это набор похожих слов, таких как кофе, темный, шоколад, черный, эспрессо
- Каждому обзору присваивается список тем.В этом примере для The Kernel Export stout London назначены 4 темы.
Темы также можно взвешивать. Например, комментарий клиента типа « у вас ужасная служба поддержки, получите номер телефона », может иметь следующие веса и темы:
- 40% поддержка, обслуживание, персонал
- 30% плохо, плохо, плохо
- 28% номер, телефон, электронная почта, звонок
Что хорошего в тематическом моделировании
Самое лучшее в тематическом моделировании — это то, что оно не требует никаких вводных данных, кроме необработанных отзывов клиентов.Как уже упоминалось, в отличие от категоризации текста, она не контролируется. Проще говоря, обучение происходит путем наблюдения за тем, какие слова появляются рядом с другими словами в каких обзорах, и сбора этой информации с использованием статистики вероятности. Если вы увлекаетесь математикой, вам понравится концепция, подробно объясненная в соответствующей статье в Википедии, и если этих формул слишком много, я рекомендую объяснение Джойс Сюй.
Существуют стартапы по аналитике текста, которые используют тематическое моделирование для анализа отзывов и других наборов текстовых данных.Другие компании, такие как StitchFix, например, используют тематическое моделирование для выработки рекомендаций по продуктам. Они расширили традиционное моделирование тем с помощью техники глубокого обучения, называемой встраиванием слов. Это позволяет более точно улавливать семантику (подробнее об этом в нашей части 5).
Почему тематическое моделирование является неадекватным методом анализа обратной связи
При использовании для анализа обратной связи тематическое моделирование имеет один главный недостаток:
Смысл тем действительно сложно интерпретировать
Каждая тема отражает некоторые аспекты языка, но непрозрачным алгоритмическим способом, который отличается от того, как люди понимают язык.Например, как бы вы интерпретировали вторую и четвертую темы для крепкого пива в приведенном выше примере:
В то время как первую и вторую темы можно как-то «назвать» сладостью и фруктовостью, две другие темы — это просто набор слов.
Любой специалист по данным может собрать решение, используя публичные библиотеки, которые могут быстро выдать несколько значимый результат. Однако превратить эти результаты в диаграммы и графики, которые могут помочь в принятии бизнес-решений, сложно.Еще сложнее отслеживать, как конкретная тема меняется с течением времени, чтобы определить, работают ли предпринятые действия.
Подводя итог, поскольку тематическое моделирование дает результаты, которые трудно интерпретировать из-за отсутствия прозрачности, как это делают алгоритмы категоризации текста, я не рекомендую этот подход для анализа обратной связи. Тем не менее, я придерживаюсь алгоритма, который может достаточно хорошо фиксировать языковые свойства, и который действительно хорошо работает в других задачах, требующих понимания естественного языка.
Подход 5. Тематический анализ (плюс наш секретный соус о том, как сделать его еще лучше)
Все вышеперечисленные подходы имеют недостатки. В лучшем случае вы получите хорошие результаты только после того, как потратите много месяцев на настройку. И вы можете упустить что-то неизвестное.
Цена опоздания или упущения важных идей огромна! Это может привести к потере клиентов и застойному росту. Вот почему, согласно YCombinator (ускоритель стартапов, который произвел больше компаний на миллиард долларов, чем любой другой), «всякий раз, когда вы не работаете над своим продуктом, вы должны общаться со своими пользователями».
После того, как Thematic приняла участие в их программе, нас трижды просили дать совет в ходе опроса, один раз — по личной электронной почте, а также лично. YCombinator также использует тематику, чтобы анализировать все отзывы, которые они собирают.
Когда дело доходит до отзывов клиентов, важны три вещи:
- Точный, конкретный и действенный анализ
- Возможность быстро видеть возникающие темы без необходимости настраивать
- Прозрачность в том, как создаются результаты, чтобы привнести опыт в предметной области и здравый смысл
В ходе своего исследования я узнал, что единственный подход, который может удовлетворить все три требования, — это тематический анализ в сочетании с интерфейсом для простого редактирования результатов.
Тематический анализ: как это работает
Тематический анализ подходы извлекают темы из текста, а не классифицируют текст. Другими словами, это восходящий анализ. Принимая во внимание такие отзывы, как «Стюардесса была полезна, когда я попросила установить детскую кроватку», они извлекали такие темы, как «бортпроводник», «бортпроводник был полезен», «полезен», «попросил установить до детской кроватки »и« детской кроватки ».
Это все содержательные фразы, которые потенциально могут быть полезны при анализе всего набора данных.
Однако наиболее важным шагом в подходе к тематическому анализу является объединение похожих фраз в темы и их организация таким образом, чтобы людям было легко просматривать и редактировать. Мы достигаем этого с помощью нашей собственной реализации встраивания слов, но есть разные способы добиться этого.
Например, вот как три человека говорят об одном и том же, и как мы в Thematic группируем результаты по темам и подтемам:
Преимущества и недостатки тематического анализа
Преимущество тематического анализа в том, что этот подход является неконтролируемым, что означает, что вам не нужно заранее настраивать эти категории, не нужно обучать алгоритм и, следовательно, вы можете легко фиксировать неизвестные неизвестные.
