Содержание
Sсrареs – универсальный автоматический парсер на WordPress
Sсrареs — плагин для WordPress, который автоматически копирует содержимое с сайта на ваш сайт WordPress, один или несколько раз в выбранные промежутки времени.
Плагин парсит контент из ленты, по селекторам, по контенту, по шаблонам. Можно настроить расписание работы парсера.
Что можно парсить? Идеи для парсинга
- Новости
- Валюты
- Прогноз погоды
- Спортивные результаты
- Блоги и журналы
- Статьи
- Объявления доски объявлений
- Социальные профили
- Изображения и галереи
- Видео
- Кино
- Музыка и плейлисты
- Приложения и игры
- Книги
- Товары
- Вакансии и резюме по поиску работы
- Учебные программы
- Меню ресторанов
- Рецепты
- Билеты и расписание аэропортов
- Автобусные рейсы
- Отели
- Туры и отдых
- и многое другое
Вы можете парсить целые статьи по селектору или с помощью ленты RSS, парсить товары, новости и отдельные елементы на странице (курсы валют, прогноз погоды, различные информационные виджеты).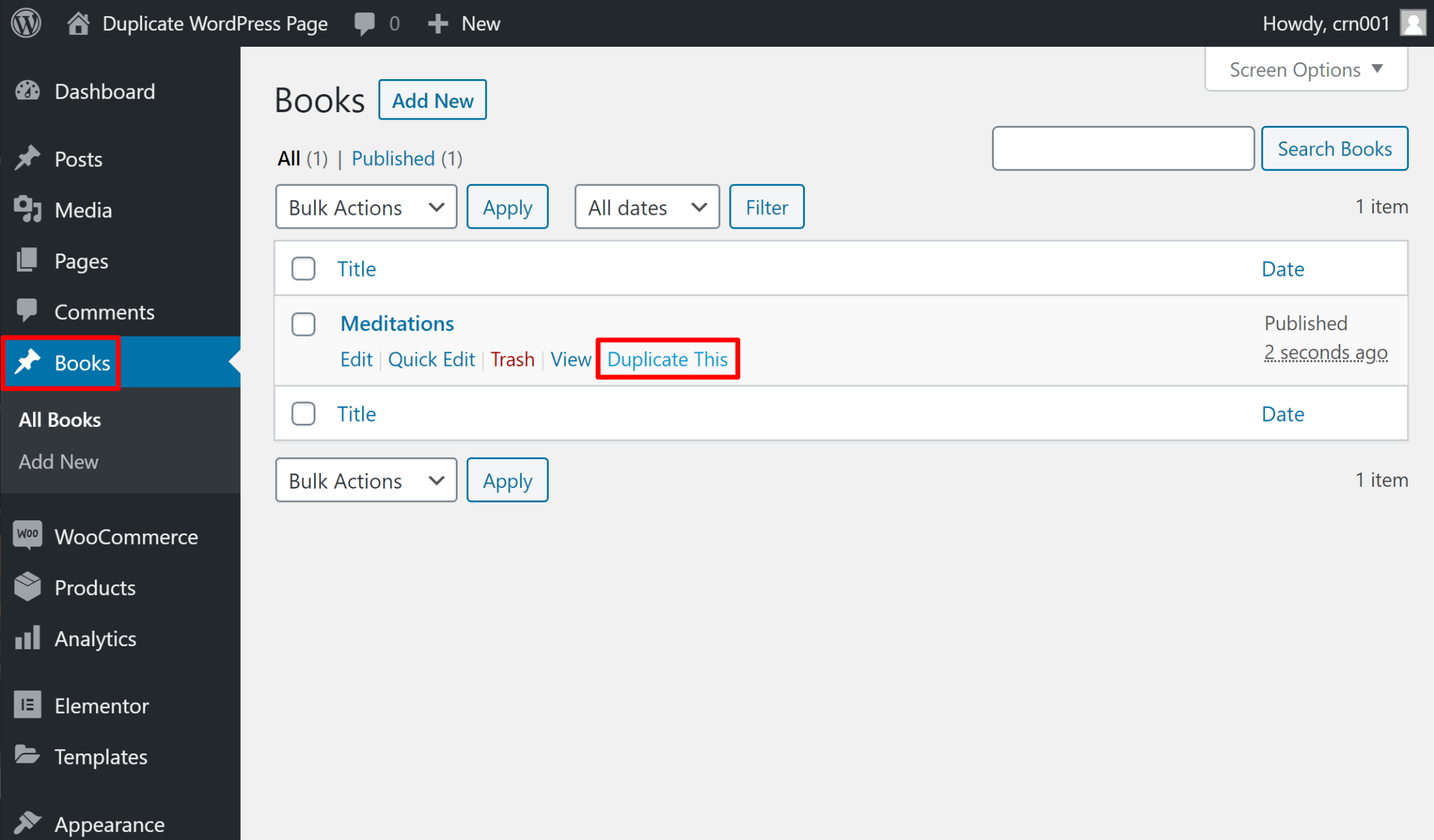
Scrapes поддерживает и автоматически заполняет все поля записи WordPress
- Тип записи
- Таксономия
- Название записи
- Контент
- Анонс
- Произвольные поля
- Обсуждение
- Автор
- Статус
- Дата
- Изображение
Вы прочитали, что работать придется с селекторами? Бояться этого не нужно, ведь выбор нужного селектора на странице сайта-донора происходит с помощью визуального инструмента. Вы просто наводите мышь на нужный блок и таким образом указываете плагину, что парсить.
Плагин Scrapes автоматически определяет селекторы на странице и выделяет их цветными блоками, вам остается только выбрать какой блок и в какое поле его вставить. Это может быть миниатюра записи, постраничная навигация, дата записи, цена и т.д.
Если возникли трудности с автоматическим определением селектора — всегда можно указать XPath вручную.
Возможности плагина
- Простой и интуитивно-понятный интерфейс настройки парсера.

- Работает в фоновом режиме — настройте плагин один и запустите автоматический парсинг.
- Высокая производительность
- Скачивание изображений — плагин загружает изображения в собственную медиабиблиотеку или загружает их с удаленного URL-адреса.
- Многозадачность — на сайте может одновременно работать несколько парсеров.
- Оптимальная конфигурация — плагин отлично работает на любых хостингах.
- Парсит контент на любом языке.
- Не создает дубликаты записей и товаров.
- Поиск и замена — в настройках парсера можно указать какие элементы на странице следует заменять или удалять, чтобы они не были опубликованы на вашем сайте в оригинальном варианте.
3 режима работы парсера
- Single — копирование/обновление отдельной страницы (с определенными элементами, например, виджет погоды, курсы валют, спортивные результаты и т.д.)
- Serial — копирование записей/статей/товаров (например, лента Твиттер, видео из Youtube, записи из Facebook, товары Amazon или AliExpress и др. )
- Feed — копирование контента из ленты RSS/ATOM (например, ленты разных сайтов, лента Flickr и т.д.)
 )
)Возможности парсера
- Поддержка произвольных полей.
- Поддержка произвольных типов записей и таксономий (куда будем публиковать наши записи).
- Поддержка магазина WooCommerce (тип товара, обычная цена, цена продажи, URL товара, текст на кнопке, артикул товара, управление запасами, избранный товар, галерея).
- Выбор визуальных селекторов на сайте донора.
- Автоматическое определение контента (заголовок, анонс, статья, теги, миниатюра, цена).
- Создание произвольных шаблонов для отображение контента
- Создание категорий.
- Планирование публикаций.
- Автоматический перевод контента на разные языки (в т.ч. на русский язык).
- Функция найти и заменить.
- Настройка цикла и паузы.
- Перезапись существующих записей.
- Возможность локализации плагина на любые языки.
- Фильтры контента (например: не пропускать товары с определенной ценой, статьи без миниатюры, фильтры по названию и т.д.).
Примеры работы парсера
Парсинг курса валюты (режим Single) и отображение на странице
Creating a basic single post scraper to scrape latest currency from XE with Scrapes
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг статей (режим Serial) на примере сайта Themeforest с последующей публикацией на сайте
Creating a advanced serial post scraper to scrape themes from ThemeForest with Scrapes
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг товаров с AliExpress и публикация в интернет-магазине WooCommerce (режим Serial)
Creating a basic serial WooCommerce product scraper to scrape products from AliExpress with Scrapes
Смотреть это видео на YouTube.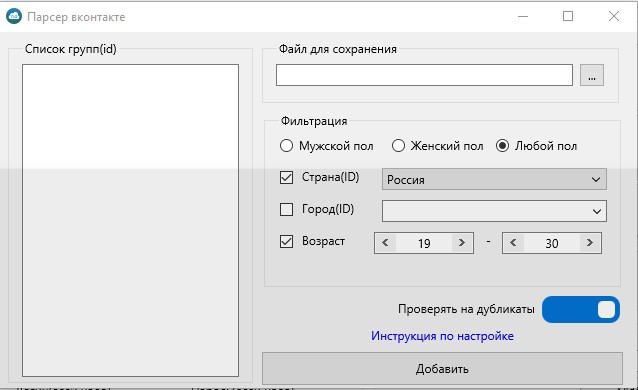
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг постов из Facebook с последующей публикацией на сайте (режим Serial)
Scrape and auto post Facebook post to WordPress
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг видео из Youtube (режим Serial) с последующей публикацией на сайте
Scrape and auto post YouTube videos to WordPress
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг фото из Flickr (режим Feed) с последующей публикацией на сайте
Scrape and auto post Flickr photos to WordPress
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг записей на примере TechCrunch (режим Serial) с последующей публикацией на сайте
Creating a basic serial post scraper to scrape posts from TechCrunch with Scrapes
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг постов из Twitter и публикация на сайте (режим Serial)
Scrape and auto post Twitter post to WordPress
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Парсинг товаров с Amazon и публикация в интернет-магазине WooCommerce (режим Serial)
Scrape and auto post products from Amazon to create an affiliate WooCommerce site
Смотреть это видео на YouTube.
Подпишитесь на канал InwebPress, чтобы узнать больше о создании и настройке сайтов!
Ответы на вопросы
Поддерживает ли плагин работу с вариациями в WooCommerce?
Ответ от автора плагина:
It can create «Simple», «External» and «Virtual» WooCommerce products automatically from the target you want but «Grouped», «Variable» and «Downloadable» product types and product attributes are not fully supported currently.
Т.е. можно парсить простые, внешние и виртуальные товары.
А сгруппированные, вариативные и скачиваемые поддерживаются не полностью.
Ответ от автора сайта:
Пробовал парсить товары с атрибутами в WooCommerce. Атрибуты не вставляются (нужно вручную товарам задавать атрибуты). Плагином хорошо парсить/обновлять простые товары и статьи.
Scrapes — Самый лучший парсер для wordpress. Создание автонаполняемого сайта бесплатно.
Scrapes – Самый лучший парсер для wordpress. Создание автонаполняемого сайта бесплатно.
Scrapes – это плагин WordPress, который автоматически копирует содержимое с веб-сайта на ваш сайт WordPress один или несколько раз в выбранные промежутки времени. Он очень прост в использовании, не требует каких-либо навыков программирования и предназначен для лучшего удобства пользователей. Вам больше не нужны API, которые требуют регистрации и предоставляют ограниченный доступ, а также вы можете получать данные с веб-сайтов, не поддерживающих API. alt]\b
alt]\b
Скачать автопарсер Scrapes 2
Парсинг обновление курса валют для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг youtube для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг Envato market для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг автопарсинг сайта для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг Twitter для wordpress, создание автонаполняемого сайта бесплатно.
 youtube.com/embed/2I9nrdN0hT0?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/2I9nrdN0hT0?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Парсинг AliExpress для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг Flickr фото для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг Facebook для wordpress, создание автонаполняемого сайта бесплатно.
Парсинг Amazon для wordpress, создание автонаполняемого сайта бесплатно.
Парсер Youtube — YouTube Scraper v.1.60
Продвигать свои сайты самостоятельно с каждым годом становиться все труднее. Значительно выросла конкуренция за места, да и поисковые системы все больше закручивают гайки. В этих реалиях роль хороших инструментов для сбора контента имеет большое значение. Парсер Youtube, одна из бесплатных программ для сбора контента из популярного хостинга Youtube.
