Содержание
Что такое поисковая система?
Поисковая система (или так называемый «поисковик») – это компьютерная система, созданная специально для поиска необходимой информации в интернете. Самое распространенное применение – сервисы для поиска текстового и графического контента, а также файлов на FTP-серверах, товаров в интернет-магазинах и т.д.
Чтобы найти что-то конкретное, нужно ввести поисковый запрос. Дальше система ищет документы по ключевым фразам, либо слова, как-то связанные с ключевиками. Во время этого поисковик генерирует страницу с результатами поиска. Выдача содержит не только текстовый контент, но и изображения, а также аудиофайлы.
Полезность поисковиков напрямую зависит от релевантности интернет-страниц, которые они возвращают. Яндекс и Google – самые популярные поисковики в нашей стране, и именно под их требования в основном проводится продвижение сайтов.
Типы поисковиков
- Поисковые машины.

- Каталоги интернет-ресурсов.
- Гибридные системы.
- Метасистемы (или мультипоточные системы).

Краулер (робот) обходит сеть, индекс содержит огромный архив копий интернет-страниц, а программное обеспечение сканирует результаты поиска. Многие современные поисковые системы относятся именно к этому типу.
Данные типы поисковиков получают списки интернет-страниц. Каталоги включают в себя адрес, заголовок и краткие данные об интернет-ресурсе. Каталоги ищут результаты только из описаний страниц, предоставленных веб-мастерами. Преимущество каталогов в ручной проверке сайтов, что непосредственно влияет на качество контента. В этом случае оно будет выше, чем результаты, автоматически обработанные первым типом поисковиков.
Поисковики типа Google и Yahoo сочетают 2 типа поисковиков (поисковые машины, и системы, которыми управляет человек).

Не имеют своей базы данных и поискового индекса. Формируют выдачу за счет переранжирования результатов других поисковиков. В те времена, когда поисковики были не такими умными и имели свой уникальный адрес, этот вид поисковых систем считался полезным.
структуры, функция, характеристики. Что нужно знать о поисковиках для успешного продвижения сайтов?
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и продвижение своих сайтов, понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:
Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.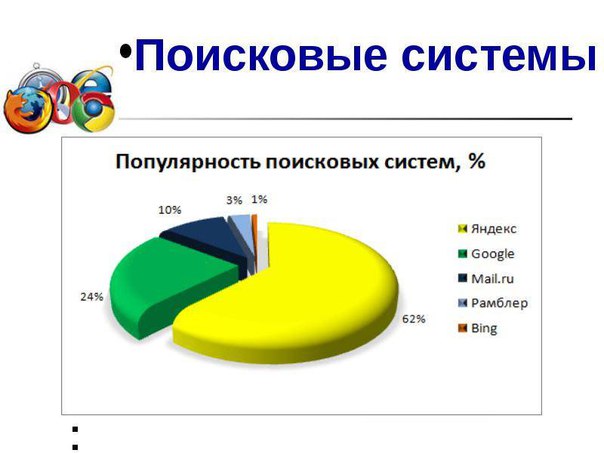
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.
В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.
В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.
Доля поисковых систем
По данным на апрель 2020 года, доли поисковых систем в мире распределены следующим образом:
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;
По данным на апрель 2020 года, доли поисковых систем в Рунете (данные сервиса Яндекс. Радар):
Радар):
- Яндекс — 59,10%
- Google — 38,85%
- Поиск.Mail.ru — 1,18%
- Rambler — 0,07%
- Остальные — 0,80%
Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
Извлекаются все ссылки из тэгов. Вместе с ними обрабатывают редиректы. Любая скачанная страница сохраняется в таком формате:
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Crawler («путешествующий» паук). Данная программа автоматически заходит на все ссылки, которые найдены на странице, а также выделяет их. Его задача – определиться, куда в дальнейшем должен заходить паук, основываясь на этих ссылках или исходя из заданного списка адресов.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) — комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т. е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
 е. информационное поле текста соответствующего данному запросу).
е. информационное поле текста соответствующего данному запросу).
Все эти элементы тесно связаны между собой и функционируют, взаимодействуя, образовывая отчетливый, но достаточно непростой механизм функционирования ПС, требующий громадных затрат ресурсов.
Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
3. Основные характеристики поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный материал призван дать ответ на вопрос о том, как работают поисковые системы. Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам Ильи Сегаловича, директора по технологиям и разработке поисковой машины «Яндекс», можно узнать лишь «под пыткой» самого Ильи Сегаловича.
Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам Ильи Сегаловича, директора по технологиям и разработке поисковой машины «Яндекс», можно узнать лишь «под пыткой» самого Ильи Сегаловича.
2. Понятие и функции поисковой системы
Поисковая система – это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто. Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5).
Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу. - Актуальность
Актуальность – не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
- Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска. Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
 Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google –самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш материал позволит вам поближе познакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.
Информационно-поисковые системы Internet | Открытые системы. СУБД
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. — без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х — начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник «Научно-техническая информация. Серия 2», который выходит до сих пор. На русском языке издана так же и «библия» по разработке ИПС — «Динамические библиотечно-информационные системы» Ж. Солтона [1], в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом, нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения появилось нечто принципиально новое, чего не было раньше. Если быть точным, то ИПС в Internet — это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web еще не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала «Communication of the ACM» [2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли [3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена отнюдь не чудесным программам талантливых одиночек, а средствам, являющимся результатом планового и последовательного движения научных и производственных коллективов к поставленной цели. Рано или поздно этап исследований заканчивается, и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital [4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Архитектура современных ИПС для WWW
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы [6] (рис.).
Рис. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме — это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) — это не просто программа просмотра, в случае информационно-поисковой системы под этим словосочетанием понимают также способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотров результатов поиска.
Search engine (поисковая машина) — служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) — индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) — сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) — служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites — это весь Internet или точнее — информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Информационные ресурсы и их представление в ИПС
Как видно из рисунка, документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet и статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных: тексты, графическая и аудиоинформация и вообще все, что имеется в указанных хранилищах. Естественно возникает вопрос — как информационно-поисковая система должна со всем этим работать?
В традиционных системах используется понятие поискового образа документа — ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель [7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются — элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet [4,6,7].
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах [7]. Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах [4,6]. Таким образом, первая задача, которую должна решить ИПС, — это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики [8]. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (h2,h3), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах [9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords. Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина [10]. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Индекс поиска
После того как ресурсы заиндексированы и система составила массив ПОД, начинается построение поискового аппарата. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД займет много времени, что абсолютно не приемлемо для интерактивной системы WWW. Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы [6], для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Page-ID отображает идентификаторы страниц в их URL, Keyword-ID — каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков — идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок — идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор страницы, позиция слова в странице. Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу» с помощью таблицы модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Информационно-поисковый язык системы
Индекс — это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, — именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: «Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно«.