Недостатки этого подхода в том, что его сложно реализовать правильно. Идеальный подход должен уметь объединять и организовывать темы осмысленным образом, создавая набор тем, которые не являются слишком общими и не слишком большими. В идеале темы должны охватывать не менее 80% дословных (человеческих комментариев). И извлечение тем должно обрабатывать сложные предложения отрицания, например «Я не думал, что это хороший кофе».
Кто занимается тематическим анализом?
Некоторые из авторитетных крупных игроков внедрили тематический анализ для улучшения своих подходов к ручным правилам, но, как правило, создают подробный список терминов, которые трудно проанализировать.
Традиционные API аналитики текста, разработанные экспертами в области НЛП, также используют этот подход. Однако они редко разрабатываются с учетом отзывов клиентов и пытаются решить эту проблему общим способом. Например, когда мы тестировали API Google и Microsoft, мы обнаружили, что они не группируют темы из коробки.
В результате только от 20 до 40% отзывов связаны с 10 основными темами: только тогда, когда есть сильное сходство в том, как люди говорят о конкретных вещах. Подавляющее большинство отзывов не классифицировано, что означает, что вы не можете разрезать данные для более глубокого понимания.
В Thematic мы разработали подход тематического анализа, который позволяет легко анализировать отзывы клиентов служб доставки пиццы, создателей музыкальных приложений, брокеров по недвижимости и многих других. Мы достигли этого, сосредоточив внимание на конкретном типе текста: отзывы клиентов, в отличие от API-интерфейсов NLP, которые предназначены для работы с любым типом текста. Мы реализовали сложные алгоритмы отрицания, которые отделяют позитивные темы от негативных, чтобы обеспечить лучшее понимание.
Наш секретный соус: Человек в петле
Каждый набор данных, а иногда даже каждый вопрос опроса, получает свой собственный набор тем, и с помощью нашего редактора тем специалисты по аналитике могут уточнить темы в соответствии с их бизнесом.Например, тематический поиск может найти такие темы, как «быстрая доставка», «быстро и легко», «час ожидания», «медленное обслуживание», «задержки в доставке» и сгруппировать их в «скорость обслуживания». Один специалист по инсайтам может перегруппировать их на «медленное» и «быстрое» в разделе «скорость обслуживания», другой — на «быстрое обслуживание»> «быстрое и легкое» и «медленное обслуживание» -> «час ожидания», « задержки в доставке ». Это субъективная задача.
Я считаю, что все больше и больше компаний будут открывать для себя тематический анализ, потому что, в отличие от всех других подходов, это прозрачный и глубокий анализ, который не требует данных обучения или времени для создания правил вручную.
Что вы думаете?
Какой подход вам подходит?
Мы создали шпаргалку, в которой перечислены подходы к аналитике текста. Ознакомьтесь с ней ниже
.
Хотите попробовать Thematic бесплатно? Давайте начнем.
Обобщение текста
с помощью Gensim (алгоритм TextRank) | by Shivangi Sareen
- Методы извлечения — Включает выбор фраз и предложений из исходного документа для создания нового резюме.
- Абстрактивные методы — Он включает в себя создание совершенно новых фраз и предложений, чтобы передать смысл исходного документа.
Gensim — это бесплатная библиотека Python, предназначенная для автоматического извлечения семантических тем из документов.
Реализация gensim основана на популярном алгоритме TextRank .
Это набор инструментов для моделирования векторного пространства и тематического моделирования с открытым исходным кодом, реализованный на языке программирования Python с использованием NumPy , SciPy и, опционально, Cython для повышения производительности.
Обобщение текста с помощью Gensim (алгоритм TextRank) —
Мы используем summarization.summarizer от gensim.
Это суммирование основано на ранжировании текстовых предложений с использованием варианта алгоритма TextRank.
TextRank — это универсальный алгоритм ранжирования на основе графа для НЛП.
TextRank — это метод автоматического суммирования.
Алгоритмы ранжирования на основе графов — это способ определения важности вершины в графе на основе глобальной информации, рекурсивно извлекаемой из всего графа.
Модель TextRank —
Основная идея, реализованная в графической модели ранжирования, состоит в том, что голосует, или рекомендация .
Когда одна вершина соединяется с другой, она в основном голосует за эту вершину. Чем больше голосов отдано за вершину, тем выше важность этой вершины.
Текст в виде графика —
Нам нужно построить граф, который представляет текст, соединяет слова или другие текстовые объекты осмысленными отношениями.
TextRank включает две задачи НЛП —
- Задача извлечения ключевого слова
- Задача извлечения предложения
Извлечение ключевого слова —
Задача алгоритма извлечения ключевого слова состоит в том, чтобы автоматически идентифицировать в тексте набор терминов, которые лучше всего описывают документ.
Самый простой подход — использовать частотный критерий.
ОДНАКО это приводит к плохим результатам.
Алгоритм извлечения ключевых слов TextRank полностью неконтролируемый.Никакого обучения не требуется.
Извлечение предложений —
TextRank очень хорошо подходит для приложений, включающих целые предложения, поскольку он позволяет выполнять ранжирование по текстовым единицам, которое рекурсивно вычисляется на основе информации, извлеченной из всего текста.
Чтобы применить TextRank, мы сначала строим граф, связанный с текстом, где вершины графа являются репрезентативными для единиц, подлежащих ранжированию. Цель состоит в том, чтобы ранжировать целые предложения, поэтому к графу добавляется вершина для каждого предложения в тексте.