Парсер Youtube умеет:
- Парсить выдачу Youtube по ключевым словам
- Скачивать видео
- Поддержка прокси
Интерфейс программы состоит из трех вкладок:
Пользоваться парсером легко и просто — на вкладке «Scraper» вводим в поле «Keywords» нужные слова-запросы. Указываем нужные теги для парсинга, количество результатов и жмем на «Start».
Через некоторое время можно увидеть результаты парсинга — адрес ролика, название, автор, описание, количество просмотров и время загрузки ролика.
Двойной клик по ссылке открывает ее в браузере для просмотра. Парсер ютуб поддерживает языки ключевых слов: русский, английский.
В парсер youtube scraper интегрирован грабер видео, что позволяет сразу после парсинга ссылок, скачать нужные видео ролики. В настройках следует указать нужные параметры видео, количество потоков скачки, в поле «Video urls to download» прописать адрес ссылки и нажать на кнопку «Download».
Надо сказать что данная функция грабер видео, работает только через прокси, во избежание запрета IP от youtube.
Парсер Youtube решает многие задачи для вас:
- Собрать ссылки YouTube
- Парсинг выдачи YouTube
- Сбор данных об авторах YouTube, популярности видео и др.
Бесплатный парсер youtube по ключевым словам, поможет быстро найти видео контент, скачать видео и съэкономить время. Размер парсера всего около 50kb.
Скачать с ЯндексДиск
добавляем ленивую загрузку на сайт
Увеличить скорость работы WordPress-сайта можно с помощью ленивой загрузки (lazy load wordpress).
Очевидно, что чем больше запросов браузер отправляет серверу, тем дольше длится загрузка. В то же время, чем больше весит страница (например, если она содержит большое количество изображений), тем дольше она будет загружаться.
Ленивая загрузка задерживает загрузку некоторых частей страницы до тех пор, пока они не понадобятся пользователю. Данная статья рассказывает о преимуществах и недостатках этого метода. А также том, как реализовать его в WordPress.
Ленивая загрузка – это способ не дать браузеру загружать все части страницы одновременно. Веб-страница становится легче и требуется меньше данных для передачи с сервера в браузер.
Суть этого способа заключается не в том, чтобы запрещать браузеру загружать ресурсы и изображения. Ленивая загрузка просто задерживает их отображение до того момента, когда они понадобятся пользователю.
Например, картинка не нужна на странице, пока пользователь не прокрутит ползунок, чтобы ее увидеть. Поэтому браузеру не обязательно загружать эту картинку, пока она не понадобится. Именно это и делает ленивая загрузка.
Ленивая загрузка чаще всего применяется к изображениям. Возможно, вы замечали ее на популярных сайтах типа Buzzfeed. Они используют ленивую загрузку, чтобы контент быстрее отображался в браузере.
Также отложенная загрузка применяется к видео, скриптам и комментариям. По сути, перемещение файлов JavaScript в футер страницы – это способ ускорения загрузки страницы.
Наверно, вы замечали, что YouTube загружает комментарии только после прокручивания страницы вниз. Таким образом обеспечивается быстрая загрузка видео.
Бесконечная прокрутка – это альтернатива классической пагинации страниц. При ее использовании дополнительные записи загружаются во время скроллинга страницы вниз. Это можно заметить на Pinterest и Pocket.
Это удобно для пользователей, ведь не нужно все время нажимать на номер следующей страницы.
Главное преимущество отложенной загрузки очевидно – быстрое отображение содержимого сайта. А также экономия трафика для пользователей. Ведь они не только быстрее загрузят сайт, но и не будут тратить трафик на изображения, которые могут и не увидеть.
Отложенная загрузка – не самый идеальный метод ускорения работы сайта. Рассмотрим его основные недостатки.
Из-за задержки загрузки часть контента сайта может быть не проиндексирована поисковым роботом. Из-за этого многие разработчики не используют отложенную загрузку для текстового содержимого.
Для большинства пользователей лучшим вариантом станет использование плагинов ленивой загрузки для WordPress.
Данный плагин установили более 90 000 раз и его рейтинг достаточно высок – 4 звезды.
Lazy Load использует jQuery.sonar для загрузки изображений только тогда, когда они появляются в области просмотра. Разархивированный плагин весит всего 20 КБ.
Плагин BJ Lazy Load установили более 60 000 раз и его рейтинг так же высок. Он заменяет все изображения и фреймы (включая видео с YouTube и Vimeo) в контенте заполнителем до просмотра пользователем.
Lazy Load by WP Rocket выполняет ленивую загрузку изображений и фреймов. Включая миниатюры, содержимое виджетов, аватары и смайлики. Данный плагин не использует библиотеки JavaScript. Поэтому он весит менее 10 КБ.
Более 10 000 сайтов используют Lazy Load от WP Rocket, что вызывает доверие.
Это один из немногих плагинов в этом списке, который имеет дополнительные параметры конфигурации. Он подходит для ленивой загрузки изображений, видео и фреймов в записях, страницах, виджетах, миниатюрах и аватарах. a3 Lazy Load совместим с WooCommerce.
Плагин позволяет выбрать эффекты для изображений, которые появляются на сайте. Также можно указать, куда загружать его скрипт: в шапку или футер страницы (плагин ленивой загрузки, который сам себя загружает).
Данный плагин совместим с рядом мобильных и кэширующих плагинов, а также с сетями доставки контента.
Этот плагин ленивой загрузки изображений использует мало ресурсов. Crazy Lazy задерживает загрузку изображений до того, как их увидит пользователь.
Также можно установить собственные заполнители с помощью CSS и заменить ими изображения.
Еще один плагин отложенной загрузки изображений и фреймов. Он весит всего 5 КБ. Реализован шорткод для деактивации ленивой загрузки. В том числе и для отдельных изображений.
Плагин WordPress Infinite Scroll позволяет добавить на сайт бесконечную прокрутку. Он предназначен для отложенной загрузки записей, комментариев и других элементов страницы.
WordPress Infinite Scroll также работает с WooCommerce и Easy Digital Downloads.
Плагин позволяет размещать специальные ссылки на ролики, которые загружает проигрыватель YouTube только после нажатия.
Также можно использовать шорткоды для вывода видеоконтента или установить плагин для автоматического парсинга ссылок YouTube.
Альтернативный плагин ленивой загрузки видео – Lazy Load for Videos.
В этой статье мы проанализировали, как работает и чем полезна ленивая загрузка. Ее можно применять не только к изображениям, но и к видео, скриптам, комментариям, записям и страницам.
Данная публикация является переводом статьи «Lazy Loading for WordPress: How to Add It to Your Website» , подготовленная редакцией проекта.
Как парсить информацию с любого сайта при помощи Screaming Frog
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК, и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.
Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
В итоге мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Парсер видео Youtube для iMacros – YT Video Parser
7.99 USD
Парсер видео Youtube помогает собрать данные с поисковой выдачи сайта Youtube.
Вы вводите поисковый запрос и перед вами открывается список релевантных видео. Вот эти самые видео парсер и собирает, а именно ссылку на видео и его название.
Макрос написан для плагина iMacros браузера Firefox. Версия на момент создания макроса:
Версия iMаcros – 8.9.7
Версия Firefox – 56.0
Язык интерфейса Facebook русский/английский
Как установить плагин iMacros.
Особенности YT Video Parser
- Результат сохраняется в файле yt_base_video_parse.txt. В итоге получается база из 2-х колонок: ссылка на видео и его название. Этот файл можно открыть с помощью Excel.
- Парсер в состоянии скачать ограниченной число видео. Это зависит от того, сколько сможет отобразить сама страница Youtube.
Инструкция
1. Установка скрипта
- Купить скрипт. Продажа осуществляется с помощью сервиса Interkassa на выбор. Интеркасса предлагает очень много вариантов оплаты. Ссылка для скачивания файла придет на указанный вами e-mail при покупке. Будьте внимательны!!!
Если по какой-то причине после совершенной оплаты ссылка на e-mail не пришла, или не скачивается файл, срочно пишите мне на e-mail: [email protected]. - Скачать архив YT_Video_Parser.rar по ссылке, которая придет на ваш e-mail, после оплаты.
- Разархивировать и скопировать файл YT_Video_Parser_SFT.js в папку Macros.
- Как найти папку Macros на компьютере читайте а FAQ.
2. Работа с макросом YT Video Parser
- Открыть браузер Firefox, зайти в социальную сеть Youtube.
- Ввести поисковый запрос в строку поиска вверху. Дождаться результатов.
- Включить плагин iMacros, найти в левом окошке скрипт YT_Video_Parser_SFT.js .
- Запустить скрипт с помощью двойного щелчка.
- После окончания работы, макрос сохранит базу данных в файле yt_base_video_parse.txt в папке Downloads. Вы сможете открыть файл с помощью программы Excel.
НАСЛАЖДАЙТЕСЬ!!! Макрос работает за вас)
Демонстрация скрипта
видео ожидается
Добавляем видео с YouTube на сайт через iframe. Дополнительные настройки встраивания видео из Youtube
Здравствуйте, сегодня я вам покажу как можно добавить видео с YouTube на свой сайт. Мы разберем дополнительные настройки которые позволяют регулировать следующее: запуск видео сразу после прогрузки страницы, запуск видео с определенного момента, запрет на просмотр видео в полном экране и так далее.
Для того чтобы добавить видео, вам необходимо разместить следующий код на своем сайте:
<iframe src="https://www.youtube.com/embed/ET1ECoJqdGg?rel=0&showinfo=0&autoplay=1" frameborder="0" allowfullscreen></iframe>
Как вы видите добавление видео на сайт происходим с помощью тега iframe . По стандарту здесь используются только некоторые атрибуты: width (задает ширину окна), height (задает высоту окна), src (ссылка на видео), frameborder (убирает рамку вокруг окна), allowfullscreen (разрешает полноэкранный режим).
Для добавления своего видео, вам достаточно скопировать представленный выше код и заменить ссылку которая находиться в атрибуте src.
Дополнительные параметры
Дополнительные параметры необходимо прописывать, перечисляя их в конце ссылки, внутри тега src.
Перед перечисление необходимо поставить ?, после этого вы перечисляете параметры и их значения, разделяя их &.
<iframe src="https://www.youtube.com/embed/ET1ECoJqdGg?rel=0&showinfo=0&autoplay=1"></iframe>
В принципе если вы умеет работать с GET запросами, то вы без проблем справитесь с этой задачей.
Список дополнительных параметров:
&rel=0 — отключение похожих видео после просмотра ролика.
&showinfo=0 — убирает название и рейтинг ролика из плеера.
&autoplay=0 — убирает автоматическое воспроизведение ролика.
&loop=0 — не повторяет видео после просмотра, если оно в плеере одно.
&enablejsapi=0 — отключает возможность использования API Javascript (подробнее об API JS)
&hl=ru_RU — устанавливает локаль для видео, читается как «для русскоговорящих людей» (локаль можно менять)
&egm=0 — Выключает всплывающее расширенное меню.
&border=0 — Убирает рамку вокруг плеера, Основной цвет рамки можно указать с помощью параметра color1, а дополнительный цвет — с помощью параметра color2.
Значения: любое значение RGB в шестнадцатеричном формате. Параметр color1 описывает цвет основной рамки, а параметрcolor2 — цвет фона панели управления видео и цвет дополнительной рамки.
&fs=0 — отключает возможность полноэкранного просмотра видео
&start=225 — запускает видео с 225 секунды (цифра секунд — меняется)
&fmt=6 — Устанавливает хорошее качество видео. &fmt=18 еще лучше, а &fmt=22 будет наилучшим. Изначально видео должно быть в high definition (HD) качестве (HD) для работы параметра.
&t= — Видео тег в Youtube работает в связке с ID вашего ролика, пишется словом (напр. &t=Politics )
&disablekb=1 — отключает управление клавиатурой.
&showsearch=0 — отключает показ окна поиска при уменьшенном виде ролика.
&start=5 — запускает ролик через 5 секунд, после загрузки страницы (кол-во секунд — меняется)
Автоматический плагин WordPress от ValvePress
Автоматический плагин WordPress сообщений практически с любого веб-сайта в WordPress автоматически.