Возможны и варианты. Так, в большинстве систем фраза «Unix Platform» будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. Различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню — ориентированный подход, либо командную строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя — в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска — список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Итак, результат поиска в базе данных ИПС — это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых выдается только список ссылок, а в таких, как Lycos, Alta Vista и Yahoo, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности [7]. Релевантность — это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая — это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле [6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система их не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS — это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы, при которой одна ИПС, например Lycos, строит поисковый аппарат над поисковым аппаратом другой системы — WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, разбив их на поля, и хранить документы в виде одного файла. Индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения, программа просмотра ресурсов Internet в этом случае должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
Заключение
В обзорной статье были рассмотрены основные элементы информационно-поисковых систем и принципы их построения. Сегодня ИПС являются наиболее мощным механизмом поиска сетевых информационных ресурсов Internet. К сожалению, в российском секторе Internet пока не наблюдается активного изучения этой проблемы за исключением, может быть, проекта LIBWEB, финансируемого РФФИ и системы «Паук», которая работает недостаточно надежно. Наибольшим опытом разработки такого сорта систем безусловно обладает ВИНИТИ, но здесь работа сосредоточена пока на размещении своих собственных ресурсов в Сети, что принципиально отличается от информационно-поисковых систем Internet типа Lycos, OpenText, Alta Vista, Yahoo, InfoSeek и т.п. Казалось бы, что такая работа могла быть сосредоточена в рамках таких проектов, как Россия On-line компании SovamTeleport, но здесь мы пока наблюдаются ссылки на чужие поисковые машины. Развитие ИПС для Internet в США началось два года назад, учитывая отечественные реалии и темпы развития технологий Сети в России, можно надеяться, что у нас еще все впереди.
Литература
1. Дж. Солтон. Динамические библиотечно-информационные системы. Мир, Москва, 1979.
2. Frank G. Halasz. Reflection notecards: seven issues for the next generation of hypermedia systems. Communication of the acm, V31, N7, 1988, p.836-852.
3. Tim Berners-Lee. World Wide Web: Proposal for HyperText Project. 1990.
4. Alta Vista. Digital Equipment Corporation, 1996.
5. Brain Pinkerton. Finding What People Want: Experiences with the WebCrawler.
6. Bodi Yuwono, Savio L.Lam, Jerry H.Ying, Dik L.Lee. A World Wide Web Resource Discovery System.
7. Martin Bartschi. An Overview of Information Retrieval Subjects. IEEE Computer, N5, 1985,p.67-84.
8. Michel L. Mauldin, John R.R. Leavitt. Web Agent Related Research at the Center for Machine Translation.
9. Ian R.Winship. World Wide Web searching tools -an evaluation. VINE (99).
10. G.Salton, C.Buckley. Term-Weighting Approachs in Automatic Text Retrieval. Information Processing & Management, 24(5), pp. 513-523, 1988.
11. Open Text Corporation Releases Industry»s Highest Performance Text Retrieval System.
Павел Храмцов ([email protected]) — независимый эксперт, (Москва).
Поделитесь материалом с коллегами и друзьями
Что понимают под поисковой системой
Каждый момент времени человек принимает решения. Результат: движение вперед, суета на месте или перемещение в информационном пространстве, но куда? Что понимают под поисковой системой?
Хорошее зрение, слух, надежная работа всех органов чувств и объективное восприятие действительности во многом определяют правильное применение накопленного опыта и знаний, дают шанс интуиции проявить себя. Но правильный ответ — результат не только правильного вопроса, но и корректно собранной информации для его решения (это область критерия).
Что понимают под поисковой системой кратко? История интернет-поиска
Во времена, когда компьютеры и Интернет были уделом избранных, логика обычного библиотечного дела считалась востребованной. Зачем усложнять решение задачи, когда для ориентации в информационном пространстве достаточно каталога файлов, данных, решений, программ и всего, что было сделано и может пригодиться?
Не стоит ли пользователям поставить памятник? Вспомнить, что именно труду фанатов компьютерного дела обязаны сети, каталоги, возможности для общения и «первичного» накопления:
- информационного капитала;
- основ современных представлений (они канули в лету, но их мимолетное явление образовало долгосрочную перспективу).
Мощь и возможности компьютеров быстро ушли из вычислительной сферы в сферу обработки информации. Интернет стал стремительно завоевывать новые территории в областях применения и умах людей. Простое библиотечное дело моментом мигрировало в изощренные механизмы поисковых машин.
Многочисленные армии искателей, роботов, «пауков» и прочих алгоритмов принялись скрупулезно исследовать все, что попадало в интернет-пространство. Возможно, именно они дали понять, что такое поисковая система, как работает поиск, что такое Интернет. Они учились индексировать информацию, приходили к пониманию того, что можно и как нужно использовать.
Это был древний «доинформационный мир», допотопное вооружение, примитивные методики собирательства — совсем как рыбалка и охота во времена, когда люди только начали представлять собой что-то общественное, социально значимое, отделившееся от природы по критерию разумности.
Индексация: мы не рабы, но у нас еще ничего нет
Индексация информационного пространства, методика ориентации в собранной информации и умение правильно корректировать имеющееся за счет обнаруженных изменений во внешней (Интернет) среде становились основой для выживания. Так принято в живой природе, а интернет-пространство уже обретало свою собственную и абсолютно реальную жизнь.
В истории всегда было что-то, что можно вспомнить, но всегда возникает вопрос, а так ли это было, связано ли то историческое «бытие» с реальными людьми и памятными воспоминаниями?
Возможно, сосед по лестничной клетке оказался создателем Google или сформулировал фундаментальные основы процветания Yandex. Но многие упоминают 1945 год как точку, с которой началась идея гипертекста, а «Волшебный автоматический извлекатель текста Сэлтона» считается отцом современной поисковой технологии.
С тех пор утекло много воды, а список первых поисковиков, первых античных алгоритмов и идей так велик, что сам по себе является хорошей поисковой задачей для систематизации и индексации прошлого.
Небеспочвенно утверждать, что причина явления Google как феномена и современной системы — это не только реальный человек, его друзья и подруги. Почему это не совершенно иная точка информационного пространства, которая удачно вызвала нужный резонанс или ассоциацию?
Совокупное общественное сознание — еще та темная вселенная, в которой до своего варианта лампочки Эдисона очень даже далеко.
Год 1994: какой бот сказал ключевое слово «мама»?
В современном мире с трудом верится в прошлое, но сделав скидку на точность дат и участие реальных личностей, следует отметить, что появление ключевых слов — это еще не семантическое ядро.
Что понимали под поисковой системой в конце прошлого века, уже было абсолютно ясно: это десяток популярных поисковиков с конкурирующим рейтингом в борьбе за клиента. Одним нравился Yahoo, другим Aport, третьим Rambler, но в конечном счете остались Google и Yandex.
Все это слова, мнения, предпочтения и интересные факты. Однако монстры поискового дела образовались, создали фундаментальные основы, заложили объективное знание и солидный опыт в понимание:
- механизмов поиска;
- ключевые слова;
- семантическое ядро.
Гипертекст не только оперился, но и стал основой интернет-программирования, проложил дорогу смежным серьезным технологиям.
Главное: не суть, как мы понимаем и что происходит. Важно, что направление движения есть, и оно правильное. Колебания курса — это нормально, не будь колебаний, не было бы повода оптимизировать критерии. А критерии и в вопросе, и в ответе — самое главное.
Год 1989: возрождение, о котором забыли
Откат — это особый исторический механизм и всегда интересный факт. Людям, особенно ученым и квалифицированным специалистам, свойственно забывать о сути вещей и уходить в мечтания. Мир войн, гладиаторов и страшных сражений — забава по сравнению с тем, какие состязания идут в общественном и частном сознании. Здесь царство мрака, но идти вперед нужно, и без победы на каждом шагу никак нельзя.
Принцип работы поисковой системы лег в основу алгоритма. Реальных реализаций алгоритмов исполнено множество. Выжило очень мало, но именно это поделило между собой все интернет-сообщество. Борьба за идеалы в сфере поиска уже тогда имела значение, но даже краткая история развития поисковых систем перестала интересовать потребителя.