Алгоритм PageRank —
Это основа TextRank.
- PageRank, используемый поиском Google.
- Используется для вычисления рейтинга веб-страниц. Он назван не в честь его использования (ранжирование страниц), а в честь его создателя Ларри Пейджа.
Основные принципы —
- Важные страницы связаны между собой важными страницами.
- Значение PageRank страницы — это вероятность того, что пользователь посетит эту страницу.
В TextRank единственное отличие состоит в том, что мы рассматриваем предложения, а не страницы.
Полнотекстовый поиск: как это работает — блог ISS Art | AI | Машинное обучение
Что такое полнотекстовый поиск?
Полнотекстовый поиск — это методика, позволяющая вести поиск в документах и базах данных не только по заголовку, но и по содержанию. В отличие от методов поиска по метаданным, которые анализируют только описание документа, полнотекстовый поиск просматривает все слова в документе, показывая более релевантную информацию или точную информацию, которая была запрошена.
Техника приобрела популярность в 1990-х годах. В то время процесс сканирования был очень долгим и трудоемким, поэтому его оптимизировали.
Полнотекстовые поисковые системы широко используются. Например, Google позволяет пользователям находить нужный запрос на веб-страницах именно с помощью этой техники. Если у вас есть собственный веб-сайт с большим количеством данных, применение полнотекстового поиска может быть очень полезным, поскольку оно упрощает взаимодействие с пользователем.
Зачем это нужно?
Полнотекстовый поиск может быть полезен, когда нужно искать:
- имя человека в списке или базе данных;
- слово или фраза в документе;
- веб-страница в Интернете;
- товаров в интернет-магазине и др.
- регулярное выражение.
Результаты полнотекстового поиска могут использоваться в качестве входных данных для замены фраз и в процессе поиска родственных словоформ и т. Д.
Как это сделать?
Существуют разные способы реализации полнотекстового поиска. Мы можем выбрать любой, в зависимости от случая. Чтобы было проще, разделим методы на две группы:
1. Алгоритмы поиска строк . Чтобы найти совпадение подстроки с шаблоном (необходимым выражением) в тексте, мы будем просматривать документы, пока не будет найдено совпадение или текст не будет завершен.На самом деле, большинство из этих методов довольно медленные.
Алгоритмы поиска строк:
- простой текстовый поиск;
- алгоритм Рабина-Карпа;
- алгоритм Кнута-Морриса-Пратта;
- Алгоритм Бойера-Мура (-Хорспул);
- приблизительное соответствие;
- регулярное выражение.
Простой текстовый поиск действительно просто реализовать. Этот алгоритм ищет совпадения по буквам. Вот почему на это уходит много времени.
Алгоритм Рабина-Карпа может использовать несколько шаблонов. Он выполняет поиск, ища строку длины m (шаблон) в тексте длины n. Но сначала для каждой подстроки в тексте должна быть создана специальная метка, отпечаток пальца той же длины, что и шаблон. Только при совпадении отпечатков пальцев алгоритм начинает сравнивать буквы.
Чтобы создать отпечаток пальца, алгоритм использует хеш-функцию для сопоставления данных произвольного размера с фиксированным размером. Таким образом, реализация хеш-функции и сравнение отпечатков пальцев позволяет сократить среднее время работы.
Этот алгоритм хорош для проверки на антиплагиат. Он может просматривать множество файлов, сравнивая шаблоны документов с файлами в базе данных.
Алгоритм Кнута-Морриса-Пратта
Этот алгоритм использует информацию о шаблоне и тексте для ускорения поиска за счет смещения позиции сравнения. Он основан на частичном совпадении.
Например, мы ищем «морж» в скороговорке «Уэйн уехал в Уэльс посмотреть на моржей». Выбираем первую букву « w alrus» и начинаем сравнивать.Сначала алгоритм проверяет «Уэйн», но, достигнув «y», понимает, что это не совпадение. После этого он переходит к поиску совпадений. Поскольку он знает, что второй и третий символы не являются «w», он может пропустить их и начать поиск со следующего. Каждый раз, когда алгоритм обнаруживает несоответствие, шаблон движется вперед в соответствии с ранее упомянутым принципом, пока не будет найдено совпадение или текст не будет закончен.
« Wa yne w ent to Wal es to wa tch морж es».Все расчеты хранятся в сменных таблицах.
Алгоритм Бойера-Мура похож на алгоритм Кнута-Морриса-Пратта, но более сложен. Он известен как первый алгоритм, который не сравнивал каждый символ в тексте. Он работает в обратном направлении, выполняя поиск справа налево от шаблона. Кроме того, у него есть такие расширения, как эвристика: алгоритм, который может на основе информации на каждом шаге ветвления решать, какую ветвь следовать. Они известны как правила сдвига: правило хорошего суффикса и правило плохого символа.Они позволяют перемещать положение символа, если мы знаем, что этот символ отсутствует в шаблоне. Для этого алгоритм выполняет предварительные вычисления в шаблоне, но не в искомом тексте (строке).
Эта концепция называется фильтрацией. И та часть текста, которая становится видимой из-за шаблона смещения по сравнению с окном, через которое алгоритм получает необходимую информацию для проведения поиска. Эти правила определяют, сколько символов будет пропущено. Для этого во время обработки шаблона алгоритм генерирует справочные таблицы.