Он может импортировать с популярных сайтов, таких как Youtube и Twitter, используя их API, или практически с любого веб-сайта по вашему выбору, используя свои модули парсинга.
Автоматическая публикация RSS-каналов в WordPress | |
Автоматическая публикация с любой веб-страницы в WordPress | |
Автоматическая публикация с любого веб-сайта в WordPress | |
Автоматическая публикация продуктов Amazon в WordPress | |
Автоматическая публикация продуктов eBay в WordPress | |
Автоматическая публикация продуктов Walmart в WordPress | |
Автоматическая публикация продуктов ClickBank в WordPress | |
Автоматическая публикация с Envato в WordPress | |
Автоматическая публикация объявлений Craigslist в WordPress | |
Автоматическая публикация из CareerJet в WordPress | |
Автоматическая публикация из Facebook в WordPress | |
Автоматическая публикация из Twitter в WordPress | |
Автоматическая публикация из Instagram в WordPress | |
Автоматическая публикация из Pinterest в WordPress | |
Автоматическая публикация Reddit в WordPress | |
Автоматическая публикация изображений Flickr в WordPress | |
Автоматическая публикация видео с Youtube в WordPress | |
Автоматическая публикация видео Vimeo в WordPress | |
Автоматическая публикация видео DailyMotion в WordPress | |
Автоматическая публикация звуков SoundCloud в WordPress | |
Автоматическая публикация из Itunes в WordPress | |
Автоматическая публикация статей Ezine в WordPress | |
Автоматическая публикация Spintax в WordPress | |
Автоматическая публикация видео TikTok в сообщениях WordPress |
Автоматическая публикация статей в wordpress. Плагин может искать статью в электронном журнале.com для заданных вами ключевых слов и статей по автопилоту, соответствующих качеству публикации.
Автоматическая публикация контента из каналов. Плагин может регулярно проверять указанные вами каналы и публиковать каждый новый элемент канала как новое сообщение.
Получение полного содержания из сводных каналов. WordPress automatic может конвертировать усеченные каналы в сообщения с полным содержанием с большим успехом.
Извлечь определенные части из исходных сообщений ленты. WordPress automatic может извлекать две указанные части исходного сообщения по идентификатору / классу CSS, XPath или REGEX и объединять их для публикации в WordPress.
Найти и заменить. Плагин может искать в извлеченном контенте любой текст / область и заменять его указанным текстом.
Исходное время сообщений. WordPress автоматически может установить сообщение, созданное в wordpress, в то же время, когда оно было создано в ленте.
Категории экстрактов. Плагин может установить для созданных категорий сообщений те же категории, что и для исходных сообщений.
Извлечь исходные теги. WordPress автоматически может извлекать теги из исходного сообщения с помощью идентификатора / класса CSS и устанавливать как теги в созданном сообщении.
Извлечение оригинального автора. WordPress автоматически может извлечь имя автора из исходного сообщения и назначить автора в созданном сообщении, если он существует, или создаст его, если не существует.
Пропускать посты без содержания. Плагин может проверять извлеченный контент и пропускать публикации, если в нем нет контента.
Пропускать неанглоязычные сообщения. WordPress automatic имеет возможность установить статус сообщения как ожидающий, если он подозревает, что он написан не на английском языке.
Пропускать публикации без изображений. Плагин имеет возможность проверять извлеченный контент и пропускать его, если он не содержит изображений.
Сначала размещайте самые старые элементы. WordPress automatic имеет возможность сначала публиковать более старые элементы. По умолчанию сначала публикуются самые новые элементы.
Декодирование HTML-сущностей. WordPress automatic имеет возможность декодировать html-объекты извлеченного содержимого / заголовка.
Преобразовать кодировку перед отправкой. Плагин имеет возможность конвертировать извлеченную кодировку содержимого из любой конкретной кодировки в utf-8 для совместимости с wordpress.
Пропуск повторяющегося заголовка. Плагин может проверить отсутствие ранее опубликованных сообщений с таким заголовком.
Лучшее изображение из Facebook og: тег изображения. Плагин может извлекать изображение, используемое для facebook, как миниатюру, чтобы установить в качестве избранного изображения.
Автоматическая публикация продуктов Amazon в wordpress . WordPress automatic может искать на Amazon продукты, соответствующие вашим ключевым словам, публиковать их и автоматически добавлять партнерские ссылки, чтобы вы могли получать комиссионные с продуктов, проданных через ваших рефералов.
Обзор узлов поддерживает . Вы можете публиковать сообщения из узла просмотра Amazon, который является подкатегорией. просто посетите findbrowsenodes.com и получите нужный идентификатор узла. Как только у вас будет идентификатор узла, добавьте указанный узел, и плагин ограничит публикацию только элементами из этого узла.
Фильтр ценового диапазона .Вы можете установить ценовой диапазон, в котором плагин будет получать товары с ценой между минимальным и максимальным значениями цен.
Поддержка порядка поиска . Вы можете установить значение сортировки для возвращаемых элементов . Например, заказ товаров по месту продажи, цене и т. Д.
Поддержка критериев поиска . Вы можете установить критерии поиска для фильтрации возвращаемых результатов. Например, размещение фильмов с участием определенного актера или электроника от определенного производителя, такого как Apple.
Добавить в схему покупки, ссылка . Обратные ссылки на Amazon могут быть либо на страницу продукта, либо добавлены непосредственно в подтверждение диаграммы.
Поддержка Woo-Commerce . Элементы Amazon могут быть добавлены как продукты woo-commerce и функционировать так же, как любой продукт, добавленный к вашим продуктам woo-commerce wordpress.
— Поддерживаемые сайты Amazon:
Автоматическая публикация продуктов Clickbank в wordpress. автоматический плагин wordpress может выполнять поиск в банке кликов .net для продуктов, соответствующих указанным вами ключевым словам, размещайте сообщения в своем блоге и автоматически добавляйте партнерские ссылки.
Автоматическая публикация видео с Youtube в wordpress. wordpress automatic может искать youtube.com видео, соответствующие вашим ключевым словам, и публиковать их в своем блоге wordpress
* (теперь поддерживаются все языки)
Поддержка конкретных каналов. можно публиковать с любого канала YouTube по ключевым словам или без фильтрации.
Поддержка специальных списков воспроизведения. wordpress automatic может публиковать сообщения из любого определенного списка воспроизведения.
Поддержка полного описания видео. wordpress automatic может получить полное описание размещенного видео с YouTube.
Публикуйте теги Youtube как теги. wordpress automatic может извлекать теги для видео и устанавливать эти теги как теги wordpress.
Опубликовать комментарии Youtube в качестве комментариев. Плагин может захватывать комментарии к видео и публиковать их как комментарии wordpress.
Соответствие определенному языку и стране. Релевантность видео может быть настроена на определенный язык, а также на определенную страну.
Автоматическое воспроизведение видео. размещенных видео могут воспроизводиться автоматически.
Различные фильтры. Набор фильтров, таких как порядок, категория, лицензия, тип, продолжительность и определение.
Отключить предложения. wordpress automatic может отключать видео предложения в конце видео.
Пропускать невстраиваемые видео. wordpress automatic может пропускать видео, которые нельзя встраивать.
Контроль даты. wordpress automatic может пропускать видео старше определенной даты, публиковать видео с исходной датой или публиковать сначала более старые элементы.
Автоматическая публикация видео Vimeo в wordpress. wordpress automatic может искать vimeo.com видео, соответствующие вашим ключевым словам, и размещать их в своем блоге wordpress.Вы также можете публиковать сообщения от конкретного пользователя / канала.
Автоматическая публикация видео с определенного канала YouTube / пользователя в wordpress. вы можете автоматически добавлять видео каналов в wordpress. у вас есть возможность добавлять видео от определенного пользователя / канала, выполняя поиск по определенным ключевым словам или без фильтрации.
Автоматическая публикация аукционов eBay на wordpress. автоматический плагин wordpress может размещать аукционов ebay.com по указанным вами ключевым словам. вы также можете публиковать сообщения от конкретного продавца eBay, выполнив поиск по его товарам по указанным ключевым словам или даже без фильтрации.
— Поддерживаемые сайты ebay: США, IE, AT, AU, BE, CA, FR, IT, DE, ES, CH, UK, NL
Автоматическая публикация изображений Flickr в wordpress. автоматический плагин wordpress может размещать flicker.com изображения по указанным вами ключевым словам. он также может публиковать сообщения от конкретного пользователя flickr, выполняя поиск в элементах этого пользователя по указанным ключевым словам или без фильтрации.
Автоматическая публикация из Facebook в WordPress. WordPress Automatic Plugin может публиковать сообщения со страниц Facebook, , открытых групп Facebook, закрытых групп или личных профилей, и каждое новое сообщение из FB будет автоматически добавляться как сообщение в WordPress.где он может публиковать полноразмерные изображения, опубликованные на странице, видео и ссылки.
НОВИНКА: теперь можно публиковать сообщения из личных профилей facebook
Автоматическая публикация из Twitter в wordpress. автоматический плагин wordpress может автоматически публиковать твитов Twitter в wordpress. Там, где он может публиковать сообщения с помощью поиска, хастага или конкретного пользователя, а твиты могут публиковаться в виде простого текста или в виде карточки твиттера.
Автоматическая публикация из SoundCloud в wordpress. автоматический плагин wordpress может автоматически публиковать песен SoundCloud в wordpress. Где он может публиковать по ключевому слову, пользователю или плейлисту.
Автоматическая публикация из Pinterest в WordPress. автоматический плагин для wordpress может автоматически публиковать пины для пин-интереса в wordpress автоматически по указанным ключевым словам или от определенного пользователя / доски.
Автоматическая публикация из Instagram в WordPress. автоматический плагин wordpress может автоматически публиковать Instagram в wordpress для определенных тегов или от определенного пользователя. Автоматическая публикация из Craigslist в WordPress. автоматический плагин wordpress может автоматически импортировать Craigslist в wordpress для любой категории, поиска или продавца.
Автоматическая публикация сообщений из Itunes в WordPress. Автоматический плагин WordPress может автоматически импортировать элементы Itunes в WordPress по ключевому слову или исполнителю, чтобы публиковать приложения, песни, фильмы, электронные книги, подкасты и многое другое из Itunes. Он работает как партнерский плагин WordPress iTunes, так как автоматически устанавливает вашу партнерскую ссылку на лету.
Автоматическая публикация с Envato на wordpress. Автоматический плагин wordpress может автоматически импортировать элементы Envato с таких рынков Envato, как ThemeFores, CodeCanyon, VideoHive, AudioJungle, GraphicRiver и 3dOcean, в WordPress по ключевому слову, автору, тегу или категории, чтобы он мог публиковать темы, плагины, html-файлы, psd, аудио и многое другое. Он работает как плагин для wordpress envato affiliates, так как он автоматически устанавливает вашу партнерскую ссылку на лету.
Автоматическая публикация DailyMotion в wordpress. WordPress Automatic Plugin может импортировать форму DailyMotion по ключевому слову, пользователю или списку воспроизведения с различными параметрами, такими как импорт тегов, автоматическое воспроизведение видео и многое другое.
Автоматическая публикация Reddit в WordPress. WordPress Automatic Plugin может импортировать сообщения Reddits в WordPress с возможностью фильтрации Reddits по типу, а также импортировать комментарии.
Автоматическая публикация из Walmart в WordPress. WordPress Automatic Plugin может импортировать продукты Walmart в WordPress с полной поддержкой Woo-Commerce, поэтому опубликованные элементы могут быть размещены как продукты Woo.
Автоматическая вставка рекламы. вы можете указать два рекламных места, которые будут автоматически вставляться в сообщения.
На основе кампании. , вы можете настроить неограниченное количество кампаний с разными ключевыми словами и различными опциями публикации, и эти кампании будут работать вместе для публикации на вашем сайте.
Опубликовать в определенной категории. вы можете указать, в какой категории добавлять новые сообщения в одну категорию для каждой кампании.
Запись с использованием определенного автора. , вы можете выбрать нового автора сообщения, одного автора на кампанию.
Публикуйте ключевые слова как теги. Плагин может размещать ключевые слова как теги wordpress.
Поддержка пользовательских типов сообщений. Плагин может публиковать сообщения в вашем пользовательском типе публикации, таком как продукт woo-commerce.