Пользователю нужен ответ, а не достижения ученых и специалистов. Потребитель желает знать, как правильно сформулировать вопрос, чтобы получить адекватный ответ и быть уверенным, что поисковый механизм отработал правильно, применил объективные критерии.
Кого волнует интересный факт, что ООП и облака были придуманы в 1989-1991 гг. Абсолютно никого! Но всего десяток лет назад пошел откат: теперь без ООП и облачных технологий нельзя. Но откат «не покатил» в нужном направлении, поэтому на вопрос о том, что понимают под поисковой системой, нет конкретного ответа. Ничего нового не появилось, а вот лишнее — да.
Определение поиска и поисковой системы
Когда появились калькуляторы, человек подумал, что забудет правила сложения, умножения, деления. Прошло время, и страх развеялся. Калькуляторы живы, и столбиком вершить простейшие математические действия человек не разучился.
Во времена, когда функционирует «Гугл» и «Яндекс», а вокруг небольшое число авторитетных поисковых систем, сложилось мнение: поиск — это компьютерный алгоритм, а поисковая система (определение слова и его значение) — это программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в Интернете.
Квалифицированные и авторитетные специалисты выделяют такие понятия, как поисковый движок, поисковый алгоритм и коммерческая тайна компании владельца (разработчика).
Выдача поисковой системы
Что понимают под поисковой системой, несложно представить. Есть строка запроса, посетитель пишет ключевое слово, нажимает кнопку «искать» и получает результат. Но поисковая выдача — это не ответ, а ключевое слово — это не вопрос.
В обычной жизни человек не пользуется ключевыми словами и никогда не получает никакой «выдачи». Если ребенок хочет кушать, он скажет об этом маме или папе. Все зависит от того, что именно малыш хочет: реально поесть или получить деньги на мороженое. Реакция родителя может быть лишена слов, но действие последует.
Работник не будет обращаться к нанимателю через ключевые слова, иначе результатом выдачи будет бессловесное увольнение.
Все это факты, но человек и компьютерная система — это другая сфера отношений. Пока есть четкое представление, что понимают под поисковой системой — это не вопросы, ответы, критерии, а ключевые слова и результаты работы движка (поисковая выдача).
Реальная польза текущего момента
Страсти по SEO, стремительный рост числа веб-студий, развитие рекламного дела, навязывание идей, тонны спама и мусор в выдаче — все это естественно и объективно нормально. Бороться со спамом, хакерами и негативом пора. Нужно это делать внимательно, но реальная польза от сложившейся ситуации — всего лишь очередной этап развития поискового дела.
Ключевые слова — отлично. Семантическое ядро сайта — прекрасно. Компьютер может переводить тексты на разные языки и разбирать естественные предложения. Язык SQL стал де-факто в «общении» с базами данных. У SQL — масса диалектов, а это реальный показатель. Искусственный язык стал жизнеспособен! Язык способен дать доступ к огромным объемам систематизированной информации.
Oracle и другие лидеры в сфере больших баз данных потратили десятки лет на представление информации. Google — на сбор информации и механизмы индексации. Семейство Linux удержало позиции, Windows осталась на плаву, а численность языков программирования сузилась до достаточного уровня.
Искусственный интеллект ушел в мир грез, разработчики и потребители объективно устремились в мир созидательного управления информацией и ее использования.
Поисковая выдача: важное и бесполезное
Не так сложно систематизировать поисковую выдачу, но за последние десять лет она не изменилась. По сути — верно. Если в строке поиска ключевое слово, а не вопрос, то о каком ответе может идти речь? Критерии во всех современных поисковых системах есть, к ним относятся с надлежащим пониманием, но зачем ограничивать потребителя?
Важна реакция пользователя на то, какую именно часть поисковой выдачи он выбирает. Это его мнение о результатах работы поисковой системы. Поисковики ценят это и учитывают не только в частном запросе, но и в целом.
Поток ключевых слов и поток выдачи — и то, и другое содержит информационный мусор. Это тоже повод для формирования критериев. Нельзя рассматривать задачу поиска как применение ключевого слова и алгоритма к накопленной информации, как уточнение накопленной информации.
О перспективах: от поиска к решению
Лучшее решение — не принимать никаких решений. Понимают это или нет разработчики поисковых механизмов, но факт остается фактом: что такое поисковая система, разработчики знают в контексте реакции на ключевое слово, как индекс в условиях выборки информации из уже доступных и систематизированных данных.
Потребитель сам выберет из поисковой выдачи, что сочтет нужным, и примет решение. Поисковая система учтет и запомнит это. Как человек распорядится полученной информацией — это будет следующее ключевое слово.
Так поисковая система учится принимать решения, а человек — формулировать вопросы. Пока это ключевые слова, а результат ответа — поисковая выдача. Но количество всегда переходит в качество.
Что такое поисковые системы Интернета? Реальность, основанная на поступательном движении вперед. Не так много практических задач требуют разума от компьютерных систем. В большинстве случаев вполне достаточно, чтобы они просто адекватно отвечали на правильно поставленные вопросы.
Что такое SEO продвижение сайта
Преимущества и недостатки SEO продвижения сайтов
Поисковая оптимизация сайта дает трафик на сайт из поисковиков. Такой трафик называют поисковым или органическим. Этот канал трафика, как и любой другой, обладает рядом преимуществ и недостатков. Рассмотрим наиболее важные:
Плюсы:
Не нужно платить за переходы. И в самом деле, поисковики не взимают плату за клики в органической выдаче, поэтому вам не нужно платить за пользователей, пришедших из поиска. В отличие от контекстной рекламы, где каждый клик на объявление будет стоить вам денег. Но не все так просто. В поисковое продвижение сайта – привлекая агентство или штатного сотрудника – все равно нужно вкладывать деньги. Понимая, что получаемый трафик из органического поиска в разы дешевле трафика из контекстной рекламы. Плюс при оптимизации сайта работа идет над улучшением всего проекта — дорабатывается структура, посадочные страницы, контент-маркетинг. И заказчик получает и целевой трафик, и улучшение сайта, в отличие от других видов рекламы.
Горячий трафик. Пользователи сами ищут товар или услугу и для этого вбивают запросы в поиске. Важно, что они ищут это в режиме реального времени. Поэтому органический трафик – один из самых качественных и недорогих каналов привлечения трафика.
Гибкий выбор запросов. Вы самостоятельно определяете список запросов, который хотите продвигать в поиске. При этом можно работать с довольно широким списком запросов, обрабатывая спрос на каждом этапе воронки привлечения клиентов – построение знания о бренде, охват «горячего» спроса, принятие решения о покупке, работа с существующей клиентской базой. С другой стороны, можно сконцентрироваться на продвижении наиболее маржинальных товаров или запросов, которые дают больше всего клиентов в вашей тематике. Такие запросы можно посмотреть в веб-мастере Яндекса.
Улучшается техническое состояние сайта. Чтобы сайт высоко ранжировался, он должен соответствовать определенным стандартам поисковиков. Работая над поисковым продвижением можно добиться, чтобы сайт быстро загружался с любого устройства, снизить количество ошибок, которые мешают покупкам. Немного позже поговорим о факторах seo продвижения сайта.
Улучшается юзабилити сайта. Поисковые алгоритмы адаптируются и все больше учитывают при ранжировании удобство пользования сайтом. Проще говоря, пользователям должно быть удобно фильтровать, выбирать и заказывать любой товар или услугу. Поисковики это высоко ценят.