Давайте подробнее рассмотрим правила смены. Правило плохого символа позволяет пропускать один или несколько несовпадающих символов. Например, узор «Миссисипи». Как работает правило плохого символа:
Проверяет совпадение с «хвоста». Если не найден, перейдите к соответствующему символу в шаблоне, чтобы продолжить поиск совпадений.
********** S ******************
MISSISSIPP I
********** S *** I ***
MISSIS S IPP I
Если такой символ не существует в шаблоне, шаблон перемещается мимо проверенный символ.
********** E ******************
MISSISSIPP I
********** E ********** P *******
MISSISSIPP I
Правило хорошего суффикса дополняет правило плохого символа и включается в работу, когда обнаруживается несколько совпадений, но затем проверка не удалась. Например,
******** сола **************
колакока кола
******** sola ******* o ******
cola cocacol a
Возможность перепрыгивать через текст и не проверять каждый символ делает этот алгоритм настолько эффективным.Однако его сложно реализовать. Две эвристики дают алгоритму выбор. Он выбирает сдвиг, который дает больший сдвиг. Хорошо использовать, когда предварительная обработка текста невозможна.
Одним из примеров вымирания является алгоритм Бойера-Мура-Хорспула . Это упрощенная версия алгоритма Бойера-Мура, в которой используется только одна эвристика: правило плохого символа. А также у него есть новая функция. Текст и узор можно сравнивать в любом порядке, даже слева направо.Все это делает алгоритм Бойера-Мура-Хорспула более быстрым, чем его предшественник.
Алгоритм приблизительного соответствия или поиск по нечеткой строке запускает поиск, который находит близкое совпадение, а не точное. Для реализации поиска алгоритм находит приблизительную подстроку с меньшим расстоянием редактирования: количество примитивных операций, необходимых для преобразования одной строки в другую. Примитивные действия следующие:
вставка: конус → конус y ;
делеция: t ржавчина → ржавчина ;
замена: м o ст → м u st ;
транспозиция: c l oud → cou l d .
Кроме того, этот алгоритм позволяет выполнять поиск, используя в шаблоне символ NULL, например «?». Например,
str ? нг → стр. и нг, стр.? нг → стр. или нг, стр.? нг. → стр. и нг. В результате наиболее близкими будут первые два варианта из-за меньшего расстояния редактирования.
Алгоритм регулярных выражений или регулярное выражение позволяет выполнять поиск в строках, следующих определенному шаблону. Он основан на использовании дерева регулярных выражений для сопоставления и имеет несколько специфических функций.Один из них позволяет находить составные символы, например («www», «США»). Другой дает возможность поиска по списку опций (например, (jpeg | jpg) будет соответствовать строке «jpeg» и строке «jpg»). И последний позволяет упростить шаблон запроса и искать повторяющийся шаблон, например. грамм. «(1 | 0) *» будет соответствовать любому двоичному тексту, например «011010» или «100111».
2. Индексированный поиск . Когда область поиска велика, разумным решением является предварительное создание индекса условий поиска.Относитесь к нему как к глоссарию с номерами страниц, на которых упоминается термин, который вы можете заметить в конце некоторых книг или статей. Итак, полнотекстовый поиск состоит из двух этапов. На первом этапе алгоритм формирует такой индекс, или, точнее говоря, соответствие, поскольку он содержит термин вместе со ссылкой, чтобы найти их в тексте (например, «Предложение 3, номер символа 125». После этого индекс алгоритм поиска сканирует индекс, а не исходный набор документов, и выдает результаты.
Как вы заметили, этот подход требует много времени для создания индекса, но тогда гораздо быстрее искать информацию в документах с помощью индекса, чем простые методы поиска по строкам.
Важной частью индексации является нормализация. Это текстовый редактор, который приводит исходный текст в стандартную каноническую форму. Это означает, что стоп-слова и артикли удаляются, диакритические знаки (например, в словах «pâté», «naïve», «złoty») удаляются или заменяются стандартными знаками алфавита.Также выбирается одиночный регистр (только верхний или нижний). Еще одна важная часть нормализации — это остановка. Это процесс сокращения слова до основной или основной формы. Например, у слов «ест», «ел», «съел» корень имеет форму «есть». Таким образом, поисковый запрос «веганы, едящие мясной паштет, снятый на пленку» преобразуется в «веган ест мясной паштет». Кроме того, очень важно указать язык, на котором алгоритм будет работать, и даже орфографию (например, английский, американский, австралийский, южноафриканский и т. Д.).).
Проблемы с реализацией полнотекстового поиска
Создание полноценной полнотекстовой поисковой машины требует тщательной разработки и решения множества поисковых задач.
Самая большая и самая распространенная проблема, с которой сталкиваются разработчики, — это проблема синонимов. Любой язык богат, и любой термин может быть выражен разными вариантами. Это могут быть варианты названия, например ветряная оспа и ветряная оспа, варианты написания, например «Мечтали» и «мечтали».
Еще один аспект проблемы синонимов, который может вызвать затруднения, — это использование сокращений (TV, Dr., Проф.) Аббревиатуры (GIF, FAQ) и инициалы. Как и в предыдущем примере, некоторые документы могут просто не содержать полный или альтернативный вариант.