Ключевые слова автоматической гиперссылки.Плагин может автоматически создавать гиперссылки на указанные ключевые слова с вашей партнерской ссылкой или любой указанной ссылкой.
Автоматическая установка избранного изображения WordPress. Плагин может автоматически устанавливать избранное изображение публикации из первого изображения в содержимом публикации.
Кэшируйте изображения на свой сервер. Плагин может кэшировать изображения на сервере и изменять их ссылки на ссылку вашего сайта.
Выберите необходимые слова и словосочетания. вы можете указать слова, которые должны быть в содержании сообщения WordPress.
Исключать слова и фразы. вы можете установить слова и фразы, которых не должно быть в содержании поста WordPress.
Переведите содержимое перед публикацией. , вы можете настроить плагин на автоматический перевод контента перед публикацией с помощью Google Translate, Microsoft translator, Deepl или Yandex translate. Вы можете настроить его на перевод дважды, чтобы получить уникальный контент.
Автоматически добавлять настраиваемые поля в новые сообщения. , вы можете настроить плагин на автоматическое добавление настраиваемых полей к опубликованным сообщениям. Эти поля могут содержать любую информацию из добавленного сообщения, такую как заголовок, автор, контент, изображение, цена, рейтинг … и т. Д. Разрешенные теги перечисляются автоматически для выбора и различаются для каждого типа кампании.
Поддержка автоматического поиска и замены. Плагин может выполнять поиск в контенте перед публикацией по указанным вами словам и заменять их.
предложение ключевого слова. При вводе первых букв ключевого слова перечисляются все ключевые слова, начинающиеся с этой буквы, на выбор.
Поддержка автоматического прокрутки контента с использованием лучшего прядильщика. the best spinner (thebestspinner.com) берет статью и заменяет синонимы, используя свою базу данных синонимов, чтобы создать 100% уникальную статью.
Поддержка шаблонов сообщений. содержание сообщения может быть сформировано в различных форматах с помощью таких тегов, как [post_content], [post_title], [product_price] … и т. Д. Поддерживаемые теги различаются для каждой кампании и перечислены автоматически для выбора.
установить и забыть задание cron . для публикации каждого конкретного интервала, указанного для каждой кампании в форме (дни / часы / минуты).
Внутреннее задание cron. wordpress automatic поддерживает автоматическое размещение сообщений на основе внутреннего задания cron WordPress.
Два статуса поста. , вы можете установить статус нового сообщения: черновик или опубликованный.
Неограниченное количество ключевых слов. , вы можете добавить неограниченное количество ключевых слов для каждой кампании. когда начинается обработка кампании, эти ключевые слова будут использоваться одно за другим для получения контента, поэтому, если первое ключевое слово исчерпано или совпадений больше нет, будет использоваться второе.
Автоматическая гиперссылка по ключевым словам. автоматическая гиперссылка сопоставила ключевое слово с указанной ссылкой
Spintax включен. нравится {удивительно | красиво | полезно}. вы можете использовать эту форму в содержании поста, и только одно слово будет выбрано в финальной статье случайным образом.
Автоматическая зачистка ссылок. , чтобы удалить все ссылки из исходного содержимого перед публикацией.
Поддержка многосайтовой сети WordPress.Плагин может быть установлен в многосайтовой установке WordPress и правильно работать в каждом зомби-блоге.
Поддержка прокси . Плагин может использовать веб-прокси в форме ip: port
TrueMag / NewsTube / VideoPro, интеграция на лету. Если вы публикуете видео с Youtube / Vimeo / Instagram и используете одну из этих замечательных видеотем под названием TrueMag, VideoPro, NewsTube, то плагин знает, используете ли вы эту тему, и автоматически добавит необходимую конфигурацию для макета видео с тема.
Бесплатные обновления. для любого обновления, которое я выпускаю, вы можете загрузить автоматически, посетив страницу загрузки и повторно загрузив новые версии. Различные обновления, выпущенные с 2012 года, будут продолжать улучшать плагин.
Версия 3.53.1 (3 июля 2021 г.) - Исправлено: публикация Instagram снова на работе - Исправлено: публикации в Facebook с мероприятий теперь снова получают дату окончания. Версия 3.53.0 (28 мая 2021 г.) - НОВИНКА: возможность настройки числовых значений e.g: увеличить возвращаемую цену - Исправлено: модуль SoundCloud обновлен, чтобы снова работать после новых изменений. - Исправлено: закрепленная публикация в Facebook теперь пропускается. - Исправлено: события Facebook теперь возвращают дату - Исправлено: теперь работает опция Facebook, позволяющая пропускать общие сообщения. - Исправлено: книги Amazon теперь импортируются с более подробной информацией. - Улучшено: новый ник пользователя из отображаемого имени при создании пользователя. Версия 3.52.0 (5 апреля 2021 г.) - НОВИНКА: многостраничный скребок теперь поддерживает бесконечную прокрутку. - Исправлено: публикация сообщений в TikTok от конкретного пользователя возвращается к работе. Версия 3.51,5 (22 марта 2021 г.) - Исправлено: проблема с пустыми изображениями FB отсортирована. - Исправлено: видео FB обратно встраивать нормально - Исправлено: многостраничный скребок. Фиксированный шаблон URL следующей страницы теперь поддерживает отрицательные шаги. Версия 3.51.4 (6 марта 2021 г.) - Исправлено: eBay обновлен для поддержки нового формата ссылок. - НОВИНКА: добавлена опция безопасного поиска на Youtube. - НОВИНКА: Google Translate теперь поддерживает традиционный китайский. Версия 3.51.2 (24 февраля 2021 г.) - Исправлено: Facebook теперь сообщает, когда cookie является обязательным. - НОВИНКА: встроенное видео Reddit теперь поддерживает звук. - Исправлено: TikTok теперь может импортировать по ключевому слову в обычном режиме - Исправлено: TikTok теперь может устанавливать избранное изображение, если кеш также отключен. Версия 3.51,1 (4 февраля 2021 г.) - Исправлено: публикация сообщений в Facebook из групп теперь работает нормально. Версия 3.51.0 (31 января 2021 г.) - НОВИНКА: теперь поддерживает TikTok. - НОВИНКА: в Deepl добавлены японский и китайский языки. - НОВИНКА: опция Youtube для ограничения поиска видео с субтитрами. - Исправлено: поддержка PHP 8. - Исправлено: исправления импорта Facebook. - Исправлено: переводчик Microsfot теперь работает с любым регионом, необходимо добавить код региона. Версия 3.50.12 (18 декабря 2020 г.) - Срочное исправление: публикация Amazon без сортировки сообщения об ошибке URL _c API. - НОВИНКА: возможность ограничить время обработки для каждой кампании - НОВИНКА: опция многостраничного парсера для пропуска сообщений старше определенной даты. - НОВИНКА: тег Reddit item_nsfw возвращает да или нет - Исправлено: визуальный селектор каналов теперь работает, если используются несколько URL-адресов каналов. Версия 3.50.11 (8 декабря 2020 г.) - Важно: SoundCloud вернулся к полноценной работе. - НОВИНКА: возможность установить значения по умолчанию для тегов, которые будут возвращать пустые - НОВИНКА: возможность Facebook пропускать публикации, опубликованные из других сообщений. - НОВИНКА: контент добавляется только для поиска и замены. - Исправлено: исправление нелатинских символов в имени места в событиях Facebook. - Исправлено: Facebook теперь может получать полные сообщения из профилей. - Исправлено: исправлены ссылки на eBay Hong Kong и Singabore. - Исправлено: Reddit теперь принимает URL-адреса, содержащие параметры. - Исправлено: популярные изображения Instagram вместо недавних для серверов США. - Улучшено: сериализованные массивы в настраиваемых полях теперь могут иметь теги. Версия 3.50.10 (11 ноября 2020 г.) - НОВИНКА: фиды / многостраничная опция для пропуска следующих перенаправлений JS. - Исправлено: модуль Facebook обновлен для полноценной работы с новым пользовательским интерфейсом. - Исправлено: фиды / многостраничное исправление для относительных ссылок, когда существует базовый URL. Версия 3.50.9 (24 октября 2020 г.) - Исправлено: Facebook вернулся к частичной работе для страниц и профилей, другие функции будут работать в следующем выпуске. - Исправлено: теперь исправлен порядок случайных публикаций многостраничного парсера. - Исправлено: установка статуса ожидающей публикации, когда изображение отсутствовало, теперь работает с плагином FIFO. Версия 3.50,8 (30 сентября 2020 г.) - Исправлено: модуль eBay обновлен для работы с официальным API поиска eBay. - Исправлено: автоматический заголовок Twitter теперь не имеет ссылок, когда активна опция расширения URL. Версия 3.50.7 (14 сентября 2020 г.) - Временный патч: FB теперь работает лучше (полное описание / размеры изображений) до полной переделки. Версия 3.50.6 (2 сентября 2020 г.) - Срочно: Instagram обновлен, чтобы снова работать после недавних изменений - НОВИНКА: опция Youtube для публикации только живых видео - НОВИНКА: возможность Twitter для расширения коротких ссылок - Улучшено: исходное время подачи, если оно выше текущего, теперь игнорируется. - Исправлено: ссылка добавления в корзину Amazon теперь использует https вместо http. - Исправлено: обновлены поисковые индексы Amazon API. - Исправлено: теперь работает извлечение изображений электронных книг Amazon без API. Версия 3.50,5 (13 августа 2020 г.) - Исправлено: интерфейс теперь совместим с WordPress 5.5. Версия 3.50.4 (12 августа 2020 г.) - Исправлено: изображение Amazon с использованием API иногда не работало. - Исправлено: публикация Amazon без API теперь возвращает изображение при публикации с amazon.com.au. - Исправлено: удаление исходных ссылок из сообщения теперь оставляет встроенные ссылки в твиттере. Версия 3.50.3 (19 июля 2020 г.) - Исправлено: изображение Amazon с использованием API иногда не работало. - Исправлено: публикация Amazon без API теперь возвращает изображение при публикации с amazon.com.au. - Исправлено: при вставке исходных ссылок из сообщения теперь остаются встроенные ссылки в твиттере. - Исправлено: улучшения алгоритма перевода. - Исправлено: импорт ссылок FB со страниц RTL теперь работает. - Исправление: удален [review_iframe] из кампаний Amazon и импортированных сообщений Amazon. Версия 3.50.2 (1 июля 2020 г.) - Исправлено: флажки на странице настроек теперь сохраняются. - Исправлено: парсер для одной страницы теперь может без проблем удаляться по идентификатору / классу. - Исправлено: тег Youtube [vid_date] теперь возвращает дату с учетом часового пояса сайта. - Исправлено: тег WPML теперь добавляется к правильным языковым тегам. - Исправлено: Instagram теперь отображает ошибку, если время сеанса истекло. - Улучшено: теги Youtube в качестве тегов WordPress теперь используют официальный API. Версия 3.50.1 (24 июня 2020 г.) - Исправлено: метод автоматического определения перевода Google теперь работает нормально, он возвращал массив массива. Версия 3.50.0 (22 июня 2020 г.) - НОВИНКА: многостраничный парсер теперь может публиковать сообщения из списка URL-адресов сообщений. - НОВИНКА: опция добавления сообщений с исходным временем для многостраничного парсера. - НОВИНКА: новый тег Careerjet [source_site_name] - Исправлено: перевод Google обратно на работу - Исправлено: Facebook теперь снова импортирует до 4 изображений из сообщения. - Исправлено: GIF-файлы / видео Reddit imgur и gfycat теперь встраиваются. - Исправлено: каналы Одиночные кавычки теперь заменяются двойными кавычками. - Исправлено: Коррекция относительного пути фидов / многостраничного скребка для изображений теперь работает лучше. - Исправлено: Instagram теперь импортирует все изображения, если также включено кеширование. - Исправлено: партнерский URL-адрес Envato теперь правильно настраивается для продуктов Woo. - Исправлено: Careerjet теперь может получить полное описание - Исправлено: извлечение исходных тегов Youtube теперь снова работает. - Исправлено: Youtube, опубликованный после определенной даты, теперь снова работает. Версия 3.49,0 (14 мая 2020 г.) - НОВИНКА: поддержка фиксированного шаблона URL следующей страницы для многостраничного парсера example.com/page/[page_number] - НОВИНКА: опция