Минусы:
Результат проявляется не сразу. После оптимизации сайта поисковикам нужно время, чтобы его проиндексировать. Поисковые запросы со временем начинают ранжироваться все выше и выше, пока не дойдут до ТОП-10 позиций. Этот временной интервал всегда разный – в среднем от 2 до 6 месяцев.
Расходы на доработку сайта. Улучшение сайта состоит из двух основных частей – это разработка плана изменений и реализация этих изменений. Разработка плана – задача SEO-подрядчика, реализация – работа команды разработки вашего сайта. И то и другое требует ресурсов – временных и финансовых. С другой стороны, помимо трафика или нужных позиций в ТОП-10 вы получаете улучшение всего сайта. Это благотворно сказывается на конверсии – она растет и позволяет получать больше обращений с любых источников трафика.
Ограниченная актуальность поиска. Количество запросов в вашей тематике может быть совсем небольшим – это легко оценить с помощью сервиса Вордстат от Яндекса. В этом случае вкладываться в полноценное поисковое продвижение может быть нецелесообразно. Гораздо правильнее привести сайт в порядок и поддерживать его.
Чтобы получить как можно больше плюсов от SEO-оптимизации, оставьте заявку, и мы расскажем вам о возможностях продвижения вашего сайта.
SEO-продвижение сайта в ТОП-10 поисковых систем в Москве и по всей России
Поисковое продвижение сайта по позициям – это такая форма сотрудничества, при которой
SEO-специалист
гарантирует выведение сайта на первые позиции поисковой выдачи по определенному небольшому
набору ключевых запросов.
Продвижение сайта в Топ-10 предоставляет компании конкурентное преимущество, так как чем
выше сайт в выдаче, тем больше вероятность выбора продуктов/услуг этой компании.
Ведь по статистике, основная часть пользователей не доходит и до конца первой страницы.
В таком методе продвижения при сборе семантического ядра используются в основном
высокочастотные
запросы. Обычно они состоят из 2-3 слов, не описывают четко желание пользователя и являются
очень
конкурентными. Например, запрос «гусеничный экскаватор» не дает нам понятия что хочет
пользователь:
купить его, арендовать, отремонтировать или же просто узнать какую-либо информацию о нем.
Каждая страница всегда продвигается по ограниченному списку конкретных фраз. Оплата обычно
происходит
за каждый выведенный в топ запрос.
В чем отличие от продвижения по трафику?
Продвижение сайта по трафику происходит за счет большого количества низко- и
среднечастотных фраз. Такие запросы более конкретные и низкоконкурентные — занять Топ по ним
легче. Можно сказать, что такой способ продвижения более надежный, так как обеспечивает
поток трафика на сайт, даже без высокочастотных фраз.
Каким сайтам подходит продвижение по позициям?
Такой способ подойдет если у вас:
Узкотематический сайт с небольшой аудиторией
Это сайты, посвященные специфическим, не высокочастотным темам. Обычно они имеют
ограниченный набор ключевых запросов, и имеет смысл сделать упор именно на них.
Например, услуги испытания свай и грунтов.Имиджевый сайт
Это сайты созданные с целью улучшения узнаваемости бренда, на них кратко и доступно
изложена информация о нем. По-другому они еще называются «сайт-визитка» или
«промо-сайт». Обычно он отличается небольшим количеством страниц, следовательно и
запросов, поэтому продвижение в топ по бренду отлично подойдет для имиджевого сайта.Небольшой бюджет
Поисковое продвижение сайта в Топ не по всем, а только по нескольким направлениям
обойдется дешевле, и поэтому может подойти компаниям, располагающим небольшим бюджетом
на SEO.
Как проходит продвижение сайта в Топ
Проведение аудита
SEO-аудит выявит технические и контентные недостатки сайта и даст понятие как строить
дальнейшую стратегию продвижения сайта в Топ поисковых систем. Мы указываем по каким
пунктам необходимы
доработки и зачем, пишем рекомендации, а также рассчитываем предварительную
стоимость услуг.
Вы можете заказать SEO-аудит бесплатно.Составление стратегии
После проведения аудита и изучения бизнеса и ниши составляется стратегия
SEO-продвижения
и контент план.Техническая SEO-оптимизация
В случае если при аудите были найдены проблемы по технической оптимизации или нужно
продвижение нового сайта, то
понадобятся работы по базовому SEO. В него входит:- Настройка индексации;
- Настройка файлов robots.txt и sitemap.xml;
- Оптимизация скорости страниц;
- Настройка 404-страницы, устранение битых ссылок;
- Настройка главного зеркала;
- Перевод на https-протокол;
- Проверка мобильной версии сайта;
- И другое.
Внутренняя оптимизация
Это оптимизация контента страниц. Без качественных и уникальных текстов продвижение
сайта в Топ
будет крайне затруднительно. Поисковые системы все больше понимают где действительно
полезный для
пользователей контент, а где написанный для роботов.Что входит во внутреннюю оптимизацию:
Сбор семантического ядра.
В случае с
продвижением сайта по позициям обычно подразумевается сбор высокочастотных
поисковых фраз. Однако эффективнее всего будет использование всех видов
запросов.Составление ТЗ на тексты.
На основе семантики и
анализа конкурентов составляется ТЗ на написание текстов, где указаны нужные
ключевые слова, структура и примерное содержание будущего текста. Такой подход
позволяет создавать максимально качественный контент.Написание текстов.
О том как правильно писать SEO-тексты мы
подробно написали в нашей статье.Составление метаданных.
После создания новых
страниц или наполнение контентом старых необходимо правильно
заполнить заголовок и описание страницы, разместить заголовки h2-h6. Это все
также является факторами
ранжирования. Добавление даже одного слова в заголовок уже может сильно повлиять
на SEO-продвижение сайта в Топ.
Внешняя оптимизация
Внешняя SEO-оптимизация — это наращивание внешней ссылочной массы, а также проверка
качества ссылочного профиля.Ссылки — один из главнейших факторов ранжирования в ПС, так как они влияют на
авторитетность сайта, причем как в лучшую, так и в худшую сторону. Поэтому
необходимо тщательно проверять площадки-доноры и грамотно составлять анкор-лист.Аналитика
SEO без аналитики — не SEO. Чтобы знать работает ли стратегия, как ее скорректировать
нужна постоянная аналитика данных:- Источники и каналы трафика;
- Конверсия;
- CTR;
- Поведенческие факторы;
- Позиции;
- Поисковые запросы;
- И многое другое.
О самых важных показателях мы пишем в ежемесячном отчете по SEO-продвижению.
Стоимость продвижения в Топ
Цена продвижения сайта в Топ складывается из различных факторов:
- Регион. От региона зависит конкуренция, а значит и сложность продвижения.
Например, цена продвижения сайта в Топ по Москве выйдет дороже, чем в Тюмени или Самаре
или будет равна цене продвижения по нескольким небольшим городам. - Тематика бизнеса. От тематики зависит время, затраченное специалистом на ее
изучение и составление стратегии продвижения, а также уровень конкуренции в нише. - Объем контента. Предварительный объем необходимых текстов и посадочных страниц
будет известен из нашего аудита. - Текущий уровень технической оптимизации. От этого зависит список работ по
базовому SEO.
Чтобы узнать сколько стоит продвижение вашего сайт в Топ заполните заявку на бесплатный
SEO-аудит.
Обычно цена продвижения в нашем агентстве начинается от 45 000 руб.
Для большего эффекта мы рекомендуем не ограничиваться только SEO-продвижением, а продумать
стратегию комплексного интернет-маркетинга: провести глубокую аналитику бизнеса и целевой
аудитории, подобрать наиболее эффективные инструменты привлечения трафика, а также
убедиться, что сайт способен конвертировать его в заявки и звонки.