Наличие диалектов также усложняет поиск. Например, пользователи могут не встретить результаты «цвет», запрос «цвет» или поиск по запросу «тренер» найти обувь вместо наставника.
Та же проблема с устаревшими терминами. Если вы введете в Google современный термин, вы, скорее всего, пропустите ресурсы, которые раскрывают проблему с использованием только устаревшей терминологии.
Еще одна проблема — омонимы.Эти слова, написанные одинаково, означают совершенно разные вещи. При поиске таких слов, как «принц», пользователь видит результаты о членах королевской семьи, певце и других. Особенно часто эта проблема возникает с личными именами, а еще чаще со словами, которые действуют как имена, так и другие части речи, например, «лето», «воля», «спенсер» и т. Д.
Второй аспект омонимов проблема ложно родственная. Это случается, когда слово в разных языках имеет одинаковое написание, но разные значения.
Алгоритмы и движки полнотекстового поиска не могут находить результаты по фасетам. Если пользователь запрашивает «Все выпуски New York Times о бизнесе с 1990 по 1995 год», релевантные данные не будут отображаться, поскольку он не знает таких аспектов, как тема и дата публикации, если только он не дополнен поиском по метаданным.
Также обратите внимание, что вам нужны специальные способы включения информации из изображений, аудио- и видеофайлов в список результатов. Другой тип проблем реализации полнотекстового поиска — обеспечение высокой производительности на обоих этапах — индексации и поиска.
Предположим, мы уже создали указатель терминов, который содержит набор документов для моментального снимка текущей даты. Как правило, этот этап может потребовать много времени, но мы можем справиться с ним, если это одноразовая задача. Однако для каждой реальной системы количество информации увеличивается со временем, поэтому нам по-прежнему требуется непрерывное индексирование.
Что касается стадии поиска, мы не можем позволить себе ждать вечно в поисках. Поскольку размер индекса может быть очень большим, простые способы навигации по индексу неэффективны.Поэтому для хранения индекса и навигации по нему используются специальные структуры данных, обычно среди них есть различные типы деревьев и пользовательские структуры.
Итак, в соответствии с вышеупомянутыми проблемами создание системы полнотекстового поиска с нуля — действительно сложный процесс. Поэтому более простой способ, отвечающий большинству потребностей, — использовать готовые решения в качестве полнотекстовых поисковых систем.
Сравнение средств полнотекстового поиска в базах данных и систем полнотекстового поиска
Создавая реляционную базу данных, вы можете подумать, что лучше использовать для поиска данных.Реляционные базы данных хороши для хранения, обновления и управления структурированными данными. Они поддерживают гибкий поиск нескольких типов записей для определенных значений полей. Системы полнотекстового поиска зависят от типа индекса для выполнения поиска, большинство из них имеют возможности обработки результатов сортировки по полю, добавления, удаления и обновления записей, но, тем не менее, их возможности в этом вопросе более ограничены, чем реляционные базы данных ». Но когда дело доходит до актуального отображения результатов, они не на первом месте.
Когда есть необходимость в релевантном ранжировании результатов и обработке больших объемов неструктурированных данных, полнотекстовым поисковым системам нет равных.
Преимущества полнотекстовых поисковых систем:
- Полнотекстовые поисковые системы — это готовые решения, которые можно настроить в соответствии с потребностями вашего проекта. Они содержат все необходимые функции как с лингвистической, так и с технической точки зрения (например, производительность и масштабируемость) для экономии времени.
- Полнотекстовые поисковые системы открыты для улучшения и адаптации, так что вы можете реализовать свой собственный алгоритм поиска в соответствии с вашими потребностями и вставить его в систему.
- Также есть некоторые улучшения (плагины, модули). Системы полнотекстового поиска могут выполнять поиск даже через нетекстовые или ограниченные текстовые поля (например, код продукта, дату публикации и т. Д.), Принимая представление данных, используя тот факт, что каждая запись представляет собой набор полей. Это может быть удобно, если в документе есть более одного типа полей.
Самыми зрелыми и мощными движками являются Apache Solr, Sphinx или ElasticSearch, и мы рекомендуем выбрать один из них в зависимости от потребностей.
У них много общего: они имеют открытый исходный код (хотя у них разные лицензии, и Sphinx требует покупки коммерческой лицензии для использования в коммерческом приложении). Все движки масштабируемы и предлагают коммерческую поддержку.
К основным отличителям можно обратиться здесь:
- Sphinx строго ориентирован на СУБД.
- Solr является наиболее ориентированным на текст и поставляется с несколькими синтаксическими анализаторами, токенизаторами и инструментами стемминга. Он реализован с использованием Java, поэтому его можно легко встроить в приложения JVM.
- Elasticsearch обычно используется для управления журналами, это очень простая вещь в использовании и имеет дополнительные аналитические функции, что очень важно для этой области.
Есть еще много деталей, поэтому вам все равно понадобится опыт, прежде чем вы выберете одну из них для своего проекта. Например, Solr имеет встроенное фасетирование, а Sphinx — нет. А если вам нужно интегрировать полнотекстовый поиск для приложений с большими данными, здесь можно использовать Solr.
И помните, вы всегда можете доверить свой проект профессионалам ISS Art.
% PDF-1.3
%
250 0 объект
>
эндобдж
xref
250 364
0000000016 00000 н.