ключевого слова для тега теперь может проверять только заголовок, только контент или и то, и другое. - НОВИНКА: Youtube теперь использует конечную точку API playlistitems при публикации с определенного канала, что снижает используемую квоту. - НОВИНКА: видео с Youtube в теме videopro теперь имеют продолжительность. - НОВИНКА: модуль каналов теперь может импортировать из RSS-каналов, которые не содержат тега ссылки. - НОВИНКА: кнопка на странице кампании для повторной активации всех ключевых слов сразу. - Исправлено: перевод Microsoft теперь обратно в работу + руководство обновлено до последней версии пользовательского интерфейса. - Исправлено: ленивая загрузка каналов / многостраничного парсера теперь исправляет изображения с одинарными кавычками в атрибутах src. - Исправлено: импорт Amazon без улучшения алгоритма ключа API для обхода блокировки - Исправлено: описание события Facebook теперь импортируется после недавних изменений FB. Версия 3.48,0 (1 мая 2020 г.) - НОВИНКА: тег шаблона содержимого [title_words_as_hashtags] - Исправлено: импорт Amazon без ключа API обновлен для обхода блокировки. - Исправлено: кэшированные изображения Instagram теперь имеют правильное имя, если сгенерированы из заголовка. - Исправлено: исправлен перевод Google с японского, если он содержит скобку. - Исправлено: Envato отправляет исходные теги элементов, поскольку теги теперь работают для продуктов WooCommerce. - Исправлено: опция удаления ссылок теперь не влияет на сторонние теги. - Исправлено: популярное изображение из содержимого сообщения теперь поддерживает изображения с одинарными кавычками. - Исправлено: удаление исходных ссылок из импортированного контента теперь более точное. - Исправление: некоторые исправления пользовательского интерфейса. Версия 3.47,0 (16 апреля 2020 г.) - Обновление: Amazon API обновлен до версии 5, и публикация без API вернулась к работе. - Обновление: модуль FB вернулся к публикации после недавних изменений из FB. - НОВИНКА: опция Reddit, позволяющая установить автора из исходного автора Reddit. - НОВИНКА: поиск и замена многостраничного парсера на извлеченных ссылках - НОВИНКА: добавлен метод автоопределения Яндекс переводчика - НОВИНКА: добавление атрибута запрета подписки к параметрам ссылок. - НОВИНКА: новая возможность Ezinearticles ограничивает поиск до последних лет / месяцев. - Улучшено: параметры ключевого слова для тега и ключевого слова для категории теперь могут проверять несколько ключевых слов. - Улучшено: улучшение алгоритма парсинга Amazon. - Улучшено: параметры поиска и замены / удаления с использованием REGEX теперь применяются к тегам правил. - Исправлено: добавление изображений в медиа-библиотеку теперь работает. - Исправлено: подозрительная активность FB теперь удаляет добавленную сессию. - Исправлено: теперь исправлено зависание страницы визуального селектора многостраничных / фидов при выборе ссылок. - Исправлено: атрибут Instagram [img_src] на нескольких изображениях. Опция HTML теперь возвращает локальный URL. - Исправлено: многостраничный парсер теперь может импортировать с веб-сайтов, защищенных от входа в систему, используя опцию cookie. - Исправлено: пользователи на хостинге Hetzner получали ошибку 404 при публикации кампании, теперь отсортированы Версия 3.46.12 (30 января 2020 г.) - Исправлено: SoundCloud вернулся к работе после недавних изменений из SC. - Исправлено: галерея Amazon теперь совместима с плагинами отложенной загрузки. - Исправлено: комментарии Facebook снова работают после недавних изменений из FB. Версия 3.46.11 (8 января 2020 г.) - НОВИНКА: возможность Instagram для удаления хэштегов из содержимого публикации. - Исправлено: многостраничный парсер теперь исправляет относительные ссылки, когда задан настраиваемый базовый URL. - Исправлено: Amazon попросил исправить капчу. Версия 3.46.10 (29 декабря 2019 г.) - Исправлено: SoundCloud вернулся к работе после новых изменений. - Исправлено: кеширование изображений для работы. Версия 3.46,8 (25 декабря 2019 г.) - НОВИНКА: кампания eBay теперь принимает до 3 категорий. - НОВИНКА: опция CareerJet, чтобы получить полное описание должности - НОВИНКА: опция Facebook, позволяющая публиковать сообщения владельца только при публикации из профиля. - Исправлено: цены Amazon woo на amazon.es теперь сохраняются правильно. - Исправлено: URL-адреса комментариев Youtube и изображения профиля вернулись к работе. - Исправлено: пропуск сообщений меньше определенной длины теперь более точен. - Исправлено: перевод дважды, если заголовок содержит кавычки, теперь работает + перевод тегов - Исправлено: перевод теперь правильно защищает короткие коды - Исправлено: сообщения с тегами в профиле Facebook теперь имеют правильную ссылку и правильные размеры изображений. - Исправлено: добавлен новый тег Facebook original_date_timestamp. - Исправлено: тег Facebook place_phone теперь возвращает телефон, если начинается с + - Исправлено: Twitter теперь встраивает твиты с гифками. - Исправление: теперь вернемся к работе с RSS-потоками новостей Google. Версия 3.46,7 (13 ноября 2019 г.) - Исправлено: модуль Pinterest вернулся к работе после недавних изменений. Версия 3.46.6 (3 ноября 2019 г.) - НОВИНКА: модуль Amazon теперь импортирует описание книги рядом с редакционным обзором. - НОВИНКА: каналы / многостраничный скребок теперь могут захватывать и сохранять цену как цену товара. - Исправлено: исправления пользовательского интерфейса для новой версии Chrome. - Исправлено: улучшен алгоритм автоопределения ленивой загрузки. - Исправлено: og: краткая форма изображения // теперь работает как избранное изображение - Исправлено: тег eBayhips_to теперь не содержит | - Исправлено: внешний партнерский продукт Walmart теперь добавляется с правильной ссылкой. Версия 3.46,5 (11 октября 2019 г.) - НОВИНКА: пропускать публикации, если содержание ниже определенного номера для всех типов кампаний. - НОВИНКА: добавлено автоматическое исправление ленивой загрузки ленты / многостраничного скребка. - НОВИНКА: новые теги eBay [item_seller_username], [item_location], [item_ships_to], [item_condition], [item_return_policy] и другие. - Исправлено: формат фидов / многостраничного парсера Youtube, содержащий исправление параметров. - Исправлено: публикация комментариев на Youtube при наличии нескольких ключей API для работы. - Улучшено: URL-адреса избранных изображений теперь кодируются IRI перед загрузкой Версия 3.46,4 (2 октября 2019 г.) - Улучшено: каналы / многостраничный скребок Youtube, встроенные видео, теперь изменяются в формат WordPress. - Исправлено: части лент / многостраничных полос с использованием класса / идентификатора теперь работают правильно. - Исправлено: относительные изображения атрибутов фидов / многостраничного парсера srcset теперь преобразуются в полные. - Исправлено: исправление формата продолжительности видео Youtube часы: минуты: секунды Версия 3.46.3 (1 октября 2019 г.) - НОВИНКА: новый тег фида / многостраничного парсера source_url_encoded - Улучшено: импорт Amazon без серьезных улучшений API и обновления алгоритма. - Улучшено: имя изображения из заголовка теперь удаляет смайлики. - Исправлено: пользовательское извлечение в теги теперь может извлекать несколько тегов / категорий. - Исправлено: разделитель в сохраненных описаниях контактов теперь отображается правильно. - Исправлено: извлечение / удаление фида / многостраничного скребка по классам теперь работает для PHP 7.3 Версия 3.46.2 (20 сентября 2019 г.) - Исправлено: кодировка преобразования канала теперь снова работает. - Исправлено: почта Amazon без ключей PA теперь работает - Исправлено: опция имитации адреса Amazon теперь работает правильно. - Улучшено: Amazon теперь может извлекать цены из электронных книг и т. Д. - Улучшено: поиск Amazon теперь исключает товары с нулевой ценой. - Улучшено: пользовательский интерфейс теперь сохраняет правильный порядок мета-боксов. Версия 3.46.1 (10 сентября 2019 г.) - Исправлено: теперь исправлена ошибка сеанса Facebook недействительна. - Исправлено: сообщения Facebook с изображениями теперь импортируются правильно. Версия 3.46,0 (31 августа 2019 г.) - НОВИНКА: Amazon теперь может импортировать без использования ключей PA API. - НОВИНКА: поддержка нескольких ключей API Youtube для снятия дневных ограничений. - НОВИНКА: фидит новый тег [source_domain] - НОВИНКА: новый тег Instagram для встраивания видео + новая опция, чтобы не добавлять встраивание в описание - НОВИНКА: возможность пропустить фиксированные выбранные категории, если ключевое слово для параметра категории имеет совпадения - НОВИНКА: возможность проверять заголовок только при пропуске по ключевому слову - НОВИНКА: возможность установить галерею Woo-Commerce из пользовательского извлечения - Исправлено: проблема с таблицами обновлений отсортирована. - Исправлено: пропуск публикаций старше определенной даты теперь работает для видео из плейлистов Youtube. - Исправлено: исходные категории / теги / автор многостраничного парсера теперь загружают отдельные сообщения с помощью визуального селектора. - Исправление: Walmart обновил идентификатор издателя с LinkShare до ImpactRadius. - Исправлено: слова заголовка как теги теперь работают, когда включено удаление изображения из содержимого. - Исправлено: ссылки на сообщения в группах Facebook теперь работают и на мобильных устройствах. - Исправлено: пагинация Facebook для личных профилей вернулась к работе. - Исправлено: теперь работает исходное извлечение категорий по классам. - Исправлено: настраиваемые поля, содержащие звездочки, теперь правильно сохраняются. - Улучшено: отсутствие сообщения о существовании модуля php-xml. - Улучшено: каналы / многостраничный скребок теперь могут извлекать несколько частей в одном правиле. Версия 3.45,0 (29 июня 2019 г.) - НОВИНКА: поддержка переводчика Deepl - НОВИНКА: поддержка Яндекс переводчика - НОВИНКА: каналы / извлечение многостраничного парсера для поддержки пользовательской таксономии. - НОВИНКА: возможность отключить интеграцию темы газет для видео. - НОВИНКА: опция Facebook для автоматического создания заголовка для общих ссылок. - Исправлено: количество репостов в Facebook и количество лайков возвращаются к работе. - Исправлено: сообщения Facebook с фоном теперь импортируются. - Улучшено: теперь добавляются фиды / скребок, в котором отсутствует FB встраивание JS, для правильного встраивания. - Улучшено: перевод теперь защищает предварительные теги и теги кода. - Исправлено: автоматически созданные авторы для сообщений теперь имеют роль участника для Гутенберга. - Исправлено: теперь отображаются некоторые пустые страницы, использующие визуальный селектор. - Исправлено: Reddit gyfcat снова встраивается в работу. - Исправлено: комментарии Instagram возвращаются к работе после изменений Iinstagram. Версия 3.44,0 (4 мая 2019 г.) - НОВИНКА: возможность добавить товар woo как простой товар. - НОВИНКА: опция Youtube для добавления тега заголовка во встраиваемый код. - Улучшено: Reddit gfycat лучше встраивает видео в формате mp4 с более высоким качеством. - Улучшено: извлечение следующей страницы многостраничного парсера с помощью REGEX теперь поддерживает метаформат. - Улучшено: извлечение определенной части в настраиваемое поле теперь можно использовать в содержимом публикации. - Улучшено: добавлена проверка минимальной версии MySQL. - Исправлено: Vimeo не исправляет новый контент. - Исправлено: теперь импортируется полный контент общих сообщений FB. - Исправлено: если активен, прокси теперь используются с многостраничным парсер. - Исправлено: комментарии FB теперь снова работают после изменения со стороны FB. - Исправлено: только заголовок в поиске и замена теперь работают только по заданному правилу - Исправлено: оригинальный заголовок из og: опция заголовка теперь работает правильно Версия 3.43,1 (20 марта 2019 г.) - НОВИНКА: тег для каналов с именем [redirect_url], возвращающий URL-адрес перенаправления сообщения. - НОВИНКА: исходная категория извлечения фида теперь может быть извлечена с помощью идентификатора / класса. - Исправлено: кампания Youtube теперь отправляет правильную ссылку на домен в