Что такое поисковая машина?
Поисковая машина — это веб-инструмент, который позволяет пользователям находить информацию во всемирной паутине. Популярными примерами поисковых систем являются Google, Yahoo !, и MSN Search. Поисковые системы используют автоматизированные программные приложения (называемые роботами, ботами или пауками), которые перемещаются по сети, переходя по ссылкам со страницы на страницу, с сайта на сайт. Информация, собранная пауками, используется для создания поискового индекса в Интернете.
Как работают поисковые системы?
Каждая поисковая система использует различные сложные математические формулы для создания результатов поиска.Затем результаты по конкретному запросу отображаются в поисковой выдаче. Алгоритмы поисковой системы берут ключевые элементы веб-страницы, включая заголовок страницы, контент и плотность ключевых слов, и составляют рейтинг того, где разместить результаты на страницах. Алгоритм каждой поисковой системы уникален, поэтому первое место в рейтинге Yahoo! не гарантирует высокий рейтинг в Google, и наоборот. Чтобы усложнить ситуацию, алгоритмы, используемые поисковыми системами, не только строго охраняются в секрете, они также постоянно подвергаются модификации и пересмотру.Это означает, что критерии наилучшей оптимизации сайта следует предполагать путем наблюдения, а также методом проб и ошибок — и не один раз, а постоянно.
Уловки, которые рекламируются менее авторитетными SEO-фирмами, поскольку ответ на повышение рейтинга сайта может сработать в лучшем случае только в течение короткого периода, прежде чем разработчики поисковой системы осознают эту тактику и изменят свой алгоритм. Более вероятно, что сайты, использующие эти уловки, будут отмечены поисковыми системами как спам, и их рейтинг резко упадет.
Поисковые системы только «видят» текст на веб-страницах и используют базовую структуру HTML для определения релевантности. Большие фотографии или динамическая Flash-анимация ничего не значат для поисковых систем, в отличие от фактического текста на ваших страницах. Трудно создать сайт на Flash, который был бы так же удобен поисковым системам; в результате сайты Flash будут иметь тенденцию не иметь такого высокого рейтинга, как сайты, разработанные с использованием хорошо закодированного HTML и CSS (каскадные таблицы стилей — сложный механизм для добавления стилей к страницам веб-сайтов помимо обычного HTML).Если термины, по которым вы хотите, чтобы вас находили, не появляются в тексте вашего веб-сайта, вашему веб-сайту будет очень сложно занять высокое место в поисковой выдаче.
Что такое поисковая машина?
Обновлено: 02.06.2020 компанией Computer Hope
Поисковая машина — это программное обеспечение, доступное в Интернете, которое выполняет поиск в базе данных информации в соответствии с запросом пользователя. Механизм предоставляет список результатов, которые лучше всего соответствуют тому, что пытается найти пользователь. Сегодня в Интернете доступно множество различных поисковых систем, каждая со своими возможностями и особенностями.Первой разработанной поисковой системой считается Archie, которая использовалась для поиска файлов FTP, а первой поисковой системой на основе текста считается Veronica. В настоящее время самой популярной и известной поисковой системой является Google. Другие популярные поисковые системы включают AOL, Ask.com, Baidu, Bing, DuckDuckGo и Yahoo.
Как получить доступ к поисковой системе
Для пользователей доступ к поисковой системе осуществляется через браузер на их компьютере, смартфоне, планшете или другом устройстве. Сегодня большинство новых браузеров используют омнибокс, который представляет собой текстовое поле в верхней части браузера.Омнибокс позволяет пользователям вводить URL-адрес или поисковый запрос. Вы также можете посетить домашнюю страницу одной из основных поисковых систем, чтобы выполнить поиск.
Как работает поисковая система
Поскольку большие поисковые системы содержат миллионы, а иногда и миллиарды страниц, многие поисковые системы отображают результаты в зависимости от их важности. Эта важность обычно определяется с помощью различных алгоритмов.
Как показано, источник всех данных поисковой системы собирается с помощью паука или краулера, который посещает каждую страницу в Интернете и собирает ее информацию.
После сканирования страницы данные, содержащиеся на странице, обрабатываются и индексируются. Часто это может включать следующие шаги.
- Убрать стоп-слова.
- Запишите оставшиеся слова на странице и частоту их появления.
- Запись ссылок на другие страницы.
- Запишите информацию обо всех изображениях, аудио и встроенных медиафайлах на странице.
Собранные данные используются для ранжирования каждой страницы. Эти рейтинги затем определяют, какие страницы показывать в результатах поиска и в каком порядке.
Наконец, после обработки данные разбиваются на файлы, вставляются в базу данных или загружаются в память, откуда к ним обращаются при выполнении поиска.
Все ли поисковые системы дают одинаковые результаты?
Не обязательно. Поисковые системы используют собственные алгоритмы для индексации и сопоставления данных, поэтому у каждой поисковой системы есть свой подход к поиску того, что вы пытаетесь найти. Его результаты могут зависеть от того, где вы находитесь, что еще искали, и какие результаты предпочитали другие пользователи, которые ищут то же самое.Каждая поисковая система оценивает их по-своему и предлагает разные результаты.
Какая поисковая система самая лучшая?
Нет ни одной поисковой системы лучше всех остальных. Многие люди могут возразить, что поисковая система Google — лучшая, самая популярная и известная. Он настолько популярен, что люди часто используют его как глагол, когда говорят кому-то искать свой вопрос.
Поисковая машина Microsoft Bing также популярна и используется многими людьми. Bing отлично справляется с поиском информации и ответами на вопросы.Bing также поддерживает поиск в Windows 10 и поисковой системе Yahoo.
Пользователи, озабоченные конфиденциальностью, пользуются Duck Duck Go. Эта поисковая система делает своих пользователей анонимными и является отличным решением для пользователей, обеспокоенных тем, сколько информации Google и Bing собирают о своих пользователях.
Bing, Google, Индекс, Интернет, Интернет-термины, Metacrawler, PageRank, Поиск, SEO, SERP, Стоп-слова, Вероника, WAIS, Интернет, YaCy, Yahoo
Что такое поисковые системы и как они работают?
Что такое поисковая машина?
Поисковая система — это онлайн-инструмент, предназначенный для поиска веб-сайтов в Интернете на основе поискового запроса пользователя.
Он ищет результаты в своей собственной базе данных, сортирует их и составляет упорядоченный список этих результатов, используя уникальные алгоритмы поиска. Этот список называется страницей результатов поисковой системы (SERP).
Хотя в мире существуют различные поисковые системы (например, Google, Bing, Yahoo и т. Д.), Общие принципы поиска и предоставления ответов во всех них одинаковы.
Истоки поисковых систем
- Первой поисковой машиной в Интернете была Archie Query Form , представленная в 1990 году — это был простой инструмент, который искал FTP-сайты и предоставлял их в виде списка.Никакого дополнительного содержания он не включал.
- Предшественник Google — BackRub был представлен в 1996 году. Эта поисковая система принесла основной принцип обратных ссылок и заложила основу для алгоритма PageRank, который используется по сей день.
- Google был запущен в 1998 году как преемник BackRub и с годами стал самой популярной и доминирующей поисковой системой в мире.
Как работают поисковые системы
Поисковые системы могут отличаться друг от друга способами предоставления ответов пользователю, но все они построены на трех фундаментальных принципах:
- Ползание
- Индексирование
- Рейтинг
1.Ползание
Фактическое обнаружение новых веб-страниц в Интернете начинается с процесса, называемого сканированием.