0000007632 00000 н.
0000011639 00000 п.
0000011857 00000 п.
0000012055 00000 п.
0000012365 00000 п.
0000012627 00000 н.
0000012809 00000 п.
0000013089 00000 п.
0000013349 00000 п.
0000013611 00000 п.
0000013944 00000 п.
0000014154 00000 п.
0000014472 00000 п.
0000014774 00000 п.
0000015044 00000 п.
0000015315 00000 п.
0000015489 00000 н.
0000015799 00000 п.
0000016134 00000 п.
0000016373 00000 п.
0000016753 00000 п.
0000016995 00000 н.
0000017305 00000 п.
0000017598 00000 п.
0000017865 00000 п.
0000018091 00000 п.
0000018416 00000 п.
0000018726 00000 п.
0000018904 00000 п.
0000019101 00000 п.
0000019425 00000 п.
0000019665 00000 п.
0000019981 00000 п.
0000020195 00000 п.
0000020512 00000 п.
0000020825 00000 п.
0000021276 00000 п.
0000021328 00000 п.
0000021577 00000 п.
0000021826 00000 п.
0000022102 00000 п.
0000022331 00000 п.
0000022576 00000 п.
0000022666 00000 п.
0000022842 00000 п.
0000022928 00000 п.
0000022980 00000 п.
0000023170 00000 п.
0000023412 00000 п.
0000023674 00000 п.
0000023936 00000 п.
0000024115 00000 п.
0000024282 00000 п.
0000024449 00000 п.
0000024656 00000 п.
0000024881 00000 п.
0000025195 00000 п.
0000025389 00000 п.
0000025652 00000 п.
0000025842 00000 п.
0000026131 00000 п.
0000026347 00000 п.
0000026539 00000 п.
0000026875 00000 п.
0000027140 00000 п.
0000027405 00000 п.
0000027835 00000 н.
0000028043 00000 п.
0000028361 00000 п.
0000028691 00000 п.
0000029003 00000 п.
0000029342 00000 п.
0000029664 00000 п.
0000029926 00000 н.
0000030323 00000 п.
0000030571 00000 п.
0000030875 00000 п.
0000032044 00000 п.
0000032244 00000 п.
0000032506 00000 п.
0000033057 00000 п.
0000033225 00000 п.
0000033402 00000 п.
0000033454 00000 п.
0000033665 00000 п.
0000034060 00000 п.
0000034323 00000 п.
0000034583 00000 п.
0000034932 00000 п.
0000035339 00000 п.
0000035632 00000 п.
0000036013 00000 п.
0000036335 00000 п.
0000036641 00000 п.
0000036822 00000 н.
0000037143 00000 п.
0000037399 00000 п.
0000037646 00000 п.
0000037967 00000 п.
0000038269 00000 п.
0000038593 00000 п.
0000038859 00000 п.
0000039118 00000 п.
0000039385 00000 п.
0000039650 00000 п.
0000039878 00000 н.
0000040187 00000 п.
0000040403 00000 п.
0000040679 00000 п.
0000040984 00000 п.
0000041337 00000 п.
0000041531 00000 п.
0000041840 00000 п.
0000042013 00000 н.
0000042233 00000 п.
0000042404 00000 п.
0000042784 00000 н.
0000043009 00000 п.
0000043272 00000 н.
0000043481 00000 п.
0000043752 00000 п.
0000044037 00000 п.
0000044344 00000 п.
0000044602 00000 п.
0000044829 00000 н.
0000045008 00000 п.
0000045259 00000 п.
0000045484 00000 п.
0000045754 00000 п.
0000046014 00000 п.
0000046280 00000 п.
0000046500 00000 п.
0000046522 00000 п.
0000047173 00000 п.
0000047432 00000 п.
0000047693 00000 п.
0000047954 00000 п.
0000048270 00000 п.
0000048500 00000 н.
0000048702 00000 п.
0000048863 00000 п.
0000049029 00000 н.
0000049236 00000 п.
0000049625 00000 п.
0000049858 00000 п.
0000050277 00000 п.
0000050512 00000 п.
0000050911 00000 п.
0000050963 00000 п.
0000051218 00000 п.
0000051387 00000 п.
0000051678 00000 п.
0000051967 00000 п.
0000052230 00000 п.
0000052546 00000 н.
0000052817 00000 п.
0000053122 00000 п.
0000053413 00000 п.
0000053704 00000 п.
0000053904 00000 п.
0000054162 00000 п.
0000054403 00000 п.
0000054693 00000 п.
0000054974 00000 п.
0000055180 00000 п.
0000055431 00000 п.
0000055676 00000 п.
0000055933 00000 п.
0000056184 00000 п.
0000056449 00000 п.
0000056694 00000 п.
0000056976 00000 п.
0000057188 00000 п.
0000057240 00000 п.
0000057410 00000 п.
0000057696 00000 п.
0000057876 00000 п.
0000058110 00000 п.
0000058336 00000 п.
0000058551 00000 п.
0000058803 00000 п.
0000059014 00000 п.
0000059292 00000 п.
0000059533 00000 п.
0000059776 00000 п.
0000060004 00000 п.
0000060191 00000 п.
0000060461 00000 п.
0000060691 00000 п.
0000060922 00000 п.
0000061189 00000 п.
0000061430 00000 п.