запросах. - Исправлено: многостраничный парсер теперь исправляет короткие ссылки. - Исправлено: визуальный скребок теперь возвращает полный URL относительных ссылок. - Исправлено: теперь работает перевод содержимого между квадратными скобками. - Исправлено: теперь корректно отображать IP-ссылку на странице настроек плагина для настроек прокси. - Исправлено: теги [vid_url], [vid_id] для FB теперь работают - Исправлено: FBlike_count теперь возвращает правильное числовое значение, если содержит запятые. - Instagram: hastags как теги WP теперь корректно работают при публикации видео. Версия 3.43,0 (11 февраля 2019 г.) - НОВИНКА: интеграция с Featured image из плагина URL вместо Nelio для внешних избранных изображений. - НОВИНКА: поиск и замена нового разделителя между поиском и заменой. - НОВИНКА: опция защищенных терминов от перевода - НОВИНКА: поддержка изображений комментариев в Facebook - НОВИНКА: события Facebook, новые теги для электронной почты, телефона, количества заинтересованных и текущих - НОВИНКА: новая опция Facebook для удаления «Смотреть» и «Смотреть видео» из импортированных видео. - НОВИНКА: опция канонизации теперь поддерживает Yoast SEO. - НОВИНКА: новые возможности парсера для одной страницы для удаления нежелательного контента. - Улучшено: Facebook теперь импортирует смешанные сообщения с видео / изображениями. - Улучшено: модуль Facebook теперь импортирует записи из альбомов с временной шкалы. - Улучшено: алгоритм пагинации Facebook обновлен, чтобы соответствовать новым изменениям. - Улучшено: модуль каналов теперь пропускает проблемы проверки SSL. - Исправлено: Facebook отключил кеш, затем снова включил его, теперь возвращается на первую страницу - Исправлено: описание события Facebook теперь извлекается правильно. - Исправлено: имя комментатора Facebook теперь корректно для нелатинского языка. - Исправлено: избранные изображения с пробелами в имени файла теперь преобразуются в тире. Версия 3.42.1 (5 января 2019 г.) - Исправлено: устранена недавняя проблема в последней версии, которая затрагивала модуль парсера и каналов. Версия 3.42.0 (3 января 2019 г.) - НОВИНКА: ключевое слово для категории, новая опция для проверки заголовка - НОВИНКА: Ключевое слово для категории новая опция, чтобы не проверять контент - Исправлено: шорткод formated_date в контенте, когда существует другой шорткод, теперь работает - Исправлено: цена Craigslist теперь извлекается, даже если не последняя часть названия. - Исправлено: тег ключевого слова теперь работает для настраиваемых полей. - Исправлено: оригинальные теги Youtube в качестве тегов WP вернулись к работе. - Улучшено: загрузка изображений на сервер теперь заменяет символы с диакритическими знаками в именах файлов. Версия 3.41.0 (2 декабря 2018 г.) - Новое: возможность установить статус публикации в ожидании, если избранное изображение не было установлено. - Новое: новая опция eBay для установки изображений предметов в качестве галереи WooCommerce. - Исправлено: добавление нового пользователя теперь работает для нелатинских имен пользователей. - Исправлено: извлечение контента по классам, XPath теперь исправляет неработающие символы - Исправлено: конкретное извлечение в теги теперь не объединяет множественные извлечения. - Исправлено: изменился Facebook, из-за которого плагин не мог получить рекомендуемое изображение, теперь оно отсортировано. - Исправлено: извлечение каналов с помощью XPath теперь извлекает правильную кодировку для нелатинских сообщений. - Улучшено: кешированные и миниатюры без расширения теперь сохраняются с расширением. Версия 3.40.0 (19 октября 2018 г.) - НОВИНКА: [Beta] многостраничный парсер для импорта с любого веб-сайта без RSS-каналов. - НОВИНКА: FB комментарии новая опция, чтобы скрыть изображение комментатора. - Существенное исправление FB: новое незначительное изменение FB остановило импорт плагина, теперь отсортировано Версия 3.39.3 (6 октября 2018 г.) - НОВИНКА: добавлен новый тег Instagram для просмотров видео. - Исправлено: непредвиденная ошибка содержимого страницы Instagram отсортирована. - Исправлено: Pinterest теперь правильно разбивает страницы, справляясь со случайным сбоем Pinterest. - Исправлено: теперь Pinterest возвращает правильный заголовок из Rich pins. - Улучшено: видео в FB теперь отображаются без звука, и добавлена новая опция для их отключения. - Улучшено: проверка типа контента для избранных изображений теперь не пропускает ложные срабатывания. Версия 3.39,2 (18 сентября 2018 г.) - Улучшено: оптимизирована производительность, теперь он легче и умнее - Исправлено: пагинация Facebook вернулась к работе. - Исправлено: сообщения о продаже FB теперь импортируются правильно. - Исправлено: создание постоянных ссылок на источник теперь работает почти со всеми темами. - Исправлено: from_id из закрытых групп теперь возвращает правильный идентификатор Версия 3.39.1 (6 сентября 2018 г.) - Исправлено: основные исправления кода модуля Facebook. - Новое: добавлены новые теги событий Facebook [end_time_timestamp], [start_time_timestamp] - Новое: комментарии WordPress теперь добавляются как ответы bbPress, если bbPress использовался. - Улучшено: тег formated_date теперь работает и с настраиваемыми полями. - Улучшено: предметы с Envato теперь могут получать сообщения как продукты Woo. Версия 3.39,0 (17 августа 2018 г.) - Новое: модуль Facebook обновлен и теперь импортирует со страниц, групп и личных профилей. - Новое: добавлена опция перевода на новые языки, такие как урду, китайский и другие. - Новое: обрезка заголовка, новая опция, позволяющая пропустить добавление "..." к сгенерированному заголовку. - Новое: новая опция усечения заголовка для удаления последнего усеченного слова - Улучшено: кодировка изменения канала теперь применяется перед извлечением контента. - Улучшено: опция "Перевести" теперь переводит тег заголовка изображения. - Исправлено: URL без комментариев автора теперь работает с модулем Youtube. - Исправлено: фид, исключающий ссылки с символами в кодировке html, вызывал зацикливание. - Исправлено: код обновлен, чтобы соответствовать недавним изменениям WPML. - Исправлено: улучшено качество аватара комментариев на Youtube. - Исправлено: теги Twitter как теги WordPress теперь работают правильно, когда включен кеш. Версия 3.38,3 (22 июня 2018 г.) - Обновление: модуль Facebook обновлен, чтобы снова работать с новым приложением. - Улучшено: обновлен алгоритм модуля перевода. Версия 3.38.2 (17 июня 2018 г.) - Улучшено: обновлен алгоритм модуля перевода. - Исправлено: модуль EzineArticles теперь снова работает после недавнего обновления пользовательского поиска Google. - Исправлено: опция пропуска точного совпадения теперь обрезает установленные правила. - Исправлено: продукты Amazon со слишком большим количеством изображений теперь используют правильный URL-адрес избранного изображения.
Проверьте старый журнал изменений
Gutenberg 9.7 улучшает взаимодействие с пользователем, обновляет повторно используемые блоки и добавляет шаблоны страниц в темы FSE — WP Tavern
Гутенберг 9.7 приземлился вчера с несколькими обновлениями и улучшениями. Пользователи должны ожидать изменений в интерфейсе для вариантов блоков, преобразований и шаблонов. Многоразовые блоки работают после, казалось бы, перерыва. Разработчики также теперь могут добавлять собственные шаблоны страниц в свои блочные темы WordPress.
В этом выпуске было наименьшее количество исправлений ошибок, которые я когда-либо видел. Команда разработчиков внесла в обновление только восемь исправлений, что может свидетельствовать о том, что после 9 версии все стало более стабильным, чем обычно.6 релиз пару недель назад.
Большая часть работы в 9.7 была связана с новыми функциями и улучшениями. Как и ожидалось, полная редакция сайта получила свою долю времени. Тем не менее, даже это, похоже, немного уменьшилось для этого выпуска. Многие обновления относятся к интерфейсу постредактирования.
Улучшения взаимодействия с пользователем
Команда выпустила несколько обновлений того, как функции работают в редакторе. Некоторые из них могут показаться незначительными, но улучшают общее впечатление от редактора.
Варианты блоков получили долгожданное улучшение.Варианты — это когда один базовый блок используется для создания нескольких вариантов одного и того же блока. Например, у блока Embed есть YouTube, Twitter и другие варианты. В прошлых версиях инспектор блоков на боковой панели и навигации по блокам отображал общее имя, значок и описание. Тем не менее, Gutenberg 9.7 теперь будет показывать подробности об изменениях в использовании.
Вариант YouTube для блока Embed.
При преобразовании блока пользователи могут предварительно увидеть, как блок будет выглядеть.Это небольшое улучшение. Однако перед принятием решения о преобразовании одного блока в другой это может сэкономить несколько головных болей.
Предварительный просмотр при преобразовании блока Quote в Pullquote. В
Gutenberg 9.6 появилась функция перетаскивания блоков в устройстве вставки. Теперь команда расширила эту функцию до шаблонов блоков. Это просто еще одна ступенька лестницы для тех, кому нужны дополнительные возможности перетаскивания.
Многоразовые блоки Обновлено
Я давно не тестировал многоразовые блоки.Эта функция, похоже, отошла на второй план по сравнению с другими, более новыми функциями за последний год или около того. Он никогда не чувствовал себя намного лучше, чем первоначальный прототип. По-прежнему нет способа легко справиться с ними, если вы не знаете, где искать. Однако похоже, что команда разработчиков Gutenberg активно развивает эту почти забытую функцию.
Пользователи могут ожидать большего от будущих выпусков. «На основе этих изменений пользовательский интерфейс для многоразовых блоков, скорее всего, претерпит некоторые изменения в ближайшие недели», — написал Riad Benguella в объявлении.
Я провел первоначальный тест, чтобы увидеть, как эта функция выглядит в Gutenberg 9.7. После нажатия кнопки «Добавить в блоки многократного использования» редактор быстро промелькнул. Затем внизу экрана появилось уведомление о том, что многоразовый блок был создан. Поскольку в то время у меня не была открыта боковая панель параметров блока, я не видел возможности редактировать заголовок многоразового блока. Я сразу подумал, что команда взяла уже недоделанную функцию и сделала ее экспоненциально хуже.
При дальнейшем поиске я обнаружил, что пользователи могут редактировать заголовок многоразового блока на боковой панели параметров блока. Однако на этом команда не остановилась. Они добавили несколько улучшений в эту функцию.
Редактирование имени многоразового блока на боковой панели.
Многоразовые блоки теперь можно редактировать в самом редакторе сообщений. Например, пользователи могут перетаскивать изображение из блока. Боковая панель инспектора доступна для внутренних блоков. Многоразовые блоки теперь выглядят и ощущаются как любая другая часть редактора.Любые изменения будут отражены во всех экземплярах повторно используемых блоков на сайте.
Большая разница в том, как они сохраняются.
Сохранение многоразового блока вместе с постом.
Блоки многократного использования теперь являются частью системы сохранения «multi-entity». При нажатии кнопки обновления редактора у пользователей будет возможность сохранить всю публикацию и / или отдельные блоки многократного использования.
Пользовательские шаблоны страниц для тем FSE
Темы на основе блоков теперь поддерживают так называемые шаблоны страниц.Эта функция технически поддерживает все типы сообщений. Однако после некоторого обсуждения команда, похоже, придерживается терминологии «страницы».
Потребовалось немного покопаться, потому что нет существующей документации, а исходный пример в заявке не отражал конечный результат переданного кода. Однако мне удалось разобраться, как работает эта функция. Для авторов тем, которые хотят протестировать эту функцию, используйте следующий пример кода для добавления шаблона «контакт». Поместите его в корневой уровень экспериментальной-темы вашей темы.json файл. Вам также необходимо будет сопровождать это шаблоном block-templates / contact.html в вашей теме.