Поисковые системы используют небольшие программы, называемые веб-сканерами (иногда называемыми ботами или роботами-пауками), которые переходят по ссылкам с уже известных страниц на новые, которые необходимо обнаружить.
Каждый раз, когда поисковый робот находит новую веб-страницу по ссылке, он сканирует и передает ее содержимое для дальнейшей обработки (называемой индексированием) и продолжает обнаружение новых веб-страниц.
2. Индексирование
После того, как боты просканируют данные, наступит время для индексации — процесса проверки и сохранения содержания веб-страниц в базе данных поисковой системы, называемой «индексом». По сути, это большая библиотека всех веб-сайтов.
Ваш веб-сайт должен быть проиндексирован для отображения на странице результатов поисковой системы. Имейте в виду, что сканирование и индексирование — это непрерывные процессы, которые повторяются снова и снова, чтобы поддерживать базу данных в актуальном состоянии.
После того, как веб-страница проанализирована и сохранена в индексе, ее можно использовать в качестве результата поиска для потенциального поискового запроса.
3. Рейтинг
Последний шаг включает выбор лучших результатов и создание списка страниц, которые будут отображаться на странице результатов.
Каждая поисковая система использует десятки сигналов ранжирования, и большинство из них хранятся в секрете и недоступны для публики.
Как сказал Мартин Сплитт, аналитик трендов для веб-мастеров:
«У нас есть более 200 сигналов.Поэтому мы смотрим на такие вещи, как заголовок, мета-описание, фактический контент, который у вас есть на своей странице, изображения, ссылки и многое другое «. (Мартин Сплитт, аналитик трендов для веб-мастеров)
Что такое алгоритм поисковой системы?
Алгоритм поисковой системы — это термин, используемый для определения сложной системы из нескольких алгоритмов, которая оценивает все проиндексированные страницы и определяет, какие из них должны появиться в результатах поиска по заданному запросу.
Например, алгоритм Google использует десятки факторов (многие из них хорошо известны, а некоторые держатся в секрете) в нескольких областях, таких как:
- Значение запроса (понимание того, что пользователь имеет в виду, используя точные слова, которые он использовал, каково намерение поиска и т. Д.)
- Релевантность страницы (поисковой системе необходимо выяснить, отвечает ли страница поисковому запросу)
- Качество контента (алгоритмы определяют, являются ли веб-страницы отличным источником информации на основе внутренних и внешних факторов; здесь важными факторами являются количество и качество обратных ссылок)
- Удобство использования страницы (рассматривает качество веб-страницы с технической точки зрения — скорость отклика, скорость страницы, безопасность и т. Д.)
Поисковая оптимизация
Помимо предоставления полезной информации для пользователей, поисковые системы также могут помочь брендам продвигать свои веб-сайты.
Оптимизация вашего веб-сайта по релевантным поисковым запросам — важная часть любой маркетинговой стратегии в Интернете, поскольку она может привлечь больше трафика на ваши веб-страницы.
Совокупность всех практик и приемов, которые владельцы веб-сайтов используют для улучшения своего поискового рейтинга, называется поисковой оптимизацией (SEO).
Если бы мы хотели упростить поисковую оптимизацию, мы могли бы сказать, что все это вращается вокруг трех наиболее важных факторов:
- Техническая оптимизация
- Отличное содержание
- Качественные обратные ссылки
Какие поисковые системы самые популярные?
Хотя в мире существуют сотни поисковых систем, лишь некоторые из них доминируют на общем рынке поисковых систем и остаются популярными благодаря своему качеству, полезности и т. Д.
С точки зрения мировой популярности Google уже много лет занимает первое место.Это список топ-5 самых популярных поисковых систем:
1. Google
Google — самая большая и популярная поисковая система в мире.
Принадлежащая своей материнской компании Alphabet, Google доминирует на рынке поисковых систем, занимая более 90 процентов мирового рынка.
Благодаря всем своим функциям, включая сложные алгоритмы, эффективное сканирование, индексирование и ранжирование, Google обеспечивает отличные результаты поиска не только в своей собственной поисковой системе, но и в некоторых других поисковых системах (например.грамм. ask.com).
2. Microsoft Bing
Bing — вторая по величине поисковая система. Он был запущен в 2009 году и принадлежит Microsoft.
Несмотря на то, что невозможно сравнить Bing как реального оппонента Google, занимающего лишь 2–3 процента от общей доли рынка поисковых систем, он по-прежнему является отличной альтернативой для тех, кто хотел бы попробовать что-то другое.
Microsoft Bing во многом похож на Google, предоставляя такие типы результатов поиска, как изображения, видео, места, карты или новости.
Хотя Bing использует фундаментальные принципы поисковых систем (сканирование, индексирование, ранжирование), он также использует специальный алгоритм, называемый Space Partition Tree And Graph, который основан на векторах для категоризации информации и для ответов на поисковые запросы.
3. Yahoo!
Yahoo — популярный веб-сайт, поставщик услуг электронной почты и третья по величине поисковая система в мире, на долю которой приходится почти 2% общей доли рынка поисковых систем.
Некогда очень популярная и доминирующая поисковая система, Yahoo с годами падала в цене, и Google ее несколько затмил.
В настоящее время Yahoo конкурирует с небольшими поисковыми системами, такими как Bing или DuckDuckGo.
4. Яндекс
Яндекс (от термина « Y et Another i NDEX er») — поисковая система, популярная в основном в восточных странах.
Хотя на него приходится менее 1 процента общей доли рынка поисковых систем, это одна из самых популярных поисковых систем в таких странах, как Россия (с более чем 60 процентами всех поисковых запросов в стране), Турция, Украина или Беларусь.
Подобно Google, Яндекс предоставляет различные виды услуг, включая Карты, Переводчик, Яндекс Деньги и даже Яндекс Музыка.
5. Baidu
Baidu — самая популярная поисковая система в Китае. Несмотря на то, что его общая доля на мировом рынке составляет всего 1 процент, он составляет более 80 процентов доли рынка в Китае с миллиардами поисковых запросов каждый день.
Baidu во многом похож на Google. Он предоставляет классические синие ссылки с зелеными URL-адресами и показывает богатые результаты так же, как и Google.
Часто задаваемые вопросы
Давайте ответим на пару часто задаваемых вопросов о поисковых системах.
Почему Google — самая популярная поисковая система?
Google, как поисковая система, на протяжении многих лет является лидером в своей отрасли и по-прежнему доминирует на рынке поисковых систем. Есть несколько причин, по которым Google является наиболее широко используемой поисковой системой.
- Это была одна из первых поисковых систем
- Предлагает релевантные результаты
- Быстро
- Постоянно совершенствуется
- Подключен к нескольким бесплатным сервисам
Как поисковые системы зарабатывают деньги?
Основной источник дохода для поисковых систем, таких как Google, поступает из различных косвенных источников.Поисковые системы могут монетизировать свои услуги через:
- Реклама — Google использует собственный рекламный сервис под названием Google Ads, благодаря которому он может помочь брендам отображать свои продукты в результатах поиска и взамен берет небольшую комиссию каждый раз, когда пользователь нажимает на объявление.
- Интернет-магазины — поисковые системы могут продвигать различные продукты в расширенных результатах поиска. Если пользователь щелкает или покупает один из продуктов, поисковая система в обмен берет небольшой процент от покупки.
- Службы — Google объединяет свои службы (например, Play Store, Google Cloud, Google Apps и т. Д.) С собственной поисковой системой и, следовательно, получает доход за счет клиентов, которые их используют.