0000061647 00000 п.
0000061902 00000 п.
0000062107 00000 п.
0000062367 00000 п.
0000062623 00000 п.
0000062846 00000 п.
0000063062 00000 п.
0000063276 00000 п.
0000063526 00000 п.
0000063748 00000 п.
0000063937 00000 п.
0000064201 00000 п.
0000064413 00000 п.
0000064660 00000 п.
0000064834 00000 п.
0000065119 00000 п.
0000065305 00000 п.
0000065380 00000 п.
0000065631 00000 п.
0000065864 00000 п.
0000065928 00000 п.
0000066174 00000 п.
0000066226 00000 п.
0000066477 00000 п.
0000066764 00000 п.
0000067036 00000 п.
0000067201 00000 п.
0000067738 00000 п.
0000068725 00000 п.
0000068921 00000 п.
0000069177 00000 п.
0000069472 00000 п.
0000069759 00000 п.
0000070056 00000 п.
0000070364 00000 п.
0000070655 00000 п.
0000070894 00000 п.
0000071107 00000 п.
0000071321 00000 п.
0000071550 00000 п.
0000071749 00000 п.
0000072055 00000 п.
0000072273 00000 п.
0000072447 00000 п.
0000072761 00000 п.
0000073011 00000 п.
0000073270 00000 п.
0000073528 00000 п.
0000073791 00000 п.
0000074008 00000 п.
0000074264 00000 п.
0000074572 00000 п.
0000074938 00000 п.
0000075228 00000 п.
0000075479 00000 п.
0000075784 00000 п.
0000075956 00000 п.
0000076129 00000 п.
0000076414 00000 п.
0000076436 00000 п.
0000077049 00000 п.
0000077307 00000 п.
0000077625 00000 п.
0000077793 00000 п.
0000078019 00000 п.
0000078278 00000 п.
0000078584 00000 п.
0000078872 00000 п.
0000079162 00000 п.
0000079385 00000 п.
0000079641 00000 п.
0000079953 00000 п.
0000080178 00000 п.
0000080486 00000 п.
0000080748 00000 п.
0000080988 00000 п.
0000081250 00000 п.
0000081504 00000 п.
0000081556 00000 п.
0000081846 00000 п.
0000082141 00000 п.
0000082335 00000 п.
0000082630 00000 п.
0000082803 00000 п.
0000083061 00000 п.
0000083228 00000 п.
0000083488 00000 п.
0000083704 00000 п.
0000083953 00000 п.
0000084214 00000 п.
0000084421 00000 п.
0000084642 00000 п.
0000085239 00000 п.
0000085735 00000 п.
0000086041 00000 п.
0000086289 00000 п.
0000086560 00000 п.
0000086857 00000 п.
0000087074 00000 п.
0000087374 00000 п.
0000087628 00000 п.
0000087877 00000 п.
0000088100 00000 п.
0000088363 00000 п.
0000088587 00000 п.
0000088765 00000 п.
0000088982 00000 п.
0000089178 00000 п.
0000089439 00000 п.
0000089461 00000 п.
00000 00000 п.
00000
00000 п.
00000
00000 п.
00000
00000 п.
00000 00000 н.
00000
00000 н.
0000091931 00000 п.
0000092177 00000 п.
0000092400 00000 п.
0000092761 00000 п.
0000093047 00000 п.
0000093425 00000 п.
0000093730 00000 п.
0000094079 00000 п.
0000094364 00000 п.
0000094600 00000 п.
0000095024 00000 п.
0000095347 00000 п.
0000095623 00000 п.
0000095863 00000 п.
0000096084 00000 п.
0000096359 00000 н.
0000096411 00000 п.
0000096746 00000 п.
0000096914 00000 п.
0000097197 00000 п.
0000097521 00000 п.
0000097853 00000 п.
0000098052 00000 п.
0000098390 00000 п.
0000098626 00000 п.
0000098865 00000 п.
0000099110 00000 н.
0000099341 00000 п.
0000099636 00000 н.
0000099923 00000 н.
0000100520 00000 н.
0000101017 00000 п.
0000101358 00000 н.
0000101707 00000 н.
0000102015 00000 н.
0000102308 00000 н.
0000102549 00000 н.
0000102809 00000 н.
0000103161 00000 п.
0000103457 00000 н.
0000103695 00000 н.
0000103898 00000 п.
0000104175 00000 н.
0000104461 00000 н.
0000104754 00000 п.
0000105042 00000 н.
0000105222 00000 п.
0000105244 00000 п.
0000105811 00000 п.
0000105833 00000 п.
0000106431 00000 н.
0000106453 00000 п.
0000107024 00000 н.
0000007723 00000 н.
0000011616 00000 п.
трейлер
]
>>
startxref
0
%% EOF
251 0 объект
>
эндобдж
612 0 объект
>
поток
HUS 7 ‘$ zuPnArAr $ PD0j: & 5QbXqjgiapkҖBB- / _3 ||> =
Улучшение и автоматизация бизнес-процессов — InData Labs
4 мая 2019 г.
Предприятия среднего и крупного масштаба ежедневно используют огромное количество печатных документов .Среди них — счета-фактуры, квитанции, корпоративные документы, отчеты, пресс-релизы. И миллионы из них могут быть написаны от руки, что делает документы понятными для людей, но трудными для чтения для машин.