"pageTemplates": {
"контакт": {
"title": "Контакт",
"postTypes": [
"страница"
]
}
} В данный момент эта функция не делает ничего особенного. Он просто добавляет настраиваемый шаблон в раскрывающийся список на экране редактирования сообщения / страницы.Это эквивалент текущей системы шаблонов страниц, доступной для традиционных тем.
Выбор настраиваемого шаблона страницы из темы FSE.
Хотя это хорошая разработка, традиционные шаблоны страниц могут не иметь большого смысла в парадигме блочной тематики. Невозможно изменить визуальный вывод страницы в редакторе на основе выбранного шаблона — пользователи все равно должны просматривать страницу во внешнем интерфейсе, чтобы увидеть результат ее применения. Система блоков — это мгновенная визуальная обратная связь.Шаблоны страниц необходимо переосмыслить в соответствии с новой эпохой.
«Что касается пользовательского интерфейса и интеграции с режимом шаблона, мы можем сделать намного больше, чем старый блок выбора», — сказал Бенгелла, который был разработчиком запроса на вытягивание. «Мы можем показать предварительный просмотр шаблонов и предложить модальное окно или что-то в этом роде для людей на выбор… Нам потребуется некоторое дизайнерское мышление и исследования. Этот PR просто устанавливает технические требования, чтобы заставить его работать ».
Многое, но не все, для чего шаблоны страниц были необходимы в последнее десятилетие, теперь можно заменить шаблонами блоков.
В долгосрочной перспективе я бы предпочел, чтобы шаблоны страниц вели себя как предварительно разработанные макеты блоков. Вот как сегодня работают блочные шаблоны для произвольных типов записей. Однако это скорее на уровне типа поста, чем на уровне отдельного поста.
Традиционные шаблоны страниц устарели. Темы редко предлагают больше, чем несколько. Один для удаления боковой панели. Один для перемещения боковой панели влево или вправо. Другой, чтобы сделать область содержимого страницы шире.
Ясно одно: нам нужно больше исследовать, как будут выглядеть шаблоны страниц будущего.Нужны ли они в блочной системе? Есть ли лучшие способы справиться с тем, для чего они используются в традиционных темах? Как они будут работать в интерфейсе, требующем визуальной обратной связи?
Нравится:
Нравится Загрузка …
Video URL Parser Chrome Extension, Plugin, Addon Download for Google Chrome Browser
Video URL Parser chrome extension is Video URL Parser.
Этот простой плагин позволяет your to получить реальный URL-адрес видео для YouTube, YouPorn, weibo video , Miaopai, Tencent, Bilibili и Xiaokaxiu Videos.
— Поддерживается видеосайтов — 1.
Weibo. ком () 2 .
Miaopai.com 3. v.qq.com 4. youtube.com 5. bilibili.com 6. xiaokaxiu.com 7. youporn.com Однако этот мощный инструмент не ограничивается указанными выше видео-сайтами.
Вы можете использовать этот инструмент для анализа полезных загружаемых ресурсов (видео, аудио, изображения), но нет гарантии успеха.
.
YoutubeYoupornURL — серверов api — Это расширение требует подключения к одному из следующих серверов api .
1. helloacm.com (Великобритания) 2. happyukgo.com (Сингапур) api 1 .
helloacm.com () 2. happyukgo.com () — « api в настоящее время недоступно» — Если вы видели эту ошибку, это означает, что серверы API (helloacm.com или happyukgo.com) являются недоступен.
Повторите попытку позже.
«API в настоящее время недоступен» API helloacm.com happyukgo.com — История версий —- 1.1 13 ноября 2016 Очистка кода и улучшения 1.0 12 ноября 2016 купите мне кофе через https : // www.paypal.me/doctorlai/5 0.9 12-ноя-2016 Теперь он запоминает настройки сервера.
0,8 11-ноя- 2016 незначительное улучшение js 0 .7 09-ноя-2016 Добавьте сервер резервного копирования, и позволит выбрать серверы api из Великобритании или Сингапура.
0,6 03-ноя- 2016 добавлен текст : убедитесь, что у вас есть доступ к серверу API https: // helloacm. com 0 .5 02-ноя- 2016 изображение кнопки 0 .4 02-ноя-2016 Загрузка анимации Gif 0.3 02-ноя-2016 Bootstrap & Icon 0.2 01-ноя- 2016 мелкие исправления 0 .1 01 ноября 2016 г. Первый выпуск — Свяжитесь со мной —- web : https://weibomiaopai.com Электронная почта: [адрес электронной почты защищен] — Купите мне кофе, — https: // www .paypal.me / doctorlai / 5 биткойнов: 1J88t5UAgKBHhMgzkyH9bpY5mPdCYAe5XQ ()
Video URL Parser Расширение Chrome Скачать
Это ссылка для загрузки расширения Google Chrome для парсера URL видео, которую вы можете загрузить и установить браузер Google Chrome.
Скачать расширение Chrome для парсера URL видео (CRX)
Теги:
простой плагин позволяет, незначительное улучшение js, производительность, расширение chrome парсера URL, мелкие исправления nov, URL видео, сервер api https helloacm, https weibomiaopai, очистка кода nov, полезные загружаемые ресурсы, серверы api helloacm, доступ к серверу api https, серверы api , nov контактная информация о первом выпуске, загрузка, https, api,
4 способа публикации в WordPress по электронной почте
Возможность отправлять сообщения в WordPress по электронной почте существует уже давно.Однако с развитием мобильных технологий публикация сообщений по электронной почте стала более актуальной, чем когда-либо прежде, особенно для людей, находящихся в пути.
Независимо от того, ведете ли вы новостной сайт или блог с ежедневными обновлениями, магазин электронной коммерции, ресторан или какой-либо другой бизнес, составлять и отправлять электронные письма с мобильного устройства и размещать их в WordPress по электронной почте, вероятно, будет намного проще, чем делать это. это через вашу панель управления.
Вы можете быть удивлены, насколько легко отправлять сообщения по электронной почте на ваш сайт.Вот несколько различных вариантов, которые позволят вам публиковать контент на ходу:
Плагин
WordPress: Postie
Postie — это удобный плагин для публикации в WordPress по электронной почте.
Postie предлагает множество расширенных функций для публикации в вашем блоге по электронной почте, включая возможность назначать категории по имени, включенным изображениям и видео, а также автоматически удалять подписи. Если вы установите для Postie предпочтение HTML-сообщений, вы сможете получать встроенные изображения для своих сообщений. URL-адреса видео Youtube или Vimeo в теле письма будут автоматически преобразованы во встроенные видео.
Многие плагины post-by-email пришли и ушли, но Postie, похоже, стал популярным плагином для создания сообщений в WordPress из электронных писем.
Плагин
WordPress: используйте Jetpack и мобильное приложение WordPress
Один из вариантов публикации по электронной почте — установить плагин Jetpack на свой сайт и загрузить мобильное приложение WordPress на свой телефон.
Мобильное приложение WordPress позволяет размещать сообщения на своем сайте или в блоге WordPress с телефонов iOS и Android через Jetpack. Функция отправки сообщений по электронной почте
Jetpack легко интегрируется с мобильным приложением WordPress.Jetpack требуется уникальный адрес электронной почты для отправки сообщений с по (не с на ). Чтобы включить функцию «Публикация по электронной почте», перейдите в раздел «Администратор WP » вашего сайта> Jetpack> Настройки> Написание> Публикация сообщений, отправив сообщение электронной почты .
После установки и настройки приложения просто введите адрес электронной почты в стандартном мобильном приложении электронной почты или почтовом клиенте, таком как Gmail, Outlook или Apple Mail, отправьте его на свой уникальный адрес, и Jetpack опубликует его на вашем сайте.
Программная автоматизация: используйте Zapier и создайте Zap
Zapier предоставляет вам электронную почту для интеграции WordPress и многих других процессов автоматизации.
Zapier — это мощный, простой в использовании и действительно крутой сервис, который позволяет вам соединять вместе сотни различных программных приложений, чтобы автоматизировать многие трудоемкие процессы и сэкономить массу времени и продуктивные часы. Основная идея, лежащая в основе работы Zapier, заключается в том, что вы связываете «это программное обеспечение» с «этим программным обеспечением», чтобы, когда «это происходит» (называемое «триггером»), «это происходит» (называемое «действием»). Каждое создаваемое вами соединение называется «Zap», и вы можете создавать Zap-файлы между всеми различными типами программ, поддерживаемых Zapier.
После того, как вы настроите свою учетную запись Zapier (вы можете начать с бесплатной пробной версии и бесплатного плана) и узнаете, как использовать службу (в Интернете есть множество руководств), вы можете легко интегрировать свой любимый почтовый клиент с WordPress.
Например, вы можете подключить свою учетную запись Gmail к своему сайту WordPress и создать «Zap» (т. Е. Соединение), чтобы при создании нового электронного письма в Gmail создавалась запись в WordPress.
Zapier позволяет превратить электронное письмо, отправленное из Gmail, в сообщение WordPress.
Или, если вы предпочитаете вместо этого использовать Microsoft Outlook, вы можете создать «Zap», который преобразует электронное письмо, отправленное из вашей учетной записи Outlook, в сообщение WordPress.
Или используйте Zapier для отправки писем из Outlook в WordPress.
Существует ряд других интеграций электронной почты, которые вы можете сделать, чтобы настроить рассылку сообщений по электронной почте с помощью Zapier.
Совет: Если вам нужно извлечь определенные типы данных из ваших писем для интеграции с другими приложениями, обратите внимание на инструмент парсера электронной почты Zapier.
Email Parser от Zapier позволяет расширить интеграцию электронной почты.
Email Parser позволяет отправлять данные через Zapier, что иначе было бы невозможно. Он берет кусочки из электронного письма, так что вы можете использовать его в Zap.
Инструмент парсера электронной почты Zapier позволяет вам выбирать, какие части электронного письма вы хотите отправить в качестве данных в другие приложения.
Поэкспериментируйте с Zapier, и вы откроете для себя множество других способов автоматизировать свои процессы. Как говорит Ронни Берт, наш главный коммерческий директор, : «Zapier — это необычно, но работает!»
Используйте встроенную функцию WordPress: но есть ловушка
WordPress имеет встроенную функцию, которая позволяет вам настроить публикацию по электронной почте, но эта функция теперь устарела и будет удалена в некоторых будущих версиях.В Кодексе WordPress есть руководство под названием «Публикация сообщений в блоге по электронной почте», в котором описаны шаги, необходимые для настройки отправки сообщений по электронной почте. Если вы перейдете в Панель управления > Настройки> Запись , вы найдете инструкции по настройке учетной записи электронной почты с доступом по протоколу POP3 для использования WordPress при публикации.
Как отправлять сообщения по электронной почте: краткое описание
Мы рекомендуем избегать встроенной в WordPress функции отправки сообщений по электронной почте, поскольку вскоре она может быть полностью удалена. Даже сам WordPress рекомендует использовать плагин для создания сообщений WordPress из писем.
Вместо этого мы рекомендуем загрузить плагин Postie и использовать его для настройки сообщений по электронной почте. В качестве альтернативы вы можете использовать мобильное приложение WordPress с функцией отправки сообщений Jetpack по электронной почте или узнать, как использовать Zapier и создать Zap, который автоматизирует этот процесс для вас. Все эти варианты позволят вам размещать контент на своем сайте WordPress на ходу.
Бесплатное видео
Почему 100 НЕ является идеальным показателем скорости загрузки страницы в Google (* 5 минут просмотра)
Узнайте, как использовать Google PageSpeed Insights, чтобы ставить реалистичные цели, повышать скорость работы сайта и почему стремиться к 100 баллам — НЕПРАВИЛЬНАЯ цель.
Теги:
WordPress-Plugin JSON Content Importer — WordPress-плагин JSON Content Importer
Подключите свой веб-сайт к JSON-API:
Получите JSON, обработайте его с помощью шаблона и отобразите liveata на своем сайте WordPress!
Плагин анализирует практически любой канал JSON и позволяет отображать все данные на вашем веб-сайте: Импортируйте данные из API / веб-сервиса, чтобы отобразить их на вашем веб-сайте.