Какой была первая поисковая машина?
Archie (от названия «Архивы») был первой поисковой системой, созданной в 1990 году студентом Аланом Эмтаджем.
Хотя и раньше существовало несколько программ индексирования (например, «X.500» или «Whois»), Арчи был первой реальной поисковой системой, способной находить определенные файлы в Интернете.
Archie работал довольно просто — он просматривал сайты, доступные в Интернете, и индексировал их как загружаемые файлы. Однако он не мог проиндексировать содержимое сайтов, и поэтому страницы результатов имели форму простого списка.
В чем разница между браузером и поисковой системой?
Веб-браузер (например, Chrome, Firefox, Microsoft Edge и т. Д.) — это программное приложение, которое устанавливается на компьютере или смартфоне. Цель браузера — предоставить удобный интерфейс для отображения веб-страниц.
Поисковая система (например, Google, Bing, Yahoo !, и т. Д.) — это онлайн-инструмент, доступный на веб-сайте, к которому можно получить доступ через веб-браузер. Цель поисковой системы — предоставлять ответы на запросы пользователей в виде соответствующих веб-страниц.
Что такое поисковая машина? — Определение из Техопедии
Что означает поисковая система?
Поисковая машина — это служба, которая позволяет пользователям Интернета искать контент через World Wide Web (WWW).Пользователь вводит ключевые слова или ключевые фразы в поисковую систему и получает список результатов веб-контента в виде веб-сайтов, изображений, видео или других онлайн-данных, которые семантически соответствуют поисковому запросу.
Список контента, возвращаемый через поисковую систему пользователю, известен как страница результатов поисковой системы (SERP).
Techopedia объясняет поисковую систему
Поисковая машина выполняет несколько шагов для выполнения своей работы. Сначала поисковый робот просматривает сеть в поисках контента, который добавляется в индекс поисковой системы.Эти небольшие боты могут сканировать все разделы и подстраницы веб-сайта, включая контент, такой как видео и изображения.
Гиперссылки анализируются для поиска внутренних страниц или новых источников для сканирования, когда они указывают на внешние веб-сайты. Чтобы помочь ботам выполнять свою работу по сканированию более эффективно, более крупные веб-сайты обычно отправляют в поисковую систему специальную XML-карту сайта, которая действует как дорожная карта для самого сайта.
Как только все данные получены ботами, поисковый робот добавляет их в огромную онлайн-библиотеку всех обнаруженных URL-адресов.Этот постоянный и рекурсивный процесс известен как индексация и необходим для отображения веб-сайта в поисковой выдаче. Затем, когда пользователь запрашивает поисковую систему, на основе алгоритма поисковой системы возвращаются релевантные результаты.
Чем выше рейтинг веб-сайта в поисковой выдаче, тем более релевантным он должен соответствовать запросу пользователя. Поскольку большинство пользователей просматривают только лучшие результаты, особенно важно, чтобы веб-сайт занимал достаточно высокий рейтинг по определенным запросам, чтобы обеспечить его успех с точки зрения посещаемости.
За последние несколько десятилетий была разработана целая наука, чтобы убедиться, что веб-сайт или, по крайней мере, некоторые его страницы «масштабируют» рейтинг, чтобы достичь первых позиций. Эта дисциплина известна как поисковая оптимизация (SEO).
Ранние результаты поисковых систем основывались в основном на содержании страниц, но по мере того, как веб-сайты научились управлять системой с помощью передовых методов SEO, алгоритмы стали намного сложнее, а возвращаемые результаты поиска могут основываться буквально на сотнях переменных.
Каждая поисковая система теперь использует свой собственный алгоритм, который взвешивает многие сложные факторы, такие как релевантность, доступность, удобство использования, скорость страницы, качество контента и намерения пользователя, чтобы отсортировать страницы в определенном порядке.
Те, кто работают оптимизаторами поисковых систем, часто тратят огромные усилия, пытаясь разгадать алгоритм, поскольку компании не прозрачны в том, как они работают, из-за несвободной природы их бизнеса и их желания предотвратить манипуляции с результатами поиска.
Раньше существовало несколько поисковых систем со значительной долей рынка. По состоянию на 2020 год Google контролирует подавляющую часть западного рынка; На втором месте незначительно присутствует Microsoft Bing. Yahoo генерирует множество запросов, но их технология внутреннего поиска передана Microsoft на аутсорсинг.
В других регионах мира большую часть рынка занимают другие поисковые системы. Например, в Китае наиболее широко используемой поисковой системой является Baidu, которая изначально была запущена в 2000 году, а в России более 50% пользователей используют Яндекс.
[Компьютеры-мастера — От новичка до эксперта за одну неделю с этим кратким курсом от Udemy]
Поисковая система Значение | 11 лучших определений поисковой машины
Существуя в различных типах, все поисковые системы собирают информацию, но организуют ее различными уникальными способами, поэтому существует так много разных поисковых систем. На базовом уровне поисковая машина — это одно из двух: робот или каталог. Хотя некоторые поисковые системы сочетают в себе функции обоих, большинство из них — это преимущественно роботы или каталоги.Робот использует программное обеспечение для поиска, каталогизации и систематизации информации в Интернете. Организация данных может быть завершена несколькими способами, в том числе с помощью комбайна, робота, паука, странника и червя, а также с использованием различных способов поиска на веб-сайтах для сбора данных.
Поисковые системы каталогов не ищут информацию в Интернете, а скорее получают ее от людей, которые вводят ее в базу данных поисковой системы. Поскольку каждый Справочник имеет свои собственные средства категоризации информации, их существует множество.В марте 2005 года популярная поисковая система Google, Inc. выпустила свою первую официальную версию своего бесплатного программного обеспечения для поиска информации, хранящейся на жестких дисках компьютеров. Программа ищет на жестких дисках информацию, содержащуюся в формате переносимых документов Adobe Acrobat (известный как PDF), а также музыку, видеофайлы и содержимое электронной почты.
В субботу, 7 мая 2005 г., поисковая система Google, Inc. прекратила работу с 18:45 по московскому времени. до 19:00. По восточному времени. Представитель Google Дэвид Крейн сказал, что проблема заключалась не в взломе, как многие думали, а в проблеме, связанной с DNS или системой доменных имен.Он не стал вдаваться в подробности.
Чурилла, К. Секреты поиска в Интернете и продвижения вашего веб-сайта. [Online, 2004.] Веб-сайт компании Gocee. http://www.gocee.com/eureka/e_sedef.htm; Админ Google. Google Down? Получение 404! Google взломали? [Online, 9 мая 2005 г.] Веб-сайт форумов поисковых систем. http://www.submitexpress.com/bbs/post-1601.html&highlight=&sid= cdfcb4b3aa56cdca7df35ed920dd8079; Вкратце. Выпущено официальное программное обеспечение Google Desktop Search. The Globe and Mail, 10 марта 2005 г., стр. B10.
Поисковая система: что это?
Поисковая система — это интернет-программа, которая собирает и систематизирует контент в соответствии с запросом пользователя.Например, человек, который выполняет поиск в поисковой системе по запросу «рестораны рядом со мной», (в идеале) увидит список веб-сайтов, которые принадлежат ресторанам в районе этого человека.
Хотя поисковые системы представляют собой чрезвычайно сложные программы, нетрудно понять основные концепции, которые ими движут. Вот как работают поисковые системы и некоторые примеры наиболее популярных поисковых систем.
Что такое поисковая машина?