Базовая концепция OCR
Алгоритмы оптического распознавания символов (OCR) позволяют компьютерам автоматически анализировать напечатанные или рукописные документы и подготавливать текстовые данные в редактируемые форматы для компьютеров для их эффективной обработки. Это еще один способ извлечения и использования критически важных для бизнеса данных.По данным Международного института аналитики, компании, использующие данные, могут получить конкурентное преимущество и получить выгоды от повышения производительности на 430 миллиардов долларов к 2020 году.
Источник: https://www.techradar.com/
Как это работает
Человеческий глаз естественным образом распознает различные узоры, шрифты или стили. Для компьютеров это тяжелая работа. Любой отсканированный документ представляет собой графический файл, то есть набор пикселей. Компьютер локализует, обнаруживает и распознает символы на изображении и превращает изображение бумажных документов в текстовый файл.
Тогда становится возможным извлекать значимую информацию. Тексты в машиночитаемой форме могут затем использоваться для различных целей. Их можно сканировать в поисках шаблонов и важных данных, использовать для создания отчетов и диаграмм, распределять в электронные таблицы и т. Д.
6 шагов по созданию механизма OCR
Создание механизма OCR с нуля, подобного тем, над которыми работают специалисты InData Labs, представляет собой поэтапный процесс. Процесс разработки обычно включает 6 шагов, необходимых для обучения алгоритму эффективного решения проблем с помощью оптического распознавания символов.
1. Получение изображений
Первым шагом является получение изображений бумажных документов с помощью оптических сканеров. Таким образом можно сделать снимок и сохранить исходное изображение. Большинство бумажных документов черно-белые, и сканер OCR должен уметь распознавать пороговые значения изображений. Другими словами, он должен заменить каждый пиксель изображения черным или белым пикселем. Это метод сегментации изображения.
2. Предварительная обработка
Цель предварительной обработки — сделать необработанные данные пригодными для использования компьютерами.Уровень шума на изображении должен быть оптимизирован, а области за пределами текста удалены. Предварительная обработка особенно важна для распознавания рукописных документов, которые более чувствительны к шуму. Предварительная обработка позволяет получить чистое изображение символа, что дает лучшие результаты распознавания изображений.
3. Сегментация
Процесс сегментации направлен на группировку символов в значимые блоки. Для персонажей могут быть предопределенные классы. Таким образом, изображения можно сканировать на предмет шаблонов, соответствующих классам.
4. Извлечение признаков
Этот шаг означает разделение входных данных на набор признаков, то есть поиск основных характеристик, которые делают тот или иной образец узнаваемым. В результате каждый персонаж попадает в определенный класс.
5. Обучение нейронной сети
После того, как все признаки извлечены, они могут быть загружены в нейронную сеть (NN) для обучения ее распознаванию символов. Набор обучающих данных и методы, применяемые для достижения наилучшего результата, будут зависеть от проблемы, требующей решения на основе OCR.
6. Постобработка
Этот этап представляет собой процесс уточнения, поскольку модель OCR может потребовать некоторых исправлений. Однако добиться 100% точности распознавания невозможно. Идентификация персонажей сильно зависит от контекста. Проверка вывода требует подхода «человек в петле».
Технологии под капотом
Для работы моделей OCR используются многоуровневые искусственные нейронные сети. Для компьютерного зрения наиболее распространенными типами являются рекуррентные нейронные сети (RNN) или, точнее, долгая краткосрочная память (LSTM) и сверточные нейронные сети (CNN).
Принцип работы RNN состоит в том, чтобы сохранить выходные данные слоя и затем вернуть их в качестве входных данных. Такая архитектура позволяет легко предсказать результат слоя.
CNN — это нейронные сети прямого распространения. Информация проходит через сеть, и выходные данные модели больше не используются в качестве входных. Использование того или иного типа NN определяется решаемой проблемой.
Проблемы клиентов не всегда требуют создания механизма распознавания текста с нуля.Готовый к работе фреймворк Tesseract предоставляет отличные возможности для обучения нейронных сетей. Он предоставляет готовые к использованию модели на основе NN и позволяет инженерам с глубокими знаниями обучать настраиваемый алгоритм распознавания текста.
Для облегчения обработки изображений могут пригодиться инструменты из OpenCV. Это библиотека с открытым исходным кодом, которая предоставляет различные компьютерные алгоритмы. Еще одно решение от Google — это Vision API , который предлагает предварительно обученные модели для извлечения текста из изображений разного типа и качества.
Источник: https://cloud.google.com
Переход к эффективному управлению документами
Во всем мире компании используют OCR для сбора и обработки данных из бумажных документов. Это необходимо каждый раз, когда потребитель может использовать смартфон для проверки. Хорошим примером является использование OCR в специальных сканерах билетов на концерты или фестивали. Аналогичным образом эту технологию можно использовать для контроля доступа путем сканирования удостоверений личности и паспортов в аэропорту и на вокзалах.Будь то аренда автомобилей или парковка, использование OCR — удобный способ избавиться от ненужного бумажного документооборота.
Источник: https://www.adobe.com/
OCR может помочь в повышении уровня безопасности, когда дело доходит до проверки подлинности товаров. Его можно использовать для проверки товаров с помощью инфракрасных сканеров. Полученные данные об инфракрасных метках можно затем запустить через базу данных.