Преимущества:
- Повышайте интерес пользователей, клиентов и поклонников, предоставляя обновленные и актуальные данные каждый раз, когда они посещают ваш сайт
- Сэкономьте время, используя JSON Content Importer для отображения динамического контента, доступного для сканирования поисковой системой, в оформлении, соответствующем вашему веб-сайту, и улучшите свой SEO
Прочтите, что говорят пользователи
Совместим ли определенный API?
Если у вас есть фокус на API, вы спрашиваете себя: поможет ли этот плагин с использованием этого специального API?
Ответ: Может быть, это зависит… 😉
Сложные приложения могут быть созданы с помощью PRO-версии плагина и API:
Это помогает:
Взгляните на страницу поддержки этого подключаемого модуля с растущей коллекцией API-интерфейсов и типичных API-ситуаций.
А:
Free и PRO-Plugin (сравните оба):
Этот веб-сайт поддерживает как бесплатную, так и PRO-версию и показывает, как запускать обе версии.
Не стесняйтесь размещать отличные данные на своем веб-сайте, не тратя ни цента, и свободно используйте бесплатный плагин для личных или коммерческих проектов без каких-либо условий.
Я не требую указания авторства для бесплатной версии, но это всегда приветствуется 😉
Если вам нравится плагин, вы также можете сделать пожертвование — чего бы оно вам ни стоило.Спасибо за то, что используете мой плагин и оценили его по достоинству!
Бесплатный плагин:
Версия: 1.3.12
172455 Загрузки
55 Рейтинги: 98%
Бесплатные функции:
- Простой в использовании, не требующий кода
- Настраиваемый: используйте шаблон, чтобы выглядеть так, как вам нравится
- Содержимое канала JSON может сканироваться поисковыми системами, что повышает SEO-ценность вашего сайта
- Встраивайте каналы с помощью шорткода на свою страницу, в публикацию или виджет в любом месте вашего веб-сайта
- Debug-Mode: просто добавьте debugmode = 10 в другую короткую ссылку и посмотрите, что происходит
- Кэшировать JSON-канал: получить один раз, использовать много раз
- e.g .: Показать события из канала JSON с именем, датой / временем, местом и описанием
Скачать бесплатную версию плагина
Плагин PRO: все бесплатные функции плюс…
- поддержка и постоянная разработка
- обработка более широкого диапазона JSON-каналов / API
- : собственный движок плагинов лучше, знаменитый механизм twig — альтернатива PRO
- template-manager: хранить шаблоны независимо от страниц
- отображать как виджет на боковой панели или нижнем колонтитуле
- сборка приложений: выбор JSON-канала на лету
- создать WordPress-страницы
- сторонние шорткоды работают внутри шорткода jsoncontentimporter
- , но: вы должны приобрести лицензию, которая должна обновляться ежегодно — лицензии до 30 декабря 2017 г. действительны без ограничений по времени
- без риска: полный возврат в течение 14 дней после покупки — без вопросов
- и многое другое…
Улучшенный механизм шаблонов
Пример:
Приведенные выше цифры для версии, загрузок и рейтинга являются живыми данными WordPress.org API — шорткод с бесплатной версией выглядит следующим образом:
[jsoncontentimporter url = ”https://api.wordpress.org/plugins/info/1.0/json-content-importer.json”] Версия: {версия}, {загружено} Загрузки, {num_ratings} Рейтинги: {rating}% [/ jsoncontentimporter]
api.json-content-importer.com содержит намного больше примеров
Видео
— парсер youtube не обновляет видео
— синтаксический анализатор youtube не обновляется — Ask Ubuntu
Сеть обмена стеков
Сеть Stack Exchange состоит из 177 сообществ вопросов и ответов, включая Stack Overflow, крупнейшее и пользующееся наибольшим доверием онлайн-сообщество, где разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Посетить Stack Exchange
0
+0
- Авторизоваться
Зарегистрироваться
Ask Ubuntu — это сайт вопросов и ответов для пользователей и разработчиков Ubuntu.Регистрация займет всего минуту.
Зарегистрируйтесь, чтобы присоединиться к этому сообществу
Кто угодно может задать вопрос
Кто угодно может ответить
Лучшие ответы голосуются и поднимаются наверх
Спросил
Просмотрено
459 раз
Все, что я вижу здесь по этой теме, датировано 5 или более годами.Запуск ubuntu 18.04 и youtube.lua не существует, когда я запускаю парсер для его обновления. Я загрузил 3 видео, а затем vlc перестал воспроизводить или скачивать
hines @ hines-Vostro-260: ~ $ sudo apt-get install curl
Чтение списков пакетов ... Готово
Построение дерева зависимостей
Чтение информации о состоянии ... Готово
curl - это уже самая новая версия (7.58.0-2ubuntu3.8).
0 обновлено, 0 установлено заново, 0 удалено и 3 не обновлено.
hines @ hines-Vostro-260: ~ $ sudo rm / usr / lib / vlc / lua / плейлист / youtube
rm: невозможно удалить '/ usr / lib / vlc / lua / playlist / youtube': нет такого файла или каталога
hines @ hines-Vostro-260: ~ $ sudo curl "http: // git.videolan.org/p=vlc.git;a=blob_plain;f=share/lua/playlist/youtube.lua;hb=HEAD "-o /usr/lib/vlc/lua/playlist/youtube.lua
% Всего% Получено% Xferd Средняя скорость Время Время Время Текущее
Выгрузка Всего израсходовано Оставшаяся скорость
0 0 0 0 0 0 0 0 -: -: - -: -: - -: -: - 0 Предупреждение: не удалось создать файл / usr / lib / vlc / lua / playlist / youtube.lua: Нет
Предупреждение: такой файл или каталог
100 153 100 153 0 0 320 0 -: -: - -: -: - -: -: - 320
curl: (23) Ошибка записи тела (0! = 153)
Пилот6
76.1k7070 золотых знаков168168 серебряных знаков266266 бронзовых знаков
Создан 14 июн.
2
Пути изменились. Вот что я сделал.
Получите последний файл с github VLC, например:
wget https: // raw.githubusercontent.com/videolan/vlc/master/share/lua/playlist/youtube.luaЗатем скопируйте его туда, где сейчас находятся эти файлы:
sudo cp youtube.lua / usr / lib / x86_64-linux-gnu / vlc / lua / список воспроизведенияЕсли вы не уверены в расположении в вашем дистрибутиве (например, это может быть другая архитектура), вы можете сделать:
$ dpkg -L vlc-plugin-base | grep youtube.lua /usr/lib/x86_64-linux-gnu/vlc/lua/playlist/youtube.luac
Обратите внимание, что вы можете найти YouTube .luac (не .lua ), но .lua , который вы собираетесь скопировать, будет иметь приоритет. Вы можете удалить youtube.luac , если хотите.
Создан 14 июн.
Эдуардо ТрапаниЭдуардо Трапани
105011 золотой знак44 серебряных знака1010 бронзовых знаков
9
Спросите Ubuntu лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie
Настроить параметры
Исправление и анализ содержимого WordPress Rest Api в React.
Разбор Html, возвращенный Api в React
Во время экспериментов с React и WordPress Rest Api, одна вещь, которая была не такой простой, как я думал, заключалась в отображении содержимого поста из Api.Похоже, React не очень любит необработанный Html и разметку, созданную некоторыми блоками.
В моем случае я пытался преобразовать свой собственный веб-сайт в приложение React. На своем сайте я активно использую блок Github Gist от CoBlocks для отображения блоков кода. Эти блоки добавляют теги скриптов к моему контенту, которые обрабатываются React, но не оцениваются. В результате отсутствуют блоки кода.
Мне потребовалось немного погуглить, чтобы найти работоспособное решение этой проблемы. Итак, в этой статье я хочу поделиться с вами тем, что я обнаружил, собрав вместе небольшое приложение, которое отображает содержимое этого сообщения в блоге, что довольно парадоксально, если вы думаете об этом: p
Обратите внимание, что я сосредоточусь на моем Github Основная проблема, но вы можете использовать технику, описанную в этой статье, чтобы исправить и другие (блокировать) проблемы с контентом.
Я установил здесь CodeSandBox с рабочим примером, который вы можете использовать.
Получение содержимого сообщения из WordPress Rest Api.
Для начала нам нужно получить данные поста из Api.
В приведенном выше фрагменте кода мы сначала используем хук useState для создания некоторого локального состояния для хранения нашего сообщения и функцию setPost для изменения этого состояния, когда мы получаем данные от Api.
Затем мы используем хук useEffect для запуска, когда наш компонент монтируется, и выполняем axios .get для получения содержимого этого сообщения. Когда ответ возвращается, мы используем нашу функцию setPost для сохранения данных в состоянии post .
Наконец, мы визуализируем div с тегом h2, содержащим заголовок сообщения, а затем div, содержащий содержимое сообщения.
На этом последнем шаге мы видим проблему, с которой столкнулись. Такая реакция не позволяет нам просто отображать простой HTML в нашем компоненте. Таким образом, мы должны визуализировать элемент и установить атрибут dangerousSetInnerHTML , передав ему наш контент.
Использование dangerousSetInnerHTML отобразит наш html. Но у меня все еще оставалась проблема с блокировкой Github Gist.
Разбор HTML-кода на элементы React.
После небольшого поиска в Google я наткнулся на пакет Html-react-parser , который преобразует строку HTML в один или несколько элементов React.
В измененном коде выше мы импортируем функцию parse из пакета Html-react-parser . И в строке 15 мы заменяем dangerousSetInnerHTML вызовом функции Parse , передавая ей содержимое нашего сообщения Api.
Хотя этот код намного приятнее для глаз, он все же не решил мою проблему Github Gist. Но при чтении Html-react-parser у меня возникла небольшая эврика.
Замена элементов пользовательскими компонентами
Функция Parse преобразует элементы Html в элементы React, но также позволяет нам самостоятельно заменять определенные элементы на определенные компоненты React.
Чтобы упростить задачу, мы создаем новый компонент React под названием WpApiContent с приведенным выше кодом.Помимо React, мы также снова импортируем функцию Parse и компонент Gist из пакета Super-react-gist , который будет отображать и выполнять сценарии Gist.
В нашем новом компоненте мы просто возвращаем результат функции Parse, но передаем Parse второй аргумент, являющийся объектом настроек. Для настроек мы устанавливаем клавишу «replace» и устанавливаем ее на функцию стрелки, которая принимает domNode и вызывается для каждого элемента dom, с которым сталкивается функция pare.
Внутри этой функции мы проверяем, является ли имя узла script и содержит ли атрибут src этого сценария строку «gist.github.com». С помощью этих проверок мы можем быть уверены, что текущий узел является скриптом Github Gist.
Если узел проходит проверку, мы возвращаем компонент Gist , устанавливающий для атрибута url prop значение атрибута scripts src . Нам нужно только удалить часть .js из URL-адреса, потому что компонент Gist этого не ожидает и не работает, если мы этого не делаем.Поэтому мы используем метод Replace Javascript для замены части .js пустой строкой.
Визуализация компонента WpApiContent
Теперь нам просто нужно начать использовать наш новый компонент WpApiContent в нашем маленьком приложении.
Вернувшись в наш компонент App , мы удаляем импорт пакета Parse и заменяем его импортом нашего нового компонента WpApiContent . Затем в строке 15 мы также заменяем вызов функции Parse на компонент WpApiContent с опорой content , передающей ему содержимое post .
Все это теперь должно приводить к правильно проанализированному контенту, поступающему из WordPress Rest Api.
ПРИМЕЧАНИЕ. Этот метод не учитывает проблемы Xss. Но поскольку мы полностью контролируем HTML-код, поступающий с нашего сайта WordPress, это должно вызвать какие-либо проблемы. Если вы действительно хотите решить эти проблемы, вы можете взглянуть на пакет DomPurify.
Завершенный код
Ниже вы найдете заполненный код для компонента WpApiContent и приложения.Я также установил здесь CodeSandBox с рабочим примером, на который вы можете ссылаться.
Компонент W pApiContent
T Компонент приложения.
Комментарии?
Если вы хотите оставить комментарий, сделайте это под копией этой статьи на Dev.to, чтобы я мог вернуться к вам.
Давайте подключимся к twitter @ Vanaf1979 или Dev.to @ Vanaf1979 , чтобы я мог уведомлять вас о новых статьях и других ресурсах, связанных с разработкой WordPress.