Поисковая машина — это краеугольный камень Интернета.Для многих поисковая система является отправной точкой всякий раз, когда они открывают веб-браузер. Если вы не знаете точный адрес веб-сайта, который хотите посетить, или если вы не знаете, какой именно веб-сайт хотите найти, вы воспользуетесь поисковой системой, чтобы найти его.
По своей сути поисковая система — это просто компьютерная программа, работающая в Интернете. Эта программа выполняет три основные функции: сбор огромного количества информации о том, что находится в Интернете, категоризация этой информации и помощь пользователям в поиске этой категоризированной информации.
Как работает поисковая система?
Чтобы понять, как работают поисковые системы, разбейте каждую из трех основных функций по отдельности.
Во-первых, поисковые системы собирают информацию с помощью процесса, известного как «сканирование». «Веб-сканеры», программное обеспечение, разработанное поисковой системой, методично проверяют URL-адреса. Эти сканеры получают информацию с сотен миллиардов веб-сайтов, оценивая такие аспекты веб-сайта, как внутренний код и текст, который посетители читают, когда попадают на веб-страницу.
Отсюда информация индексируется в соответствии с ключевыми словами, датой публикации сайта и другими факторами.
После того, как информация проиндексирована, пользователи могут выполнять поиск по этому индексу, вводя запрос в строку поиска. Эти поисковые запросы запускают сложные алгоритмы, которые просматривают массивный индекс, чтобы найти наиболее релевантные результаты. Когда вы отправляете запрос, алгоритм одновременно оценивает смысл вашего запроса, релевантность проиндексированных веб-страниц, качество контента на этих веб-страницах, функциональность этих веб-страниц и контекст вашего поиска (местоположение, из которого вы выполняли поиск, ваша история поиска и т. д.).
Мотивации поисковых систем
Полезно взглянуть на мотивацию поиска с трех разных точек зрения.
- Искатель: Это человек, который ищет в Интернете информацию, продукты или услуги. Они хотят ввести несколько ключевых слов, которые представляют эту информацию, продукт или услугу, и быстро появляются соответствующие веб-сайты, которые эффективно отвечают их потребностям.
- Поисковая система: Поисковые системы зарабатывают деньги, продавая рекламное пространство веб-сайтам, предприятиям и маркетологам.Чем больше поискового трафика они могут генерировать, тем больше внимания привлекает их реклама и тем больше денег они получают. Их цель — сделать так, чтобы наиболее релевантные сайты появлялись в верхней части результатов поиска. Таким образом, поисковики находят то, что хотят, и развивают позитивные отношения с поисковой системой. В следующий раз, когда они захотят выполнить поиск в Интернете, они (надеюсь) вернутся к этой поисковой системе.
- Веб-сайт или продавец: Они хотят, чтобы эти веб-поисковики находили их сайт по релевантным ключевым словам, чтобы они могли продвигать свои продукты или услуги.
Все дело в том, что содержимое страницы соответствует тому, что хочет поисковик, что делает его счастливым, поэтому в следующий раз он возвращается к той же поисковой системе, что делает его счастливым. Когда поисковик находит понравившийся веб-сайт, он счастлив, потому что он получает больше трафика от потенциальных клиентов.
Самые популярные поисковые системы
По всем параметрам, Google — самая популярная поисковая система, и ее название стало синонимом выполнения запросов в поисковых системах (что-то вроде «гугл»).Однако это не единственная поисковая система. У интернет-пользователей есть множество вариантов. Вот разбивка некоторых из самых популярных поисковых систем по доле рынка, зафиксированная NetMarketShare в июле 20200 года:
- Google: 83.86%
- Baidu: 7,01%
- Bing: 6,14%
- Yahoo !: 1.34%
- Яндекс: 0.85%
В то время как поисковики могут свободно изучать свои варианты, предприятиям и маркетологам следует обращать внимание на то, какие поисковые системы являются наиболее популярными.Нет смысла тратить весь свой рекламный бюджет на поисковую систему, которая почти не используется.
Поисковая оптимизация
Поисковая оптимизация (SEO) — это попытка улучшить производительность веб-сайта в поисковой системе. Для предприятий, которые хотят эффективно использовать свой веб-сайт для увеличения продаж, решающее значение имеет надежная стратегия SEO.
Если ваш веб-сайт не попадает на первые несколько страниц соответствующего результата поисковой системы, то маловероятно, что клиент найдет ваш сайт через эту поисковую систему.Например, если вы ведете бизнес в сфере недвижимости в Майами, штат Флорида, вы хотите сосредоточить свои усилия по поисковой оптимизации на том, чтобы ваш сайт появлялся, когда люди ищут «недвижимость в Майами» в поисковой системе.
Ключевые выводы
- Поисковые системы — это программы, которые упрощают людям поиск в Интернете соответствующей веб-страницы.
- Три основные функции поисковой системы — это сбор информации о веб-страницах, категоризация этих веб-страниц и создание алгоритма, который упрощает поиск релевантных веб-страниц для людей.
- Google — безусловно, самая известная поисковая система.
- Когда веб-сайт пытается улучшить свою производительность в поисковой системе, это называется поисковой оптимизацией (SEO).
Что такое поисковая система? — Определение с сайта WhatIs.com
От
В Интернете поисковая машина — это скоординированный набор программ, который включает:
- Паук (также называемый «сканером» или «ботом»), который исследует Интернет, переходя по гиперссылкам, начиная с основной группы «исходных» URL-адресов, охватывающих основные узлы.
- Программа, которая создает огромный индекс (или базу данных) из прочитанных страниц
- Программа, которая получает ваш поисковый запрос, сравнивает его с записями в индексе и возвращает вам результаты
Google — наиболее широко используемая поисковая система в мире, охватывающая около 92% поисковых пользователей во всем мире. Yahoo и Bing занимают второе место с долей чуть более 2% каждый. DuckDuckGo приобрела некоторую популярность благодаря своей ориентации на защиту личных поисковых данных пользователей.Другие популярные поисковые системы в мире — это Baidu (Китай), Яндекс (Россия) и Naver (Южная Корея).
Различные подходы к поисковым системам
- Основные поисковые системы, такие как Google, Bing и Yahoo, индексируют контент значительной части Интернета и позволяют пользователям запрашивать свой индекс, чтобы найти релевантные страницы.
- Специализированные поисковые машины контента могут более избирательно определять, какая часть Интернета сканируется и индексируется.
- Поисковые системы для конкретных стран могут отдавать предпочтение веб-сайтам на английском языке по сравнению с веб-сайтами на английском языке.
- Отдельные веб-сайты, особенно крупные корпоративные сайты, могут использовать поисковую систему для индексации и получения содержимого только своего собственного сайта. Некоторые из крупных компаний, занимающихся поисковыми системами, лицензируют или продают свои поисковые системы для использования на отдельных сайтах.
Где искать
Google — это поисковая система, которую выбирают большинство людей в мире. Качество их результатов имеет тенденцию превосходить своих конкурентов. Результаты поиска интегрированы с другими базами данных: картами, новостями, изображениями, Gmail и видео (YouTube принадлежит Google).С течением времени Google перешел на предоставление результатов, основанных исключительно на популярности (ссылки), в сторону большей ориентации на намерения пользователя при выполнении запросов.
Некоторые пользователи могут предпочесть использовать Bing или Yahoo для других своих интегрированных предложений. Некоторые пользователи могут предпочесть сайт с приоритетом конфиденциальности данных, например DuckDuckGo.
Как искать
Советы по вводу аргумента поиска см. В каждой поисковой системе. У Google есть полезная страница о том, как искать.
Последнее обновление: октябрь 2018 г.
Продолжить чтение о поисковой системе
.